部署
参考:
– http://docs.ceph.com/docs/master/dev/blkin/
– https://zipkin.io/pages/quickstart.html
– https://github.com/openzipkin/zipkin/blob/master/zipkin-server/README.md#cassandra-storage
– https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/mysql-v1
– https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
– http://cassandra.apache.org/download/
– https://blog.csdn.net/vbirdbest/article/details/77802031
环境要求
- ceph-luminous版本编译环境
- Debian9.1 + 4.9.65内核
- 已部署好ceph集群
部署ceph+blkin
步骤
- 修改do_cmake.sh,在cmake那行加上”-DWITH_BLKIN=ON”打开blkin编译选项
- ./do_cmake.sh; cd build; make; make install
- 修改ceph.conf,打开blkin相关配置项:
|
1 2 3 4 5 |
[global] osd_blkin_trace_all = true rbd_blkin_trace_all = true osdc_blkin_trace_all = true |
部署babeltrace-zipkin
这个项目的用途是把blkin配合lttng收集的trace数据转换并发送给zipkin的数据采集器,zipkin聚合后存储起来供后续web查询使用。
步骤
- git clone https://github.com/vears91/babeltrace-zipkin
- cd babeltrace-zipkin/setup; 找到 ubuntu.sh,注意这个脚本里面会安装依赖包,以及编译并安装blkin-lib,下载zipkin.jar,最后还会git pull更新下babeltrace-zipkin,由于github clone项目时快时慢,因此建议直接在PC上下载项目的压缩包,单独手工安装,这个很快
- 提取出ubuntu.sh里面的pip3 install和apt-get install相关命令,直接手工安装即可
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
sudo apt-get install -y git sudo apt-get install -y python3-pip sudo apt-get install -y default-jre sudo apt-get install -y libboost-thread-dev sudo pip3 install --upgrade pip sudo pip3 install scribe sudo pip3 install thrift3babeltrace sudo pip3 install facebook-scribe-py3 sudo pip3 install thriftpy sudo pip3 install scribe_logger sudo apt-get install -y babeltrace sudo apt-get install -y python3-babeltrace |
部署lttng
直接apt安装即可:
|
1 2 3 4 |
sudo apt-get install -y lttng-tools sudo apt-get install -y lttng-modules-dkms sudo apt-get install -y liblttng-ust-dev |
安装完毕后有如下几个包:
|
1 2 3 4 5 6 7 8 |
