问题1:哪些变更需要通过Paxos进行决议?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// src\mon\mon_types.h #define PAXOS_PGMAP 0 // before osd, for pg kick to behave #define PAXOS_MDSMAP 1 #define PAXOS_OSDMAP 2 #define PAXOS_LOG 3 #define PAXOS_MONMAP 4 #define PAXOS_AUTH 5 #define PAXOS_NUM 6 inline const char *get_paxos_name(int p) { switch (p) { case PAXOS_MDSMAP: return "mdsmap"; case PAXOS_MONMAP: return "monmap"; case PAXOS_OSDMAP: return "osdmap"; case PAXOS_PGMAP: return "pgmap"; case PAXOS_LOG: return "logm"; case PAXOS_AUTH: return "auth"; default: assert(0); return 0; } } |
初始化流程:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
Monitor::Monitor(CephContext* cct_, string nm, MonitorDBStore *s, Messenger *m, MonMap *map) : ...... paxos_service(PAXOS_NUM), ...... { ...... paxos = new Paxos(this, "paxos"); paxos_service[PAXOS_MDSMAP] = new MDSMonitor(this, paxos, "mdsmap"); paxos_service[PAXOS_MONMAP] = new MonmapMonitor(this, paxos, "monmap"); paxos_service[PAXOS_OSDMAP] = new OSDMonitor(this, paxos, "osdmap"); paxos_service[PAXOS_PGMAP] = new PGMonitor(this, paxos, "pgmap"); paxos_service[PAXOS_LOG] = new LogMonitor(this, paxos, "logm"); paxos_service[PAXOS_AUTH] = new AuthMonitor(this, paxos, "auth"); ...... } // src\ceph_mon.cc:main -> Monitor::preinit -> Monitor::init_paxos void Monitor::init_paxos() { dout(10) << __func__ << dendl; paxos->init(); // init services for (int i = 0; i < PAXOS_NUM; ++i) { paxos_service[i]->init(); } refresh_from_paxos(NULL); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
void Monitor::dispatch(MonSession *s, Message *m, const bool src_is_mon) { assert(m != NULL); ...... /* deal with all messages which caps should be checked somewhere else */ dealt_with = true; switch (m->get_type()) { // OSDs case CEPH_MSG_MON_GET_OSDMAP: case MSG_OSD_MARK_ME_DOWN: case MSG_OSD_FAILURE: case MSG_OSD_BOOT: case MSG_OSD_ALIVE: case MSG_OSD_PGTEMP: case MSG_REMOVE_SNAPS: paxos_service[PAXOS_OSDMAP]->dispatch((PaxosServiceMessage*)m); break; // MDSs case MSG_MDS_BEACON: case MSG_MDS_OFFLOAD_TARGETS: paxos_service[PAXOS_MDSMAP]->dispatch((PaxosServiceMessage*)m); break; // pg case CEPH_MSG_STATFS: case MSG_PGSTATS: case MSG_GETPOOLSTATS: paxos_service[PAXOS_PGMAP]->dispatch((PaxosServiceMessage*)m); break; case CEPH_MSG_POOLOP: paxos_service[PAXOS_OSDMAP]->dispatch((PaxosServiceMessage*)m); break; ...... } |
可以根据初始化流程看出上述所有dispatch函数都是基类的PaxosService::dispatch。
问题2:决议间隔时间的用途是什么?该间隔内产生的多个提案是批量提交给Paxos服务进行决议的吗?
