本文源码基于luminous-12.2.5版本分析
最近在分析H版本librbd client无法兼容L版本Ceph集群的问题,提前说明下最终结论是H版本被之前的同时修改过才导致的不兼容,官方版本应该是兼容的。这篇文章正是问题分析过程的一次整理总结。
需求描述
需求是想要在同一个OpenStack环境中同时使用H、L版本两个Ceph集群做云主机系统盘、云硬盘存储系统,因此计算节点(也即librbd client节点)就可能分为H、L两个版本,众所周知,升级librbd动态库,需要重启云主机才能生效(除非对librbd做过较大的改动),重启所有云主机这个操作用户显然是不能接受的(当然也可以执行热迁移操作,但大批量的热迁移也存在耗时长、风险大的问题,况且还有部分云主机不支持热迁移),因此如果要上线L版本集群就必须做到兼容H版本client,这样才能保证L版本集群的卷能被当前正使用H版本client的云主机挂载、读写。H版本是之前遗留的,不能升级到L版本(主要考虑2个问题,1是风险高,二是代价大。实际上还有一个小问题就是H版本client不兼容L版本server,这个正是我本次需要解决的问题)。
问题描述
|
1 |
2018-10-12 15:37:50.117973 7f58f4298700 0 -- 10.182.2.32:0/3576177365 10.185.0.97:6789/0 pipe(0x7f58e0000c80 sd=3 :34392 s=1 pgs=0 cs=0 l=1 c=0x7f58e0005160).connect protocol feature mismatch, my 883ffffffffffff peer c81dff8eea4fffb missing 400000000000000 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
void buffer::list::iterator::copy(unsigned len, char *dest) { if (p == ls->end()) seek(off); while (len > 0) { if (p == ls->end()) throw end_of_buffer(); // 这里抛异常 assert(p->length() > 0); unsigned howmuch = p->length() - p_off; if (len < howmuch) howmuch = len; p->copy_out(p_off, howmuch, dest); dest += howmuch; len -= howmuch; advance(howmuch); } } |
本次重点分析第二个问题,bt查看调用栈(调试的是rbd ls命令):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Thread 6 "rbd" hit Breakpoint 4, ceph::buffer::list::iterator::copy (this=0x7fffee122800, len=4, dest=0x7fffee1225dc "I]\026\022") at common/buffer.cc:936 936 if (p == ls->end()) seek(off); (gdb) bt #0 ceph::buffer::list::iterator::copy (this=0x7fffee122800, len=4, dest=0x7fffee1225dc "I]\026\022") at common/buffer.cc:936 #1 0x00007ffff2824284 in decode_raw<ceph_le32> (t=..., p=...) at ./include/encoding.h:57 #2 0x00007ffff281c2da in decode (v=@0x555557d350a0: 0, p=...) at ./include/encoding.h:103 #3 0x00007ffff281d023 in utime_t::decode (this=0x555557d350a0, p=...) at ./include/utime.h:103 #4 0x00007ffff281d060 in decode (c=..., p=...) at ./include/utime.h:312 #5 0x00007ffff2a1fd49 in MonMap::decode (this=0x555557d35050, p=...) at mon/MonMap.cc:74 #6 0x00007ffff2a151fd in decode (c=..., p=...) at ./mon/MonMap.h:240 #7 0x00007ffff2a0c050 in MonClient::handle_monmap (this=0x555557d35040, m=0x7fffd8000bd0) at mon/MonClient.cc:317 #8 0x00007ffff2a0bd09 in MonClient::ms_dispatch (this=0x555557d35040, m=0x7fffd8000bd0) at mon/MonClient.cc:274 #9 0x00007ffff2b9c9db in Messenger::ms_deliver_dispatch (this=0x555557d35a80, m=0x7fffd8000bd0) at ./msg/Messenger.h:582 #10 0x00007ffff2b9be57 in DispatchQueue::entry (this=0x555557d35c70) at msg/simple/DispatchQueue.cc:185 #11 0x00007ffff2bcd560 in DispatchQueue::DispatchThread::entry (this=0x555557d35e10) at msg/simple/DispatchQueue.h:103 #12 0x00007ffff296608c in Thread::entry_wrapper (this=0x555557d35e10) at common/Thread.cc:61 #13 0x00007ffff2965ffe in Thread::_entry_func (arg=0x555557d35e10) at common/Thread.cc:45 #14 0x00007ffff2335494 in start_thread (arg=0x7fffee123700) at pthread_create.c:333 #15 0x00007ffff0c45acf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 |
是在接收到服务端monmap消息后decode过程中抛的异常,具体是在decode created字段出错的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
void MonMap::decode(bufferlist::iterator &p) { DECODE_START_LEGACY_COMPAT_LEN_16(3, 3, 3, p); ::decode_raw(fsid, p); ::decode(epoch, p); // 这里正常decode if (struct_v == 1) { vector<entity_inst_t> mon_inst; ::decode(mon_inst, p); for (unsigned i = 0; i < mon_inst.size(); i++) { char n[2]; n[0] = '0' + i; n[1] = 0; string name = n; mon_addr[name] = mon_inst[i].addr; } } else { ::decode(mon_addr, p); // 这里开始出错 } ::decode(last_changed, p); ::decode(created, p); // 这里抛的异常 DECODE_FINISH(p); calc_ranks(); } |
单步调试发现,在此之前last_changed字段decode出来就是空的,时间都是0,因此怀疑是更早之前就发生错误了,调试后发现最初的错误是在decode mon_addr时就发生了。
通过调试服务端ceph-mon encode过程,发现mon_addr和last_changed、created字段都是被添加到monmap消息体内的,并且通过调试L版本client,这几个字段也都能正常decode出来,因此确认是客户端问题或者服务端发送的monmap消息客户端不兼容。但看了下L版本服务端encode代码,当前版本是v5,并且最低兼容v3版本,而H版本decode是v3版本,也就是说社区代码在设计上兼容性应该是没问题的。因此需要继续分析问题出在哪里。
仔细对比了mon_addr的decode和encode流程(主要是H版本和L版本的差异),发现L版本encode过程检查连接的features,并走了不同的encode过程。因此问题聚焦在了客户端和服务端协商features过程上。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
void encode(bufferlist& bl, uint64_t features) const { if ((features & CEPH_FEATURE_MSG_ADDR2) == 0) { // 检查features 59标记位 ::encode((__u32)0, bl); // 老版本编码流程 ::encode(nonce, bl); sockaddr_storage ss = get_sockaddr_storage(); #if defined(__linux__) || defined(DARWIN) || defined(__FreeBSD__) ::encode(ss, bl); #else ceph_sockaddr_storage wireaddr; ::memset(&wireaddr, '\0', sizeof(wireaddr)); unsigned copysize = MIN(sizeof(wireaddr), sizeof(ss)); // ceph_sockaddr_storage is in host byte order ::memcpy(&wireaddr, &ss, copysize); ::encode(wireaddr, bl); #endif return; } ::encode((__u8)1, bl); // 新版本编码流程 ENCODE_START(1, 1, bl); ::encode(type, bl); ::encode(nonce, bl); __u32 elen = get_sockaddr_len(); ::encode(elen, bl); if (elen) { bl.append((char*)get_sockaddr(), elen); } ENCODE_FINISH(bl); } |