ii liblttng-ctl0:amd64 2.9.3-1 amd64 LTTng control and utility library ii liblttng-ust-ctl2:amd64 2.9.0-2+deb9u1 amd64 LTTng 2.0 Userspace Tracer (trace control library) ii liblttng-ust-dev:amd64 2.9.0-2+deb9u1 amd64 LTTng 2.0 Userspace Tracer (development files) ii liblttng-ust-python-agent0:amd64 2.9.0-2+deb9u1 amd64 LTTng 2.0 Userspace Tracer (Python agent native library) ii liblttng-ust0:amd64 2.9.0-2+deb9u1 amd64 LTTng 2.0 Userspace Tracer (tracing libraries) ii lttng-modules-dkms 2.9.0-1 all Linux Trace Toolkit (LTTng) kernel modules (DKMS) ii lttng-tools 2.9.3-1 amd64 LTTng control and utility programs |
具体哪几个有用我也不完全确定,lttng-tools这个肯定用到的,lttng-modules-dkms这个内核态的应该用不到,ceph都是用户态的。
部署zipkin
zipkin部署非常简单,只需要有jre环境,就可以通过下载可独立执行的zipkin.jar包即可运行。最新稳定版下载链接:
– https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
zipkin的存储后端有多种:
– memory(默认):内存存储,非持久化,重启zipkin进程后数据丢失,需要重新导入
– MySQL:不解释
– Cassandra(官方推荐,最初支持的方案):个人理解是一种类似influxdb的时序数据库
– Elasticsearch:参考官网介绍,是一个分布式、RESTful 风格的搜索和数据分析引擎
我这边验证了前面3种方式,因此需要增加部署MySQL(mariadb)或者Cassandra数据库。
memory方式
直接执行java -jar zipkin.jar即可,web端口默认是9411,浏览器打开http://$IP:9411即可访问zipkin web页面。
注意内存方式下trace数据是非持久化的,重启后丢失。
mariadb方式
部署mariadb:
1. 使用apt安装包:apt-get install mariadb-common mariadb-server
2. 创建用户并添加权限(默认的root用户会连接失败):GRANT ALL PRIVILEGES ON *.* TO 'zipkin'@'%' IDENTIFIED BY 'admin123' WITH GRANT OPTION; FLUSH PRIVILEGES;
3. 创建数据库和schema:直接使用官方的sql脚本创建,https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql ,保存脚本到zipkin.sql并执行mysql -Dzipkin < zipkin.sql
4. 如果数据库和zipkin不在一个节点上,还需要修改mariadb的监听地址段并重启服务,/etc/mysql/mariadb.conf.d/50-server.cnf的bind-address配置项
启动zipkin+mariadb:STORAGE_TYPE=mysql MYSQL_USER=zipkin MYSQL_HOST=127.0.0.1 MYSQL_PASS=admin123 java -jar zipkin.jar
相关环境变量:https://github.com/openzipkin/zipkin/blob/master/zipkin-server/README.md#mysql-storage