决议间隔时间由配置项paxos_propose_interval确定,默认值是1s,paxos_min_wait是最小间隔时间,默认0.05s。
两个配置项的用途:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
bool PaxosService::should_propose(double& delay) { // simple default policy: quick startup, then some damping. if (get_last_committed() <= 1) delay = 0.0; else { utime_t now = ceph_clock_now(g_ceph_context); if ((now - paxos->last_commit_time) > g_conf->paxos_propose_interval) delay = (double)g_conf->paxos_min_wait; // 长时间没有决议,则强制delay paxos_min_wait else delay = (double)(g_conf->paxos_propose_interval + paxos->last_commit_time - now); // delay时间会从paxos_propose_interval去掉已经耗费的时间,也就是上次决议时间也算在paxos_propose_interval间隔内,并不是固定1s } return true; } |
我理解之所以有这2个间隔,主要是为了防止决议过程阻塞dispatch线程,尤其是paxos_min_wait这个只有0.05s,实际上这么短时间的定时器是没有意义的,主要是为了切换到timer线程。
在决议间隔时间段内,所有的待决议提案都是保存在内存中的,等待delay时间到了才进行决议:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
bool PaxosService::dispatch(PaxosServiceMessage *m) { ...... // update if (prepare_update(m)) { double delay = 0.0; if (should_propose(delay)) { if (delay == 0.0) { propose_pending(); } else { // delay a bit if (!proposal_timer) { proposal_timer = new C_Propose(this); dout(10) << " setting proposal_timer " << proposal_timer << " with delay of " << delay << dendl; mon->timer.add_event_after(delay, proposal_timer); } else { dout(10) << " proposal_timer already set" << dendl; } } } else { dout(10) << " not proposing" << dendl; } } return true; } |
用pgmap举例(osdmap是OSDMonitor::prepare_update):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// Monitor::dispatch(case MSG_PGSTATS) -> PaxosService::dispatch(PGMonitor的基类) -> PGMonitor::prepare_update bool PGMonitor::prepare_update(PaxosServiceMessage *m) { dout(10) << "prepare_update " << *m << " from " << m->get_orig_source_inst() << dendl; switch (m->get_type()) { case MSG_PGSTATS: return prepare_pg_stats((MPGStats*)m); ...... } } // 把变更信息存入pending_inc中(内存) bool PGMonitor::prepare_pg_stats(MPGStats *stats) { dout(10) << "prepare_pg_stats " << *stats << " from " << stats->get_orig_source() << dendl; ...... // osd stat if (mon->osdmon()->osdmap.is_in(from)) { pending_inc.update_stat(from, stats->epoch, stats->osd_stat); } else { pending_inc.update_stat(from, stats->epoch, osd_stat_t()); } ...... // pg stats MPGStatsAck *ack = new MPGStatsAck; ack->set_tid(stats->get_tid()); for (map<pg_t,pg_stat_t>::iterator p = stats->pg_stat.begin(); p != stats->pg_stat.end(); ++p) { ...... dout(15) << " got " << pgid << " reported at " << p->second.reported_epoch << ":" << p->second.reported_seq << " state " << pg_state_string(pg_map.pg_stat[pgid].state) << " -> " << pg_state_string(p->second.state) << dendl; pending_inc.pg_stat_updates[pgid] = p->second; ...... } wait_for_finished_proposal(new C_Stats(this, stats, ack)); // 注册决议完成回调(回复ack消息给上报者) return true; } |
prepare_update之后就是PaxosService::propose_pending,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
void PaxosService::propose_pending() { ...... MonitorDBStore::TransactionRef t = paxos->get_pending_transaction(); if (should_stash_full()) encode_full(t); encode_pending(t); // 把pending_inc中的更新信息编码到bufferlist中,便于在多个monitor之间传递 have_pending = false; ...... // apply to paxos proposing = true; paxos->queue_pending_finisher(new C_Committed(this)); // 注册commit完成的回调 paxos->trigger_propose(); // 开始第一阶段:提交提案 } |
问题3:Paxos决议流程是什么样的?有几个线程处理提案(或者说有几个Paxos服务线程)?