也就是features的第59位是怎么设置上的(1<<59),看了下H版本的代码,发现了这个feature:
|
1 2 3 4 5 6 7 8 9 |
#define CEPH_FEATURE_MON_METADATA (1ULL<<50) /* ... */ #define CEPH_FEATURE_HAMMER_0_94_4 (1ULL<<55) #define CEPH_OSD_PARTIAL_RECOVERY (1ULL<<59) /* recover partial extents for objects */ #define CEPH_FEATURE_RESERVED2 (1ULL<<61) /* slow down, we are almost out... */ #define CEPH_FEATURE_RESERVED (1ULL<<62) /* DO NOT USE THIS ... last bit! */ #define CEPH_FEATURE_RESERVED_BROKEN (1ULL<<63) /* DO NOT USE THIS; see below */ |
按道理在CEPH_FEATURE_HAMMER_0_94_4(1<<55)之后应该不会再有其他feature了才对,但这个CEPH_OSD_PARTIAL_RECOVERY为啥被加入了?去看了下官方代码,发现没有这个feature,然后git log看了下我们的代码仓库,果然是我们自己人加上的。至此问题原因已经清晰。
L版本中用CEPH_FEATURE_MSG_ADDR2(1<<59)来标记是否为新版本消息,这一位是0表示是老版本(未设置该bit表示老版本),但是H版本里面正好用到了这一位CEPH_OSD_PARTIAL_RECOVERY(1<<59),导致L版本服务端检测失败,误认为是新版本客户端,使用了新的编码方式对monmap中的monitor地址信息进行编码,导致客户端无法解码。
改动方案:
此次问题分析的难点主要是:
- 不熟悉ceph源码,尤其是消息编解码过程
- 编译的第一个环境没有去掉编译优化(-O2),增加debug等级(-g),改成(-O0 -g3 -gdwarf-4)修改之后调试起来就很方便了,https://www-zeuthen.desy.de/unix/unixguide/infohtml/gdb/Inline-Functions.html
- 确定服务端是否把monitor地址信息编码到消息体过程被wireshark误导了一段时间
使用tcpdump+wireshark解析Ceph网络包
记得之前在通读docs.ceph.com上的文档时(http://docs.ceph.com/docs/luminous/dev/wireshark/),有提到过wireshark支持对Ceph网络数据包进行解析,于是试着用tcpdump抓了monitor和client的数据包,然后导入到wireshark进行解析,对H版本来说确实好用,但对L版本来说,monmap解析貌似支持不太好,monitor address地址解析不出来,估计也是只支持低版本的编码协议。参考:https://www.wireshark.org/docs/dfref/c/ceph.html
tcpdump命令(在client节点执行数据包比较少,服务端对接的客户端比较多因此数据包也比较多,当然也可以加入更多的过滤条件来精确抓包):tcpdump -i eth0 host 192.168.0.2 and port 6789 -w ceph.cap
之后把抓到的ceph.cap数据导入到windows系统的wireshark软件中,我下载的是2.6.2版本(官网有2.6.4版本,但是下载困难,就在国内找了软件站下载了2.6.2的)。导入之后就可以自动分析出结果了。
L版本抓包结果(monmap包解析不太好,认为包有问题“malformed packet”,monitor地址信息解析失败,跟我遇到的问题一样,因此误导了我2天,我一直认为服务端就是没有把地址编码进来,客户端才解析不出来,最后在服务端和客户端分别单步调试才发现是编码进去了的):
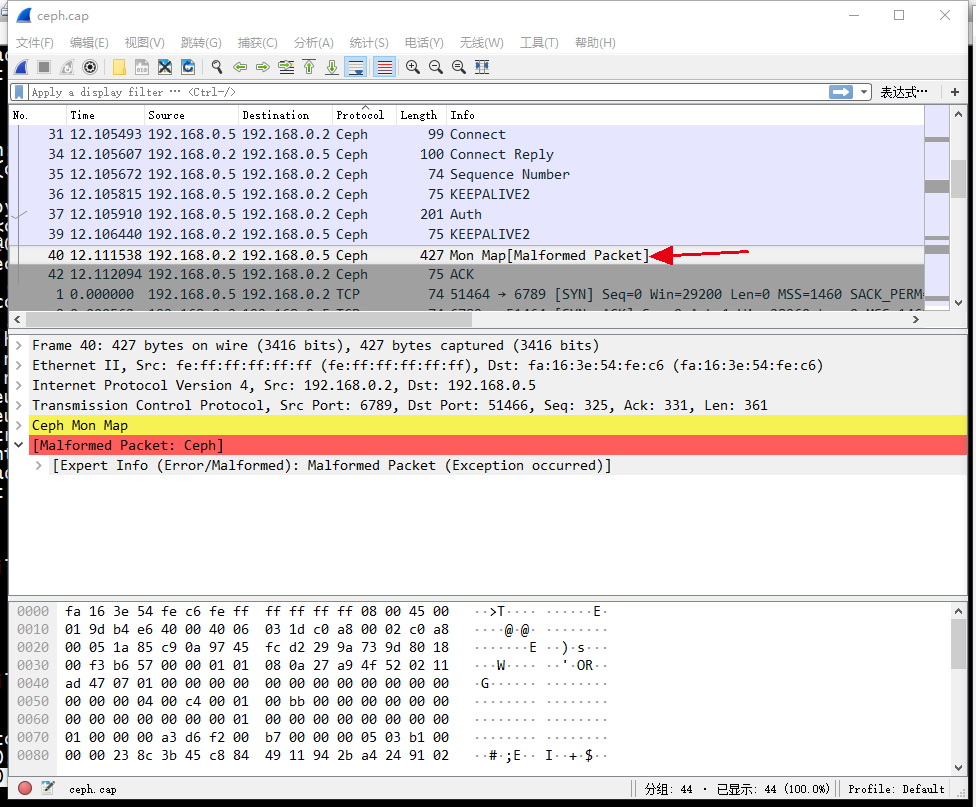
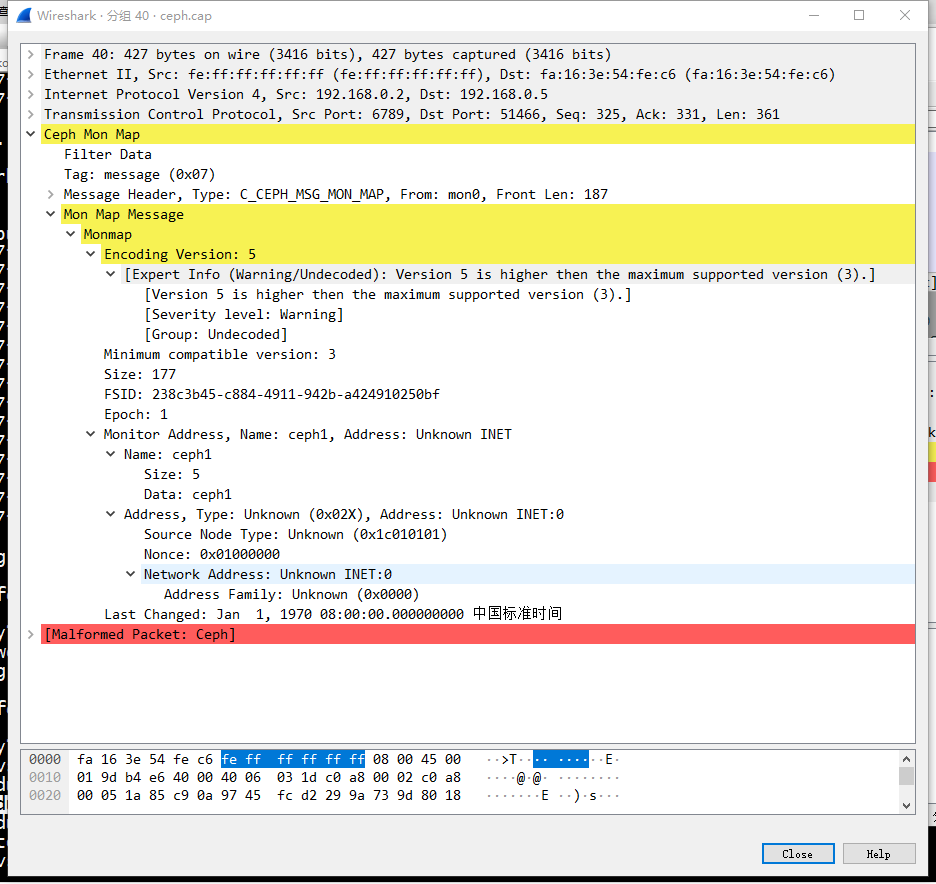
H版本数据包解析就比较完美了:
Mon Map:

OSD Map:
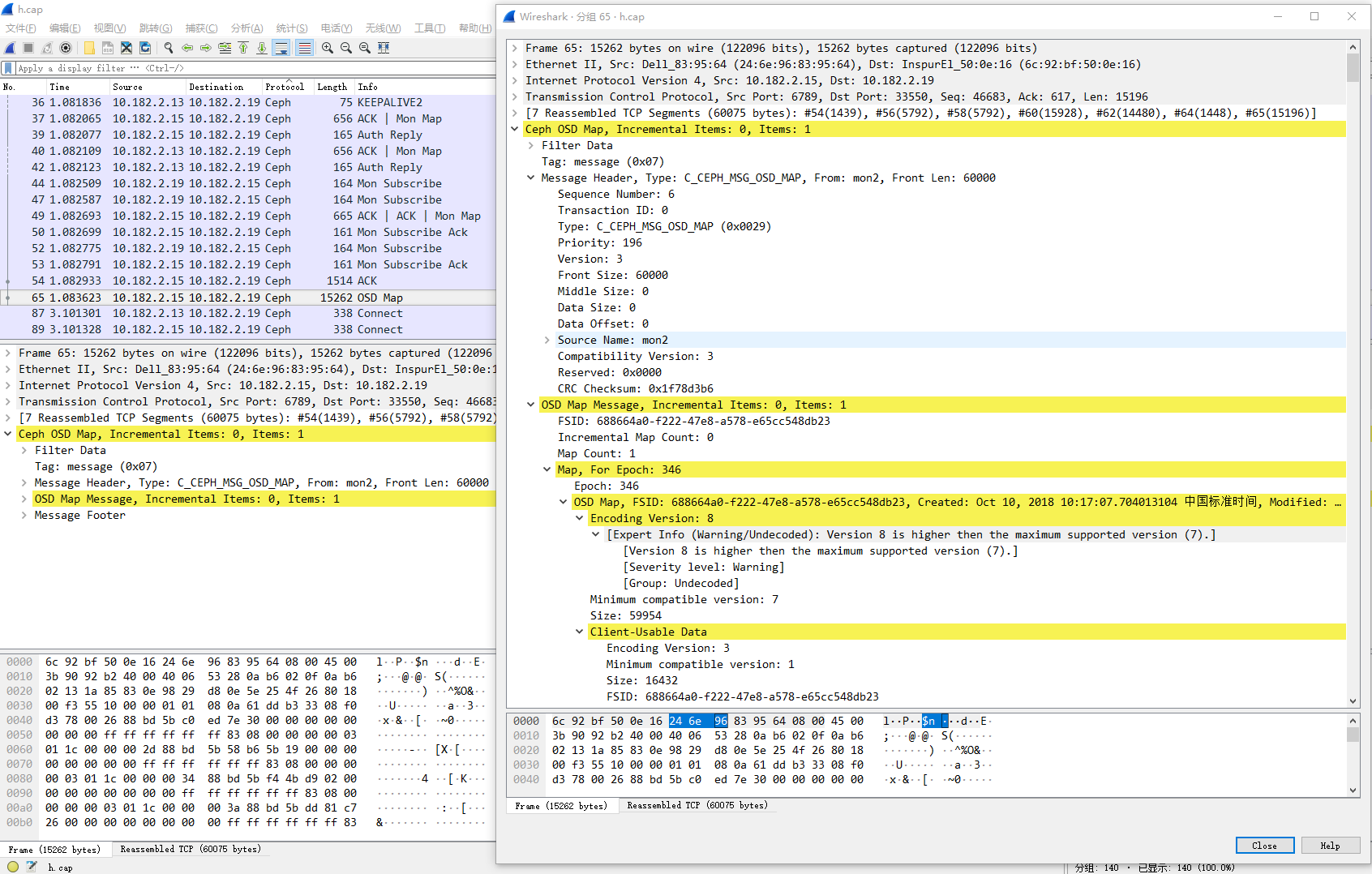
Mon Map编解码过程分析
关键数据结构都定义在src\include\buffer.h中,主要包括:
- buffer::ptr
- _raw:保存实际的编码消息数据
- buffer::ptr::iterator :遍历ptr的迭代器类,提供各种函数用来寻址ptr中的数据
- buffer::list
- _buffers:保存ptr的list,也即保存多条编码数据
- append_buffer:ptr类型,4K对齐,保存编码数据,,其append操作实际是append到ptr._raw,之后会把它push_back到_buffers中,push_back之前会通过ptr构造函数填充ptr的_raw、_off、_len等数据,也即把_raw中保存的数据的偏移量和长度也保存起来,解码时使用