导入数据后,可以用mysql命令查看数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
MariaDB [(none)]> use zipkin; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed MariaDB [zipkin]> show tables; +---------------------+ | Tables_in_zipkin | +---------------------+ | zipkin_annotations | | zipkin_dependencies | | zipkin_spans | +---------------------+ 3 rows in set (0.00 sec) MariaDB [zipkin]> select count(*) from zipkin_spans; +----------+ | count(*) | +----------+ | 130437 | +----------+ 1 row in set (0.00 sec) |
Cassandra方式
部署Cassandra:
|
1 2 3 4 5 |
echo "deb http://www.apache.org/dist/cassandra/debian 311x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add - sudo apt-get update sudo apt-get install cassandra |
启动及相关默认路径:
|
1 2 3 4 5 6 |
You can start Cassandra with sudo service cassandra start and stop it with sudo service cassandra stop. However, normally the service will start automatically. For this reason be sure to stop it if you need to make any configuration changes. Verify that Cassandra is running by invoking nodetool status from the command line. The default location of configuration files is /etc/cassandra. The default location of log and data directories is /var/log/cassandra/ and /var/lib/cassandra. Start-up options (heap size, etc) can be configured in /etc/default/cassandra. |
时序数据库一般不需要特殊的schema配置,直接使用即可:STORAGE_TYPE=cassandra3 java -jar zipkin.jar
导入数据后可以用cqlsh命令查看数据库内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
cqlsh> DESCRIBE KEYSPACES; system_schema system_auth system zipkin2 system_distributed system_traces cqlsh> use zipkin2; cqlsh:zipkin2> DESCRIBE TABLES; dependency span trace_by_service_span span_by_service cqlsh:zipkin2> select * from span limit 1; trace_id | ts_uuid | id | annotation_query | annotations | debug | duration | kind | l_ep | l_service | parent_id | r_ep | shared | span | tags | trace_id_high | ts ------------------+--------------------------------------+------------------+------------------+---------------------------------------+-------+----------+------+-----------------------------------------------------------------+--------------+-----------+------+--------+---------+------+---------------+------------------ 7836119a76da5f76 | ac9912d0-032f-11e9-899e-f156728a4881 | 7836119a76da5f76 | ░finish░ | [{ts: 1545183890557972, v: 'finish'}] | null | null | null | {service: 'objectcacher', ipv4: '0.0.0.0', ipv6: null, port: 0} | objectcacher | null | null | null | flusher | null | null | 1545183890557972 (1 rows) |
参考官网:http://cassandra.apache.org/download/
最终部署架构
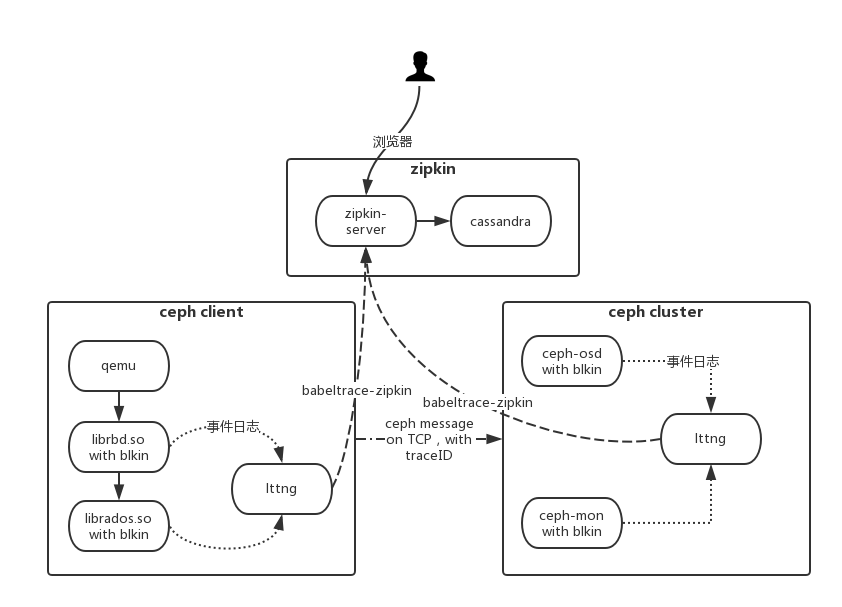
使用
- 确保lttng服务正常运行:
systemctl status lttng-sessiond.service - 停止ceph服务,包括所有服务端进程以及客户端进程(如果是客户端与服务端不再一个节点,也要单独部署lttng和使用打开了blkin的ceph)
- 创建lttng session,并添加trace event:
|
1 2 3 4 5 6 |
lttng create blkin-test lttng enable-event --userspace zipkin:timestamp lttng enable-event --userspace zipkin:keyval_integer lttng enable-event --userspace zipkin:keyval_string lttng start |
- 启动所有ceph进程,以及客户端进程,并进行相关测试
lttng stop停止session,其他可用命令:lttng list/status/view/destroy- 使用babeltrace-zipkin工具导入数据到zipkin:
cd /mnt/babeltrace-zipkin-master/; python3 babeltrace_zipkin.py ~/lttng-traces/blkin-wp2-20181218-160516/ust/uid/0/64-bit/ -p 9411 -s 127.0.0.1,其中-p 9411是zipkin的数据接收端口(也是web端口),-s是zipkin服务监听地址。数据导入过程比较耗时,需要等待,开始导入和导入完成都会有日志提示:
|
1 2 3 |
Sending traces to 127.0.0.1:9411 using http Done sending |
- 导入过程中如果出错可以查看zipkin的日志(前台执行的话看控制台输出就可以了)。
- 使用web进行数据查询:浏览器打开
http://$IP:9411即可访问zipkin web页面。需要注意的是,查询页面的时间参数是指lttng日志文件里的采集时间,而非数据导入到zipkin的时间,另外还要注意数量参数,经过实测仅搜索指定数量的trace event数据,然后对这些数据进行排序后展示,而不是对所有数据排序后进行截取展示,因此建议时间采用自定义时间段方式,缩小时间段,减少数据量之后再适当设置较大的数量进行查找。