首先看线程问题,根据代码可以看出,Paxos接收更新并分发给各个service只是dispatch线程在处理,但实际上由于timer线程、finisher线程(各一个)的介入,所以可以认为是2个线程在处理,dispatch只负责预处理value更新消息,之后由timer线程进行提案处理,或者由finisher线程完成回调,决议过程由多个monitor共同完成(单monitor除外)。
多个service(pg、osd等)之间是使用相同的线程,但定时器和finisher线程是一个,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
int Monitor::init() { // start ticker timer.init(); // timer线程初始化 ...... } class MonitorDBStore { ...... Finisher io_work; ...... MonitorDBStore(const string& path) : db(0), do_dump(false), dump_fd(-1), io_work(g_ceph_context, "monstore"), // finisher线程初始化 ...... int open(ostream &out) { // monitor进程启动的main函数里调用 db->init(); int r = db->open(out); if (r < 0) return r; io_work.start(); // 启动finisher线程处理io_work绑定队列 is_open = true; return 0; } ...... } |
其次看下Paxos决议流程(https://www.jianshu.com/p/7302e79ab534 这篇文档写的比较清晰,尤其是流程图):
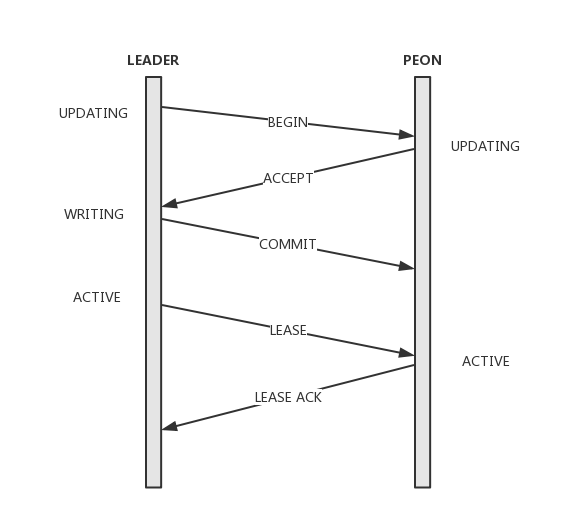
- Leader将提案追加在本地Log(pending_inc),并向Quorum中的所有节点发送begin消息,消息中携带提案值、Pn及指向前一条提案version的last_commit;如果只有一个monitor节点(Quorum=1),则跳过begin、accept阶段直接commit
- Peon收到begin消息,如果accept过更高的pn则忽略,否则提案写入本地Log并返回accept消息。同时Peon会将当前的lease过期掉,在下一次收到lease前不再提供服务;
- Leader收到全部Quorum的accept后进行commit。将Log项在本地DB执行,返回调用方并向所有Quorum节点发送commit消息;
- Peon收到commit消息同样在本地DB执行,完成commit;
- Leader追加lease消息将整个集群带入到active状态。
步骤1代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
// PaxosService::propose_pending -> Paxos::trigger_propose -> Paxos::propose_pending(设置state = STATE_UPDATING) -> Paxos::begin // leader void Paxos::begin(bufferlist& v) { ...... // store the proposed value in the store. IF it is accepted, we will then // have to decode it into a transaction and apply it. MonitorDBStore::TransactionRef t(new MonitorDBStore::Transaction); t->put(get_name(), last_committed+1, new_value); // note which pn this pending value is for. t->put(get_name(), "pending_v", last_committed + 1); t->put(get_name(), "pending_pn", accepted_pn); ...... logger->inc(l_paxos_begin); logger->inc(l_paxos_begin_keys, t->get_keys()); logger->inc(l_paxos_begin_bytes, t->get_bytes()); utime_t start = ceph_clock_now(NULL); get_store()->apply_transaction(t); // leveldb落盘,同步操作,具体分析见后面问题 utime_t end = ceph_clock_now(NULL); logger->tinc(l_paxos_begin_latency, end - start); assert(g_conf->paxos_kill_at != 3); if (mon->get_quorum().size() == 1) { // we're alone, take it easy commit_start(); return; } // ask others to accept it too! for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) { if (*p == mon->rank) continue; dout(10) << " sending begin to mon." << *p << dendl; MMonPaxos *begin = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_BEGIN, ceph_clock_now(g_ceph_context)); begin->values[last_committed+1] = new_value; begin->last_committed = last_committed; begin->pn = accepted_pn; mon->messenger->send_message(begin, mon->monmap->get_inst(*p)); } // set timeout event accept_timeout_event = new C_AcceptTimeout(this); mon->timer.add_event_after(g_conf->mon_accept_timeout, accept_timeout_event); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