- buffer::list::iterator:遍历_buffers的迭代器,继承自buffer::list::iterator_impl,主要是对外提供接口,对内封装了iterator_impl的相关接口
- buffer::list::iterator_impl:遍历_buffers的迭代器实际实现类,主要实现有advance、seek、copy等函数,用来从_buffers里取出数据,advance函数用来在copy函数执行过程中进行ptr内或_buffers的多个ptr前后跳转,有两种场景,一中是跳转还在当前ptr内(ptr内取数据),另外一种是_buffers list中一个ptr已经copy完(跨ptr取数据),需要跳转到下一个ptr对象继续copy。seek函数也是利用advance函数完成数据寻址操作。
以L版本代码为例,编解码代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
void MonMap::encode(bufferlist& blist, uint64_t con_features) const { /* we keep the mon_addr map when encoding to ensure compatibility * with clients and other monitors that do not yet support the 'mons' * map. This map keeps its original behavior, containing a mapping of * monitor id (i.e., 'foo' in 'mon.foo') to the monitor's public * address -- which is obtained from the public address of each entry * in the 'mons' map. */ // mon_addr是为了兼容老版本,新版本直接用mon_info了 map<string,entity_addr_t> mon_addr; for (map<string,mon_info_t>::const_iterator p = mon_info.begin(); p != mon_info.end(); ++p) { mon_addr[p->first] = p->second.public_addr; } // con_features是client和server建立connection时协商的,也就是二者支持的feature进行&操作 if ((con_features & CEPH_FEATURE_MONNAMES) == 0) { __u16 v = 1; // v1版本编码过程 ::encode(v, blist); ::encode_raw(fsid, blist); ::encode(epoch, blist); vector<entity_inst_t> mon_inst(mon_addr.size()); for (unsigned n = 0; n < mon_addr.size(); n++) mon_inst[n] = get_inst(n); ::encode(mon_inst, blist, con_features); ::encode(last_changed, blist); ::encode(created, blist); return; } if ((con_features & CEPH_FEATURE_MONENC) == 0) { __u16 v = 2; // v2版本编码过程 ::encode(v, blist); ::encode_raw(fsid, blist); ::encode(epoch, blist); ::encode(mon_addr, blist, con_features); ::encode(last_changed, blist); ::encode(created, blist); } ENCODE_START(5, 3, blist); // v5版本编码过程,最低兼容版本是v3,blist是编码输出缓冲区 ::encode_raw(fsid, blist); // 编码fsid ::encode(epoch, blist); // 编码epoch ::encode(mon_addr, blist, con_features); // 编码mon_addr,注意con_features参数 ::encode(last_changed, blist); // 编码last_changed时间 ::encode(created, blist); // 编码created时间 ::encode(persistent_features, blist); // v5版本新增字段,v3版本decode时忽略,下同 ::encode(optional_features, blist); // this superseeds 'mon_addr' ::encode(mon_info, blist, con_features); ENCODE_FINISH(blist); // 结束编码 } void MonMap::decode(bufferlist::iterator &p) { // 解码过程是编码过程的反向操作,也是按编码顺序来的 