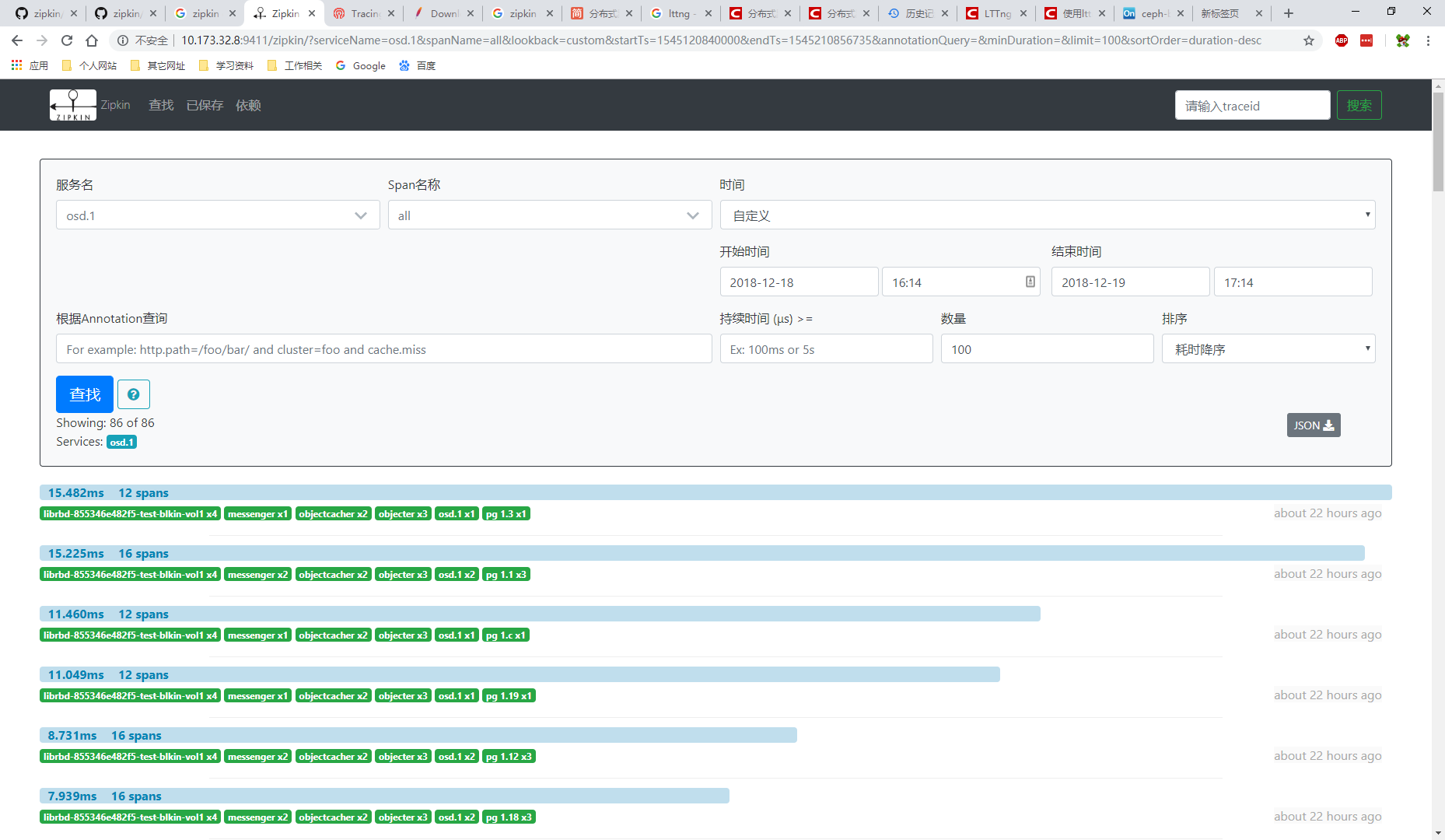
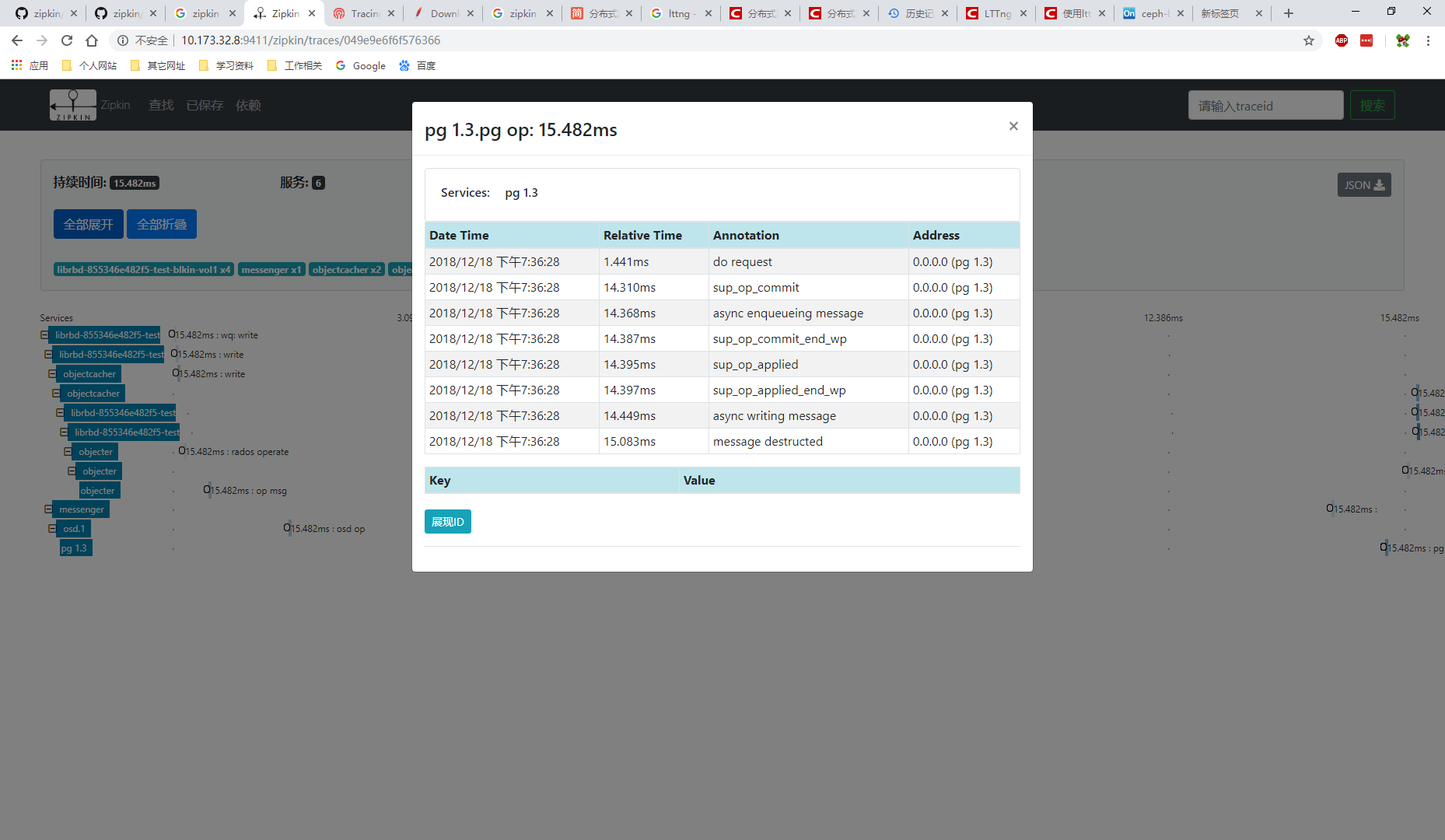
自定义扩展
相关名词
- trace event:跟踪事件类型如zipkin:timestamp、zipkin:keyval_integer、zipkin:keyval_string
- service:跟踪服务类型如osd.1、pg 1.0、messenger、objecter、librbd-855346e482f5-test-blkin-vol1等,对应代码中的trace_endpoint,ZTracer::Endpoint类型
- span:service的子项,标记一个跨度,跨函数使用,例如librbd里面有多个跨度,从ImageRequestWQ的“wq: write”到“writeback”等,osd默认只有一个“osd op”,pg有“pg op”和“replicated op”,对应代码中的osd_trace、pg_trace、journal_trace等,ZTracer::Trace类型,可以用ZTracer::Trace::init函数来初始化,通过在初始化时指定parent span来构建调用链关系,parent可以跨service,顶级span的id跟traceId相同,可以理解为第一个span的ID就是traceId
- annotation:span的子项,基本上是在同一个函数里面使用,ZTracer::Trace::event即可创建
参考:https://blog.csdn.net/manzhizhen/article/details/52811600、https://blog.csdn.net/manzhizhen/article/details/53865368
ceph扩展相关trace类型
service类型一般不需要扩展,已经基本全部包含了,这里重点介绍span和annotation两种类型的扩展方法。
span:
src\common\TrackedOp.h::class TrackedOp类里有如下定义:
|
1 2 3 4 5 6 |
public: ZTracer::Trace osd_trace; ZTracer::Trace pg_trace; ZTracer::Trace store_trace; ZTracer::Trace journal_trace; |
我们只需要模仿它们来定义我们自己的span名称即可。
src\osd\OSD.cc::void OSD::ms_fast_dispatch(Message *m)中会对osd_trace进行初始化,可以参考他的初始化过程来初始化我们自己的span:
|
1 2 3 |
if (m->trace) // m->trace是通过消息里面传递过来的,用来作为parent span来初始化当前span,parent span非常重要,如果不指定就无法生成调用链关系,当然如果你不关心前后流程,也可以不指定,作为一个单独的span来查询分析即可 op->osd_trace.init("osd op", &trace_endpoint, &m->trace); |
实际上我们需要扩展span的场景也很少,因为这几个span已经差不多可以包含所有关键流程了。
扩展完span就可以通过往span中添加annotation来进行实际的时间戳记录了,添加annotation也非常简单:
|
1 2 3 4 |
op->osd_trace.event("enqueue op"); op->osd_trace.keyval("priority", op->get_req()->get_priority()); // 这两个是keyval类型的annotation,前面是key,后面是value(支持string和integer类型数据的存储) op->osd_trace.keyval("cost", op->get_req()->get_cost()); |
keyval类型的annotation可以用来观察系统运行过程中某些关键变量的值,如关键运行参数等。