2019-05-07 09:01:45.153328 7fe1045bd700 30 mon.ceph-l@0(leader).paxos(paxos updating c 684227..684859) begin transaction dump: { "ops": [ { "op_num": 0, "type": "PUT", "prefix": "paxos", "key": "684860", "length": 13937 }, { "op_num": 1, "type": "PUT", "prefix": "paxos", "key": "pending_v", "length": 8 }, { "op_num": 2, "type": "PUT", "prefix": "paxos", "key": "pending_pn", "length": 8 } ], "num_keys": 3, "num_bytes": 13993 } bl dump: { "ops": [ { "op_num": 0, "type": "PUT", "prefix": "logm", "key": "full_307123", "length": 13472 }, { "op_num": 1, "type": "PUT", "prefix": "logm", "key": "full_latest", "length": 8 }, { "op_num": 2, "type": "PUT", "prefix": "logm", "key": "307124", "length": 273 }, { "op_num": 3, "type": "PUT", "prefix": "logm", "key": "last_committed", "length": 8 } ], "num_keys": 4, "num_bytes": 13819 } |
步骤2代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
// peon void Paxos::handle_begin(MMonPaxos *begin) { ...... // can we accept this? if (begin->pn < accepted_pn) { dout(10) << " we accepted a higher pn " << accepted_pn << ", ignoring" << dendl; begin->put(); return; // 提案编号太小,忽略提案 } ...... logger->inc(l_paxos_begin); // set state. state = STATE_UPDATING; lease_expire = utime_t(); // cancel lease // yes. version_t v = last_committed+1; dout(10) << "accepting value for " << v << " pn " << accepted_pn << dendl; // store the accepted value onto our store. We will have to decode it and // apply its transaction once we receive permission to commit. MonitorDBStore::TransactionRef t(new MonitorDBStore::Transaction); t->put(get_name(), v, begin->values[v]); // note which pn this pending value is for. t->put(get_name(), "pending_v", v); t->put(get_name(), "pending_pn", accepted_pn); ...... logger->inc(l_paxos_begin_bytes, t->get_bytes()); utime_t start = ceph_clock_now(NULL); get_store()->apply_transaction(t); // 同begin,落盘,同步操作 utime_t end = ceph_clock_now(NULL); logger->tinc(l_paxos_begin_latency, end - start); ...... // reply MMonPaxos *accept = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_ACCEPT, ceph_clock_now(g_ceph_context)); accept->pn = accepted_pn; accept->last_committed = last_committed; begin->get_connection()->send_message(accept); begin->put(); } |
步骤3代码(不考虑超时情况,超时则走选主流程):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
// leader void Paxos::handle_accept(MMonPaxos *accept) { dout(10) << "handle_accept " << *accept << dendl; int from = accept->get_source().num(); if (accept->pn != accepted_pn) { // we accepted a higher pn, from some other leader dout(10) << " we accepted a higher pn " << accepted_pn << ", ignoring" << dendl; goto out; } if (last_committed > 0 && accept->last_committed < last_committed-1) { dout(10) << " this is from an old round, ignoring" << dendl; goto out; } assert(accept->last_committed == last_committed || // not committed accept->last_committed == last_committed-1); // committed assert(is_updating() || is_updating_previous()); assert(accepted.count(from) == 0); accepted.insert(from); dout(10) << " now " << accepted << " have accepted" << dendl; assert(g_conf->paxos_kill_at != 6); // only commit (and expose committed state) when we get *all* quorum // members to accept. otherwise, they may still be sharing the now // stale state. // FIXME: we can improve this with an additional lease revocation message // that doesn't block for the persist. if (accepted == mon->get_quorum()) { // yay, commit! dout(10) << " got majority, committing, done with update" << dendl; commit_start(); } out: accept->put(); } void Paxos::commit_start() { ...... MonitorDBStore::TransactionRef t(new MonitorDBStore::Transaction); // commit locally t->put(get_name(), "last_committed", last_committed + 1); // decode the value and apply its transaction to