map<string,entity_addr_t> mon_addr; DECODE_START_LEGACY_COMPAT_LEN_16(5, 3, 3, p); ::decode_raw(fsid, p); ::decode(epoch, p); if (struct_v == 1) { vector<entity_inst_t> mon_inst; ::decode(mon_inst, p); for (unsigned i = 0; i < mon_inst.size(); i++) { char n[2]; n[0] = '0' + i; n[1] = 0; string name = n; mon_addr[name] = mon_inst[i].addr; } } else { ::decode(mon_addr, p); } ::decode(last_changed, p); ::decode(created, p); if (struct_v >= 4) { ::decode(persistent_features, p); ::decode(optional_features, p); } if (struct_v >= 5) { ::decode(mon_info, p); } else { // we may be decoding to an existing monmap; if we do not // clear the mon_info map now, we will likely incur in problems // later on MonMap::sanitize_mons() mon_info.clear(); } DECODE_FINISH(p); sanitize_mons(mon_addr); calc_ranks(); } |
encode调用栈:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Thread 15 "ms_dispatch" hit Breakpoint 1, MonMap::encode (this=0x7fff39218470, blist=..., con_features=2305244844532236283) at /mnt/ceph-Luminous/src/mon/MonMap.cc:138 138 { (gdb) bt #0 MonMap::encode (this=0x7fff39218470, blist=..., con_features=2305244844532236283) at /mnt/ceph-Luminous/src/mon/MonMap.cc:138 #1 0x00005560771f483f in Monitor::send_latest_monmap (this=0x556081f94800, con=0x556082b50800) at /mnt/ceph-Luminous/src/mon/Monitor.cc:5116 #2 0x00005560772c04a5 in AuthMonitor::prep_auth (this=0x556081fbb800, op=..., paxos_writable=false) at /mnt/ceph-Luminous/src/mon/AuthMonitor.cc:482 #3 0x00005560772be9d0 in AuthMonitor::preprocess_query (this=0x556081fbb800, op=...) at /mnt/ceph-Luminous/src/mon/AuthMonitor.cc:292 #4 0x000055607741e850 in PaxosService::dispatch (this=0x556081fbb800, op=...) at /mnt/ceph-Luminous/src/mon/PaxosService.cc:74 #5 0x00005560771ebf54 in Monitor::dispatch_op (this=0x556081f94800, op=...) at /mnt/ceph-Luminous/src/mon/Monitor.cc:4234 #6 0x00005560771ebb3d in Monitor::_ms_dispatch (this=0x556081f94800, m=0x5560828ad900) at /mnt/ceph-Luminous/src/mon/Monitor.cc:4209 #7 0x0000556077228a9e in Monitor::ms_dispatch (this=0x556081f94800, m=0x5560828ad900) at /mnt/ceph-Luminous/src/mon/Monitor.h:899 #8 0x0000556077a3aab9 in Messenger::ms_deliver_dispatch (this=0x556082797000, m=0x5560828ad900) at /mnt/ceph-Luminous/src/msg/Messenger.h:668 #9 0x0000556077a39a8a in DispatchQueue::entry (this=0x556082797180) at /mnt/ceph-Luminous/src/msg/DispatchQueue.cc:197 #10 