the store. // this value can now be read from last_committed. decode_append_transaction(t, new_value); ...... logger->inc(l_paxos_commit); logger->inc(l_paxos_commit_keys, t->get_keys()); logger->inc(l_paxos_commit_bytes, t->get_bytes()); commit_start_stamp = ceph_clock_now(NULL); get_store()->queue_transaction(t, new C_Committed(this)); // 落盘,异步操作,完成后回调Paxos::commit_finish if (is_updating_previous()) state = STATE_WRITING_PREVIOUS; else if (is_updating()) state = STATE_WRITING; // 更新Paxos状态 else assert(0); ...... } void Paxos::commit_finish() { dout(20) << __func__ << " " << (last_committed+1) << dendl; utime_t end = ceph_clock_now(NULL); logger->tinc(l_paxos_commit_latency, end - commit_start_stamp); assert(g_conf->paxos_kill_at != 8); // cancel lease - it was for the old value. // (this would only happen if message layer lost the 'begin', but // leader still got a majority and committed with out us.) lease_expire = utime_t(); // cancel lease last_committed++; last_commit_time = ceph_clock_now(NULL); // refresh first_committed; this txn may have trimmed. first_committed = get_store()->get(get_name(), "first_committed"); _sanity_check_store(); // tell everyone for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) { if (*p == mon->rank) continue; dout(10) << " sending commit to mon." << *p << dendl; MMonPaxos *commit = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COMMIT, ceph_clock_now(g_ceph_context)); commit->values[last_committed] = new_value; commit->pn = accepted_pn; commit->last_committed = last_committed; mon->messenger->send_message(commit, mon->monmap->get_inst(*p)); } assert(g_conf->paxos_kill_at != 9); // get ready for a new round. new_value.clear(); remove_legacy_versions(); // WRITING -> REFRESH // among other things, this lets do_refresh() -> mon->bootstrap() know // it doesn't need to flush the store queue assert(is_writing() || is_writing_previous()); state = STATE_REFRESH; if (do_refresh()) { commit_proposal(); if (mon->get_quorum().size() > 1) { extend_lease(); // 执行步骤5 } finish_contexts(g_ceph_context, waiting_for_commit); assert(g_conf->paxos_kill_at != 10); finish_round(); } } |
步骤4代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// peon void Paxos::handle_commit(MMonPaxos *commit) { ...... store_state(commit); // 落盘,同步操作 if (do_refresh()) { finish_contexts(g_ceph_context, waiting_for_commit); } commit->put(); } |
步骤5代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
// leader void Paxos::extend_lease() { assert(mon->is_leader()); lease_expire = ceph_clock_now(g_ceph_context); lease_expire += g_conf->mon_lease; acked_lease.clear(); acked_lease.insert(mon->rank); dout(7) << "extend_lease now+" << g_conf->mon_lease << " (" << lease_expire << ")" << dendl; // bcast for (set<int>::const_iterator p = mon->get_quorum().begin(); p != mon->get_quorum().end(); ++p) { if (*p == mon->rank) continue; MMonPaxos *lease = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LEASE, ceph_clock_now(g_ceph_context)); lease->last_committed = last_committed; lease->lease_timestamp = lease_expire; lease->first_committed = first_committed; mon->messenger->send_message(lease, mon->monmap->get_inst(*p)); } // set timeout event. // if old timeout is still in place, leave it. if (!lease_ack_timeout_event) { lease_ack_timeout_event = new C_LeaseAckTimeout(this); mon->timer.add_event_after(g_conf->mon_lease_ack_timeout, lease_ack_timeout_event); } // set renew event lease_renew_event = new C_LeaseRenew(this); utime_t at = lease_expire; at -= g_conf->mon_lease; at += g_conf->mon_lease_renew_interval; mon->timer.add_event_at(at, lease_renew_event); } // peon void Paxos::handle_lease(MMonPaxos *lease) { // sanity if (!mon->is_peon() || last_committed != lease->last_committed) { dout(10) << "handle_lease i'm not a peon, or they're not the leader," << " or the last_committed doesn't match, dropping" << dendl; lease->put(); return; } warn_on_future_time(lease->sent_timestamp, lease->get_source()); // extend lease if (lease_expire < lease->lease_timestamp) { lease_expire = lease->lease_timestamp; utime_t now = ceph_clock_now(g_ceph_context); if (lease_expire < now) { utime_t diff = now - lease_expire; derr << "lease_expire from " << lease->get_source_inst() << " is " << diff << " seconds in the past; mons are probably laggy (or possibly clocks are too skewed)" << dendl; } } state = STATE_ACTIVE; dout(10) << "handle_lease on " << lease->last_committed << " now " << lease_expire << dendl; // ack MMonPaxos *ack = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LEASE_ACK, ceph_clock_now(g_ceph_context)); ack->last_committed = last_committed; ack->first_committed = first_committed; ack->lease_timestamp = ceph_clock_now(g_ceph_context); lease->get_connection()->send_message(ack); // (re)set timeout event. reset_lease_timeout(); // kick waiters finish_contexts(g_ceph_context, waiting_for_active); if (is_readable()) finish_contexts(g_ceph_context, waiting_for_readable); lease->put(); } |
问题4:osdmap、pgmap、monmap是一起决议的吗?
各自决议或者说各自提交提案,但是决议流程完全相同,对Paxos服务来说没有差别(只是提案携带的value等参数不同)。
这就表示他们相互之间是串行的(相对dispatch线程和leveldb落盘操作来说是串行,相对Paxos服务并不完全是,参考上面提到的timer线程和finisher线程),可能会互相影响。
问题5:决议结果是怎么落盘的?一次决议会落盘几次?
根据上面的问题3代码分析,可以看出一次决议有4次落盘(从角色看leader、peon各两次,具体到决议过程是begin阶段leader、peon各一次,commit阶段leader、peon各一次),其中leader在收到peon的accept回复之后的commit阶段的落盘是异步的,其他都是同步。
但是不管同步还是异步落盘,对提案提交者来说,总是要等待决议通过之后才能收到回复,才能继续执行后续流程。
同步落盘:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
class MonitorDBStore { ...... int apply_transaction(MonitorDBStore::TransactionRef t) { KeyValueDB::Transaction dbt = db->get_transaction(); if (do_dump) { bufferlist bl; t->encode(bl); bl.write_fd(dump_fd); } list<pair<string, pair<string,string> > > compact; for (list<Op>::const_iterator it = t->ops.begin(); it != t->ops.end(); ++it) { const Op& op = *it; switch (op.type) { case Transaction::OP_PUT: dbt->set(op.prefix, op.key, op.bl); break; case Transaction::OP_ERASE: dbt->rmkey(op.prefix, op.key); break; case Transaction::OP_COMPACT: compact.push_back(make_pair(op.prefix, make_pair(op.key, op.endkey))); break; default: derr << __func__ << " unknown op type " << op.type << dendl; ceph_assert(0); break; } } int r = db->submit_transaction_sync(dbt); if (r >= 0) { while (!compact.empty()) { if (compact.front().second.first == string() && compact.front().second.second == string()) db->compact_prefix_async(compact.front().first); else db->compact_range_async(compact.front().first, compact.front().second.first, compact.front().second.second); compact.pop_front(); } } else { assert(0 == "failed to write to db"); } return r; } ...... } // src\os\LevelDBStore.cc: int LevelDBStore::submit_transaction_sync(KeyValueDB::Transaction t) { LevelDBTransactionImpl * _t = static_cast<LevelDBTransactionImpl *>(t.get()); leveldb::WriteOptions options; options.sync = true; leveldb::Status s = db->Write(options, &(_t->bat)); logger->inc(l_leveldb_txns); return s.ok() ? 0 : -1; } |
异步落盘:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
class MonitorDBStore { ...... /** * queue transaction * * Queue a transaction to commit asynchronously. Trigger a context * on completion (without any locks held). */ void queue_transaction(MonitorDBStore::TransactionRef t, Context *oncommit) { io_work.queue(new C_DoTransaction(this, t, oncommit)); // 入队后由finisher线程处理,见上面问题3分析 } ...... struct C_DoTransaction : public Context { MonitorDBStore *store; MonitorDBStore::TransactionRef t; Context *oncommit; C_DoTransaction(MonitorDBStore *s, MonitorDBStore::TransactionRef t, Context *f) : store(s), t(t), oncommit(f) {} void finish(int r) { /* The store serializes writes. Each transaction is handled * sequentially by the io_work Finisher. If a transaction takes longer * to apply its state to permanent storage, then no other transaction * will be handled meanwhile. * * We will now randomly inject random delays. We can safely sleep prior * to applying the transaction as it won't break the model. */ double delay_prob = g_conf->mon_inject_transaction_delay_probability; if (delay_prob && (rand() % 10000 < delay_prob * 10000.0)) { utime_t delay; double delay_max = g_conf->mon_inject_transaction_delay_max; delay.set_from_double(delay_max * (double)(rand() % 10000) / 10000.0); lsubdout(g_ceph_context, mon, 1) << "apply_transaction will be delayed for " << delay << " seconds" << dendl; delay.sleep(); } int ret = store->apply_transaction(t); // 见同步落盘 oncommit->complete(ret); } }; } |
问题6:为啥集群没有IO也会进行决议?
pgmap、logm及少量的auth,其中pgmap是在osd在上报pg stats,即使pg stats没有变化,也要120s(osd_mon_report_interval_max)上报一次:
OSD::tick -> OSD::do_mon_report -> OSD::send_pg_stats
问题7:leveldb定期清理怎么做?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// mon_tick_interval = 5s void Monitor::tick() { // ok go. dout(11) << "tick" << dendl; for (vector<PaxosService*>::iterator p = paxos_service.begin(); p != paxos_service.end(); ++p) { (*p)->tick(); (*p)->maybe_trim(); } ...... } |
之后的流程跟正常的决议流程一致,只是leveldb操作变为erase(正常都是put)。
问题8:有哪些手段可以分析Paxos耗时问题?
H版本:
只有少量perf dump数据,包括Paxos和leveldb驱动相关的,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
root@ceph-h ceph $ ceph daemon mon.ceph-h perf dump { ...... "leveldb": { "leveldb_get": 152780, "leveldb_transaction": 9036, "leveldb_compact": 0, "leveldb_compact_range": 52, "leveldb_compact_queue_merge": 0, "leveldb_compact_queue_len": 0 }, "paxos": { "start_leader": 1, "start_peon": 0, "restart": 2, "refresh": 4508, "refresh_latency": { "avgcount": 4508, "sum": 3.337180177 }, "begin": 4508, "begin_keys": { "avgcount": 4508, "sum": 13524 }, "begin_bytes": { "avgcount": 4508, "sum": 38377608 }, "begin_latency": { "avgcount": 4508, "sum": 17.555003073 }, "commit": 4508, "commit_keys": { "avgcount": 4508, "sum": 79235 }, "commit_bytes": { "avgcount": 4508, "sum": 36408263 }, "commit_latency": { "avgcount": 4508, "sum": 21997.951618865 }, "collect": 0, "collect_keys": { "avgcount": 0, "sum": 0 }, "collect_bytes": { "avgcount": 0, "sum": 0 }, "collect_latency": { "avgcount": 0, "sum": 0.000000000 }, "collect_uncommitted": 0, "collect_timeout": 0, "accept_timeout": 0, "lease_ack_timeout": 0, "lease_timeout": 0, "store_state": 0, "store_state_keys": { "avgcount": 0, "sum": 0 }, "store_state_bytes": { "avgcount": 0, "sum": 0 }, "store_state_latency": { "avgcount": 0, "sum": 0.000000000 }, "share_state": 0, "share_state_keys": { "avgcount": 0, "sum": 0 }, "share_state_bytes": { "avgcount": 0, "sum": 0 }, "new_pn": 0, "new_pn_latency": { "avgcount": 0, "sum": 0.000000000 } }, ...... } |
新版本:
1. 新版本mon增加了op tracker功能,类似osd的tracker,只能查看ops,看起来还没有增加类似osd的dump_historic_ops相关功能(src\mon\MonOpRequest.h:mark_paxos_event、mark_pgmon_event等)
2. rocksdb驱动增加了一些perf统计信息,可以参考加到leveldb驱动中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
root@ceph-l ~ $ ceph daemon mon.ceph-l perf dump { ...... "rocksdb": { "get": 256764600, "submit_transaction": 0, "submit_transaction_sync": 13880226, "get_latency": { "avgcount": 256764600, "sum": 7625.870714090, "avgtime": 0.000029699 }, "submit_latency": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "submit_sync_latency": { "avgcount": 13880226, "sum": 91084.274849052, "avgtime": 0.006562160 }, "compact": 0, "compact_range": 82448, "compact_queue_merge": 0, "compact_queue_len": 0, "rocksdb_write_wal_time": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "rocksdb_write_memtable_time": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "rocksdb_write_delay_time": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "rocksdb_write_pre_and_post_time": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 } }, "paxos": { "start_leader": 1, "start_peon": 0, "restart": 2, "refresh": 6939725, "refresh_latency": { "avgcount": 6939725, "sum": 8892.678683618, "avgtime": 0.001281416 }, "begin": 6939725, "begin_keys": { "avgcount": 6939725, "sum": 20819175 }, "begin_bytes": { "avgcount": 6939725, "sum": 15101835253 }, "begin_latency": { "avgcount": 6939725, "sum": 49779.761706707, "avgtime": 0.007173160 }, "commit": 6939725, "commit_keys": { "avgcount": 6939725, "sum": 41516240 }, "commit_bytes": { "avgcount": 6939725, "sum": 13912741993 }, "commit_latency": { "avgcount": 6939725, "sum": 42318.138247833, "avgtime": 0.006097956 }, "collect": 0, "collect_keys": { "avgcount": 0, "sum": 0 }, "collect_bytes": { "avgcount": 0, "sum": 0 }, "collect_latency": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "collect_uncommitted": 0, "collect_timeout": 0, "accept_timeout": 0, "lease_ack_timeout": 0, "lease_timeout": 0, "store_state": 0, "store_state_keys": { "avgcount": 0, "sum": 0 }, "store_state_bytes": { "avgcount": 0, "sum": 0 }, "store_state_latency": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 }, "share_state": 0, "share_state_keys": { "avgcount": 0, "sum": 0 }, "share_state_bytes": { "avgcount": 0, "sum": 0 }, "new_pn": 0, "new_pn_latency": { "avgcount": 0, "sum": 0.000000000, "avgtime": 0.000000000 } }, ...... } |
日志补充方案
- 参考新版本rocksdb补充leveldb相关perf计数器数据
- 增加单次leveldb落盘操作阈值配置项,超出阈值的操作打印日志
- 增加osd alive、boot重点消息的回复日志(根据接收到消息的时间戳计算monitor服务耗时,耗时超过预设阈值的消息才打印)
- Paxos决议流程增加多个monitor之间交互的日志(耗时超过一定阈值的才打印)
线上waitupthru耗时20多秒问题分析
针对线上环境waitupthru耗时长达20+s的问题,根据代码流程分析,有两个怀疑的点:
1. leveldb落盘较慢,串行操作场景多次决议加落盘导致后面的提案阻塞 — 可能性低,因为已经更换ssd盘,并且根据perf dump统计5s内Paxos平均commit耗时并不长(100+ms),commit次数也不高(10次左右)
2. 多个monitor之间交互耗时较长,leader等待peon accept后才能commit — 可能性相对较高,怀疑是受dispatch线程影响(pg、osd、log等需要决议的提案或者执行的命令数量太多,来不及处理?)
3. 上述两种情况叠加导致
当前可以优化的监控项
- 在之前的mon Paxos perf监控基础上补充更多监控项,例如begin阶段、store阶段等的耗时,dispatch线程throttle情况、leveldb相关数据等