0x000055607773443e in DispatchQueue::DispatchThread::entry (this=0x556082797328) at /mnt/ceph-Luminous/src/msg/DispatchQueue.h:101 #11 0x0000556077873079 in Thread::entry_wrapper (this=0x556082797328) at /mnt/ceph-Luminous/src/common/Thread.cc:79 #12 0x0000556077872fae in Thread::_entry_func (arg=0x556082797328) at /mnt/ceph-Luminous/src/common/Thread.cc:59 #13 0x00007fee9dfe1494 in start_thread (arg=0x7fee90a88700) at pthread_create.c:333 #14 0x00007fee9a0ccacf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 |
decode调用栈:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
// ceph消息decode过程(L版本) Thread 9 "ms_dispatch" hit Breakpoint 3, ceph::buffer::ptr::copy_out (this=0x7fffdc002e20, o=82, l=8, dest=0x555555e6a464 "\vK\311[)\335Q\032") at /mnt/ceph/src/common/buffer.cc:1035 1035 assert(_raw); (gdb) bt #0 ceph::buffer::ptr::copy_out (this=0x7fffdc002e20, o=82, l=8, dest=0x555555e6a464 "\vK\311[)\335Q\032") at /mnt/ceph/src/common/buffer.cc:1035 #1 0x00007ffff72eb1d6 in ceph::buffer::list::iterator_impl<false>::copy (this=0x7fffe50f9e10, len=8, dest=0x555555e6a464 "\vK\311[)\335Q\032") at /mnt/ceph/src/common/buffer.cc:1248 #2 0x00007ffff72e14cc in ceph::buffer::list::iterator::copy (this=0x7fffe50f9e10, len=8, dest=0x555555e6a464 "\vK\311[)\335Q\032") at /mnt/ceph/src/common/buffer.cc:1434 #3 0x0000555555942ee9 in utime_t::decode (this=0x555555e6a464, p=...) at /mnt/ceph/src/include/utime.h:133 #4 0x0000555555942f0f in decode (c=..., p=...) at /mnt/ceph/src/include/utime.h:390 #5 0x00007fffedca7b88 in MonMap::decode (this=0x555555e6a448, p=...) at /mnt/ceph/src/mon/MonMap.cc:210 #6 0x00007fffedc8f676 in decode (c=..., p=...) at /mnt/ceph/src/mon/MonMap.h:346 #7 0x00007fffedc82a2e in MonClient::handle_monmap (this=0x555555e6a438, m=0x7fffdc000f60) at /mnt/ceph/src/mon/MonClient.cc:331 #8 0x00007fffedc8253b in MonClient::ms_dispatch (this=0x555555e6a438, m=0x7fffdc000f60) at /mnt/ceph/src/mon/MonClient.cc:272 #9 0x00007fffedccfac9 in Messenger::ms_deliver_dispatch (this=0x555555e6b520, m=0x7fffdc000f60) at /mnt/ceph/src/msg/Messenger.h:668 #10 0x00007fffedcce884 in DispatchQueue::entry (this=0x555555e6b6a0) at /mnt/ceph/src/msg/DispatchQueue.cc:197 #11 0x00007fffedea5c54 in DispatchQueue::DispatchThread::entry (this=0x555555e6b848) at /mnt/ceph/src/msg/DispatchQueue.h:101 #12 0x00007fffee04376d in Thread::entry_wrapper (this=0x555555e6b848) at /mnt/ceph/src/common/Thread.cc:79 #13 0x00007fffee0436a2 in Thread::_entry_func (arg=0x555555e6b848) at /mnt/ceph/src/common/Thread.cc:59 #14 0x00007fffeb626494 in start_thread (arg=0x7fffe50fe700) at pthread_create.c:333 #15 0x00007fffea07bacf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 (gdb) n 2018-10-19 12:18:12.443495 7fffe7903700 -1 asok(0x555555d8c810) AdminSocket: error writing response length (32) Broken pipe 1036 if (o+l > _len) (gdb) 1038 char* src = _raw->data + _off + o; (gdb) 1039 maybe_inline_memcpy(dest, src, l, 8); (gdb) 1040 } (gdb) p *(utime_t*)dest // 可以通过强制类型转换打印出decode的数据 $35 = {tv = {tv_sec = 1534409040, tv_nsec = 303455561}} (gdb) c Continuing. |
接下来要说的是具体的encode和decode流程,以我调试的mon_addr为例:
encode
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// ::encode(mon_addr, blist, con_features);调用这个,但没理解为啥是std::map<T,U,Comp,Alloc>& m // mon_addr定义是map<string,entity_addr_t> mon_addr; template<class T, class U, class Comp, class Alloc, typename t_traits=denc_traits<T>, typename u_traits=denc_traits<U>> inline typename std::enable_if<!t_traits::supported || !u_traits::supported>::type encode(const std::map<T,U,Comp,Alloc>& m, bufferlist& bl, uint64_t features) { __u32 n = (__u32)(m.size()); // 获取map长度,也即接下来要编码几个monitor信息 encode(n, bl); // 先编码消息体长度,防止解码的时候越界 for (auto p = m.begin(); p != m.end(); ++p) { // 遍历map,逐项编码,每一项对应一个monitor encode(p->first, bl, features); // monitor名称,string类型 encode(p->second, bl, features); // monitor地址,struct entity_addr_t类型 } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// encode(n, bl)进入实际的编码过程是(n是__u32类型也就是uint32_t) WRITE_INTTYPE_ENCODER(uint32_t, le32) // 这是个宏定义如下: // ----------------------------------- // int types #define WRITE_INTTYPE_ENCODER(type, etype) \ inline void encode(type v, bufferlist& bl, uint64_t features=0) { \ ceph_##etype e; // 类型转换,转换为ceph_le(little endian) \ e = v; // 这里并没有进行大小端转换,都是小端,src/include/byteorder.h:71 -> src/include/byteorder.h:63 \ encode_raw(e, bl); // 裸数据编码,-> src/include/encoding.h:69 \ } \ inline void decode(type &v, bufferlist::iterator& p) { \ ceph_##etype e; \ decode_raw(e, p); \ v = e; \ } // -------------------------------------- // base types template<class T> inline void encode_raw(const T& t, bufferlist& bl) { bl.append((char*)&t, sizeof(t)); // -> src/common/buffer.cc:1935 } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
void buffer::list::append(const char *data, unsigned len) { while (len > 0) { // put what we can into the existing append_buffer. unsigned gap = append_buffer.unused_tail_length(); if (gap > 0) { if (gap > len) gap = len; //cout << "append first char is " << data[0] << ", last char is " << data[len-1] << std::endl; append_buffer.append(data, gap); // buffer::list::append_buffer,buffer::ptr类型 append(append_buffer, append_buffer.length() - gap, gap); // -> buffer::list::append // add segment to the list len -= gap; data += gap; } if (len == 0) break; // done! // make a new append_buffer. fill out a complete page, factoring in the // raw_combined overhead. size_t need = ROUND_UP_TO(len, sizeof(size_t)) + sizeof(raw_combined); size_t alen = ROUND_UP_TO(need, CEPH_BUFFER_ALLOC_UNIT) - sizeof(raw_combined); append_buffer = raw_combined::create(alen, 0, get_mempool()); append_buffer.set_length(0); // unused, so far. } } ...... void buffer::list::append(const ptr& bp, unsigned off, unsigned len) { assert(len+off <= bp.length()); if (!_buffers.empty()) { ptr &l = _buffers.back(); if (l.get_raw() == bp.get_raw() && l.end() == bp.start() + off) { // yay contiguous with tail bp! l.set_length(l.length()+len); _len += len; return; } } // add new item to list push_back(ptr(bp, off, len)); // -> src/include/buffer.h:768 } |
|
1 2 3 4 5 6 |
void push_back(ptr&& bp) { if (bp.length() == 0) return; _len += bp.length(); _buffers.push_back(std::move(bp)); // buffer::list::_buffers类型为std::list<ptr> } |
其他几个字段也是类似过程,就不做分析,差别就是编码的数据类型不一样,比如string、struct等,string属于基础数据类型,encode.h有对应的encode函数,struct数据类型则需要在对应的struct结构体定义其自己的encode函数,如entity_addr_t::encode (src\msg\msg_types.h)。
decode过程也是类似,根据decode的数据类型,找到对应的decode函数,按段解码即可。数据类型是预先定义好的,如decode(mon_addr, p),mon_addr的类型是已知的,因此其decode函数也可以找到(一般都是跟encode放在一起),只不过由于encode.h中有很多的宏,不好找到源码而已,配合gdb单步调试应该容易很多(记得在do_cmake.sh里的cmake命令那行加上-O0 -g3 -gdwarf-4这几个CXX_FLAGS编译选项: -DCMAKE_CXX_FLAGS="-O0 -g3 -gdwarf-4" -DCMAKE_BUILD_TYPE=Debug)。一般是先解码出消息体长度,然后再逐条解码。总之一切过程都是预先定义好的,一旦收到的消息内容与预设的解码方案不匹配,就会导致各种错误。这就是编解码协议存在的原因。(话说这也是我第一次接触编解码协议,看完这些流程还有点小激动)。
encode是把数据存入消息体,decode是从消息体取出数据,最底层的编码解码都是按字节完成的,编码时会强转为char *类型,底层解码也不区分数据类型,由上层使用方负责进行转换,对应的结构体都定义在src\include\buffer.h中,相关的函数实现在src\common\buffer.cc中。
decode的核心是ceph::buffer::ptr::copy_out () (/mnt/ceph/src/common/buffer.cc:1035),最终都是由它把数据从消息体里取出来的。相关的调用栈可以参考上面贴出来的decode调用栈。
下面附上我在调试过程中手绘的协议字段表格:
L版本:


H版本:
