2020-09-24更新
这两天又遇到了类似问题,也是initiated阶段耗时特别长,几秒到几十秒,就怀疑是这个问题,打开debug_optracker=5,果然还是all_read耗时很长,找到卷所在的虚拟机以及虚拟机所在的计算节点,然后跟osd节点互ping 4k大包,结果如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PING 10.206.9.218 (10.206.9.218) 4096(4124) bytes of data. [1600917968.613606] 4104 bytes from 10.206.9.218: icmp_seq=1 ttl=64 time=0.100 ms [1600917969.613885] 4104 bytes from 10.206.9.218: icmp_seq=2 ttl=64 time=0.084 ms [1600917970.612930] 4104 bytes from 10.206.9.218: icmp_seq=3 ttl=64 time=0.123 ms wrong data byte #720 should be 0xd0 but was 0xd1 #16 10 11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20 21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f #48 30 31 32 33 34 35 36 37 38 39 3a 3b 3c 3d 3e 3f 40 41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f #80 50 51 52 53 54 55 56 57 58 59 5a 5b 5c 5d 5e 5f 60 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f #112 70 71 72 73 74 75 76 77 78 79 7a 7b 7c 7d 7e 7f 80 81 82 83 84 85 86 87 88 89 8a 8b 8c 8d 8e 8f #144 90 91 92 93 94 95 96 97 98 99 9a 9b 9c 9d 9e 9f a0 a1 a2 a3 a4 a5 a6 a7 a8 a9 aa ab ac ad ae af #176 b0 b1 b2 b3 b4 b5 b6 b7 b8 b9 ba bb bc bd be bf c0 c1 c2 c3 c4 c5 c6 c7 c8 c9 ca cb cc cd ce cf #208 d0 d1 d2 d3 d4 d5 d6 d7 d8 d9 da db dc dd de df e0 e1 e2 e3 e4 e5 e6 e7 e8 e9 ea eb ec ed |
网络问题原因还在分析中。
问题症状
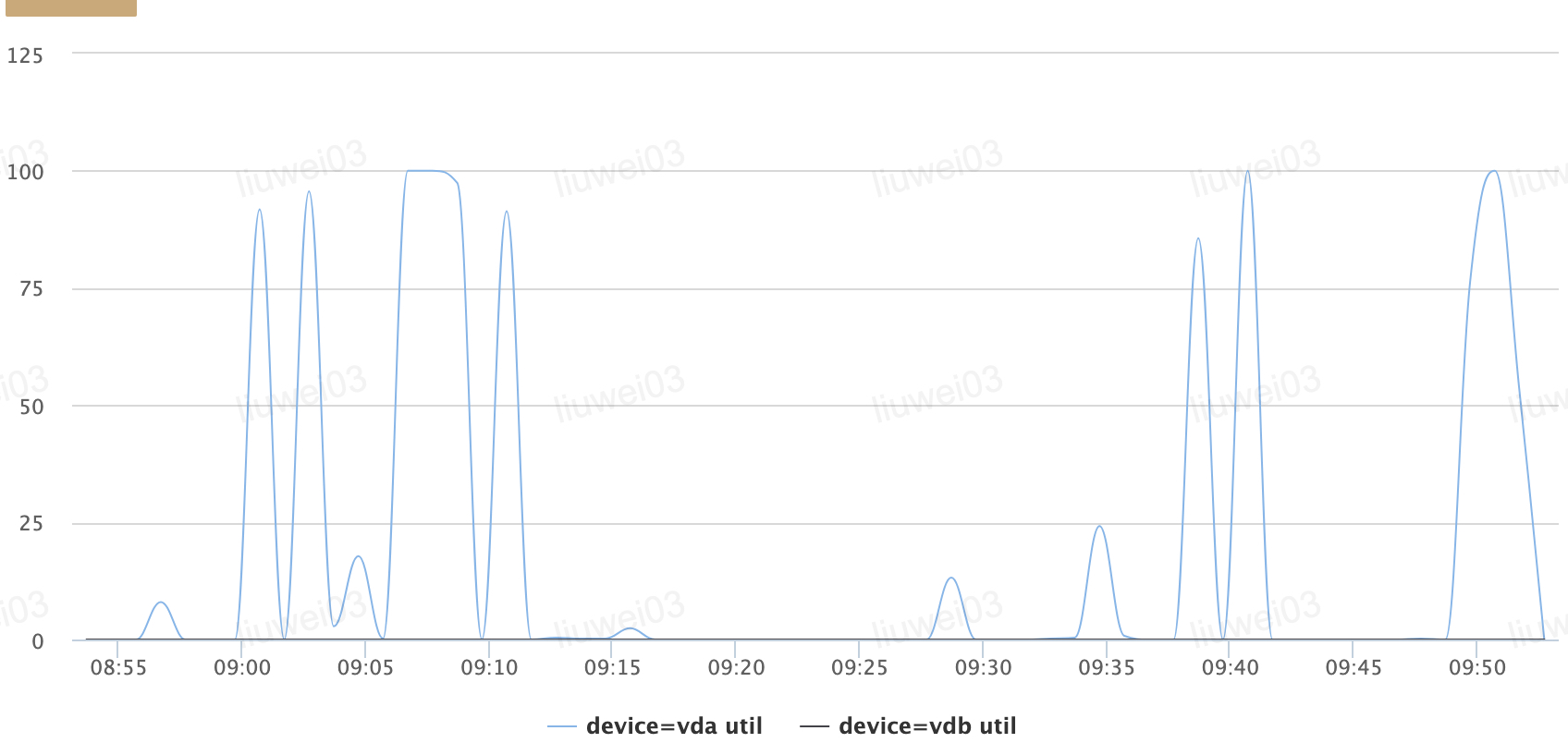
popo群用户报障,hzabj-ysf-nginx-08.server.163.org这台机器IO总是100%,哨兵监控截图如下:
初步分析
首先查看打桩卷监控,根据历史日志(日志是我之前修改librados代码加上的)可以了解这个物理池经常有超过3s的IO(一般我们认为超过3s就会导致io util 100%):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
2019-06-01 17:25:19.993596 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000085, pool: 59 2019-06-01 18:09:57.595608 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000069, pool: 59 2019-06-01 18:16:20.702047 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000a7, pool: 59 2019-06-01 19:54:51.239482 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000054, pool: 59 2019-06-01 19:56:35.497817 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000085, pool: 59 2019-06-01 19:57:02.986602 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000a7, pool: 59 2019-06-01 19:57:54.665901 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000a6, pool: 59 2019-06-01 20:00:59.491391 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000cb, pool: 59 2019-06-01 22:05:23.637840 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000a6, pool: 59 2019-06-01 22:46:59.814315 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.000000000000002b, pool: 59 2019-06-01 22:47:03.845807 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000cb, pool: 59 2019-06-02 00:07:14.823514 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000085, pool: 59 2019-06-02 00:09:12.176502 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000079, pool: 59 2019-06-02 00:09:42.964805 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.0000000000000076, pool: 59 2019-06-02 00:10:05.854999 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000cb, pool: 59 2019-06-02 00:11:20.025895 7fe9967fc700 0 client.824171177.objecter [slow op] critical(>3s), object name: rbd_data.10587c6b8b4567.00000000000000a5, pool: 59 |
通过这个日志就基本可以排除是用户自己磁盘IO繁忙导致的util 100%了。
否则就要先确认用户自己的IO繁忙程度,可以看下哨兵监控(根据主机名前缀搜索一般能搜到)或者找NVS组查看云主机磁盘监控信息,如果本身已经比较繁忙,比如达到了云盘的QoS限制(iops、bps),那首先怀疑他们业务的问题导致的100%。
进一步分析
之前这个存储池的打桩卷已经偶有告警,一直误以为是存储池比较繁忙导致的,因此首先看了下物理池上的2个逻辑池的负载,看起来不忙(对ssd pool来说不到5千的iops应该算比较空闲了)。
|
1 2 3 4 5 6 7 8 |
xxx@ceph146:~$ ceph osd pool stats | egrep 'switch12_ssd_vms|switch16_ssd_vms' -A1 pool switch12_ssd_vms id 46 client io 75986 B/s rd, 41106 kB/s wr, 2623 op/s -- pool switch16_ssd_vms id 59 client io 125 kB/s rd, 68879 kB/s wr, 1786 op/s |
之后根据打桩卷日志中的对象进行分析,可以看出还是有一定的规律的,就是告警的对象有很多重复,所以就怀疑跟特定pg或者osd有关,但有不能肯定,因为经过ceph osd map查看对应的osd,还是比较分散的。
再进一步就是查看ceph.log及ceph-osd.log,结果是一无所获,没有有效日志。
之后就是怀疑有慢盘,查看osd的perf dump信息,分析osd的journal相关延时,发现比较正常,但op_w_latency比较高,说明盘ok,但是op就是处理的慢,看物理机的基础监控也ok。
此时就比较棘手了。
只能打开osd_enable_op_tracker = true这个配置项并重启osd了,重启osd也要挑一个重点怀疑的对象,挑选比较简单,就是根据打桩卷的告警中的对象对应的osd,查看哪个osd被对应的次数最多,就挑他先重启打开。
|
1 2 |
for i in `cat xxx`; do ceph osd map switch16_ssd_vms $i >> yyy; done |
其中xxx就是所有打桩卷日志中告警的对象名称列表。
然后截取yyy中的osd列表,进行排序,查看最多出现的那个osd。
挑选的osd是osd.1908,之后提at单进行重启(先手工修改/etc/ceph/ceph.conf中的配置项:osd_enable_op_tracker = true),之后重启这个osd,重启过程比较平稳,没有造成抖动(一般来说停止启动间隔时间比较短的情况下都不会造成明显抖动)。
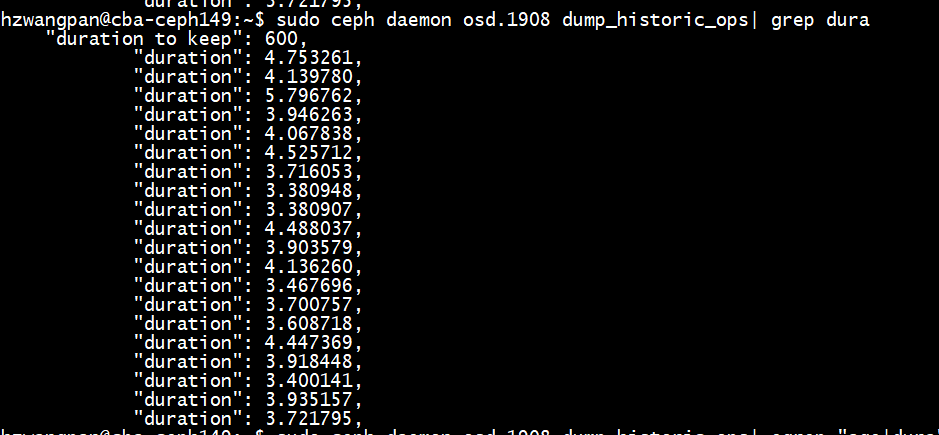
重启之后就等着问题出来就行,tailf看着打桩卷的日志,发现有超过3s的就对osd.1908执行sudo ceph daemon osd.1908 dump_historic_ops命令查看op耗时,发现有很多op是在等其他副本返回(sub_op_commit_rec这个事件比较耗时)。
可惜的是H版本没有把这个事件对应的osd id打印出来(L版本已加,已经pick到我们的H版本),无从知晓是哪个副本osd返回慢,于是只能挑选出现比较频繁的osd(两个副本)都继续打开osd_enable_op_tracker并重启osd。
重启之后看到repop的耗时也比较长,但耗时的阶段比较奇怪(在reached_pg之前,这个是dequeue_op的第一个阶段):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "description": "osd_repop(client.893650048.0:2152251 46.235 91c5c235\/rbd_data.25f087ae6b8b4567.0000000000000358\/head\/\/46 v 116247'52196234)", "initiated_at": "2019-06-03 13:53:22.152573", "age": 396.997140, "duration": 2.345648, "type_data": [ "commit sent; apply or cleanup", [ { "time": "2019-06-03 13:53:22.152573", "event": "initiated" }, { "time": "2019-06-03 13:53:24.482251", "event": "reached_pg" }, |
但是还不清楚具体是在enqueue_op还是dequeue_op阶段比较慢。于是只能打开osd日志(debug_osd=15),查看具体慢在哪里,日志看到耗时确实在enqueue的时候就比较长:
|
1 2 3 4 5 6 7 8 9 10 11 |
2019-06-03 16:23:00.097107 7fde12cfa700 10 osd.1854 116251 handle_replica_op osd_repop(client.896864302.0:1498545 59.17a f41cf17a/rbd_data.1906c95d6b8b4567.0000000000 0038f0/head//59 v 116251'18143050) v1 epoch 116251 2019-06-03 16:23:00.097115 7fde12cfa700 15 osd.1854 116251 enqueue_op 0x7fddf4813b00 prio 127 cost 3793664 latency 1.542532 osd_repop(client.896864302.0:1498545 59.17 a f41cf17a/rbd_data.1906c95d6b8b4567.00000000000038f0/head//59 v 116251'18143050) v1 2019-06-03 16:23:00.097131 7fde269e6700 10 osd.1854 116251 dequeue_op 0x7fddf4813b00 prio 127 cost 3793664 latency 1.542548 osd_repop(client.896864302.0:1498545 59.17 a f41cf17a/rbd_data.1906c95d6b8b4567.00000000000038f0/head//59 v 116251'18143050) v1 pg pg[59.17a( v 116251'18143049 (116247'18140009,116251'18143049] local-les=11624 7 n=1427 ec=10414 les/c 116247/116247 116246/116246/67102) [1909,1942,1854] r=2 lpr=116246 pi=65962-116245/7 luod=0'0 crt=116251'18143047 lcod 116251'18143048 active] 2019-06-03 16:23:00.097165 7fde269e6700 10 osd.1854 pg_epoch: 116251 pg[59.17a( v 116251'18143049 (116247'18140009,116251'18143049] local-les=116247 n=1427 ec=10414 l es/c 116247/116247 116246/116246/67102) [1909,1942,1854] r=2 lpr=116246 pi=65962-116245/7 luod=0'0 crt=116251'18143047 lcod 116251'18143048 active] handle_message: 0x 7fddf4813b00 |
另外通过日志还确认了一点,只有osd_repop才enqueue比较慢,正常的osd_op都没问题(二者入队的队列都是同一个)。
通过在开发环境gdb调试确认二者的处理流程没有区别:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
(gdb) bt #0 OSD::enqueue_op (this=this@entry=0x4be6000, pg=0xbc74c00, op=std::tr1::shared_ptr (count 2, weak 0) 0x4ab5100) at osd/OSD.cc:8470 #1 0x00000000006a08aa in OSD::handle_replica_op<mosdrepop , 112> (this=this@entry=0x4be6000, op=std::tr1::shared_ptr (count 2, weak 0) 0x4ab5100, ### osd_op这里是走handle_op osdmap=std::tr1::shared_ptr (count 72, weak 1) 0x1149d680) at osd/OSD.cc:8448 #2 0x000000000065704e in OSD::dispatch_op_fast (this=this@entry=0x4be6000, op=std::tr1::shared_ptr (count 2, weak 0) 0x4ab5100, osdmap=std::tr1::shared_ptr (count 72, weak 1) 0x1149d680) at osd/OSD.cc:5839 #3 0x00000000006571a8 in OSD::dispatch_session_waiting (this=this@entry=0x4be6000, session=session@entry=0x4b3a800, osdmap=std::tr1::shared_ptr (count 72, weak 1) 0x1149d680) at osd/OSD.cc:5473 #4 0x00000000006575c0 in OSD::ms_fast_dispatch (this=0x4be6000, m=<optimized out>) at osd/OSD.cc:5585 #5 0x0000000000bddd9e in ms_fast_dispatch (m=0x11de2400, this=0x4ae4700) at ./msg/Messenger.h:553 #6 DispatchQueue::fast_dispatch (this=0x4ae48c8, m=0x11de2400) at msg/simple/DispatchQueue.cc:71 #7 0x0000000000c0b543 in Pipe::reader (this=0x126d0000) at msg/simple/Pipe.cc:1645 #8 0x0000000000c1384d in Pipe::Reader::entry (this=</optimized><optimized out>) at msg/simple/Pipe.h:50 #9 0x00007fc06b25d064 in start_thread (arg=0x7fc046880700) at pthread_create.c:309 #10 0x00007fc0697b562d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:111 |
这就更奇怪了,enqueue_op其实做的事情非常简单,就是把op丢到osd的op处理队列就返回了,cpu也不忙,内存也剩余非常多,没理由这么慢,但通过日志可以确认慢的过程肯定在上面的调用栈里面。
首先怀疑是pg锁导致的问题,但还是有点疑问,业务并不繁忙,每个op正常应该处理很快,pg锁应该不会占用太长时间,当然除非是有bug。
问题分析到这里基本就有点郁闷了。只能继续撸代码看看有没有可以进一步打开的日志供我们确认问题。
还好有op tracker,我之前在基于它增加日志的时候,看到了一些日志可以打出来,我想看的日志是op什么时候收到的,什么时候分发的,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
OpRequest::OpRequest(Message *req, OpTracker *tracker) : TrackedOp(tracker, req->get_recv_stamp()), rmw_flags(0), request(req), hit_flag_points(0), latest_flag_point(0), send_map_update(false), sent_epoch(0) { if (req->get_priority() < tracker->cct->_conf->osd_client_op_priority) { // don't warn as quickly for low priority ops warn_interval_multiplier = tracker->cct->_conf->osd_recovery_op_warn_multiple; } if (req->get_type() == CEPH_MSG_OSD_OP) { reqid = static_cast<mosdop *>(req)->get_reqid(); } else if (req->get_type() == MSG_OSD_SUBOP) { reqid = static_cast<mosdsubop *>(req)->reqid; } else if (req->get_type() == MSG_OSD_REPOP) { reqid = static_cast<mosdrepop *>(req)->reqid; } tracker->mark_event(this, "header_read", request->get_recv_stamp()); // 就是这几条日志救了命,这里只是打日志,并没有记录到historic ops tracker->mark_event(this, "throttled", request->get_throttle_stamp()); tracker->mark_event(this, "all_read", request->get_recv_complete_stamp()); tracker->mark_event(this, "dispatched", request->get_dispatch_stamp()); |
于是我把op tracker日志级别调到5(debug_optracker=5),日志就出来了:
|
1 2 3 |
2019-06-03 17:11:45.489452 7fde166fe700 5 -- op tracker -- seq: 2757941, time: 2019-06-03 17:11:43.689630, event: throttled, op: osd_repop(client.689719056.0:69702497 59.1c7 913ee9c7/rbd_data.2bd4c3681befd79f.0000000000000fbc/head//59 v 116251'17079367) 2019-06-03 17:11:45.489457 7fde166fe700 5 -- op tracker -- seq: 2757941, time: 2019-06-03 17:11:45.489414, event: all_read, op: osd_repop(client.689719056.0:69702497 59.1c7 913ee9c7/rbd_data.2bd4c3681befd79f.0000000000000fbc/head//59 v 116251'17079367) |
可以明显看到是慢在从throttled到all_read这段时间,这部分代码是在src\msg\simple\Pipe.cc的Pipe::read_message里:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// read front front_len = header.front_len; if (front_len) { bufferptr bp = buffer::create(front_len); if (tcp_read(bp.c_str(), front_len) < 0) goto out_dethrottle; front.push_back(bp); ldout(msgr->cct,20) < < "reader got front " << front.length() << dendl; } // read middle middle_len = header.middle_len; if (middle_len) { bufferptr bp = buffer::create(middle_len); if (tcp_read(bp.c_str(), middle_len) < 0) goto out_dethrottle; middle.push_back(bp); ldout(msgr->cct,20) < < "reader got middle " << middle.length() << dendl; } |
都是tcp_read相关操作,于是怀疑是cluster网络问题,也解释了为啥之后repop慢(它走的cluster网,而主osd处理的op则走的是public网),看起来离真相越来越近了。
之后通过ping 10.122.192.146 -s 4096 测试cluster网络,发现有异常:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
4104 bytes from 10.122.192.146: icmp_seq=88 ttl=64 time=0.082 ms From 10.122.192.146 icmp_seq=58 Frag reassembly time exceeded 4104 bytes from 10.122.192.146: icmp_seq=89 ttl=64 time=0.075 ms 4104 bytes from 10.122.192.146: icmp_seq=90 ttl=64 time=0.084 ms 4104 bytes from 10.122.192.146: icmp_seq=91 ttl=64 time=0.080 ms 4104 bytes from 10.122.192.146: icmp_seq=92 ttl=64 time=0.084 ms 4104 bytes from 10.122.192.146: icmp_seq=93 ttl=64 time=0.079 ms 4104 bytes from 10.122.192.146: icmp_seq=94 ttl=64 time=0.078 ms 4104 bytes from 10.122.192.146: icmp_seq=95 ttl=64 time=0.081 ms From 10.122.192.146 icmp_seq=65 Frag reassembly time exceeded 4104 bytes from 10.122.192.146: icmp_seq=96 ttl=64 time=0.088 ms |

于是找sa查看网络是否有问题,sa经过猜测,认为是bond的一个网卡有问题,就停掉一个eth0试验,观察一晚上没问题,问题解决了。
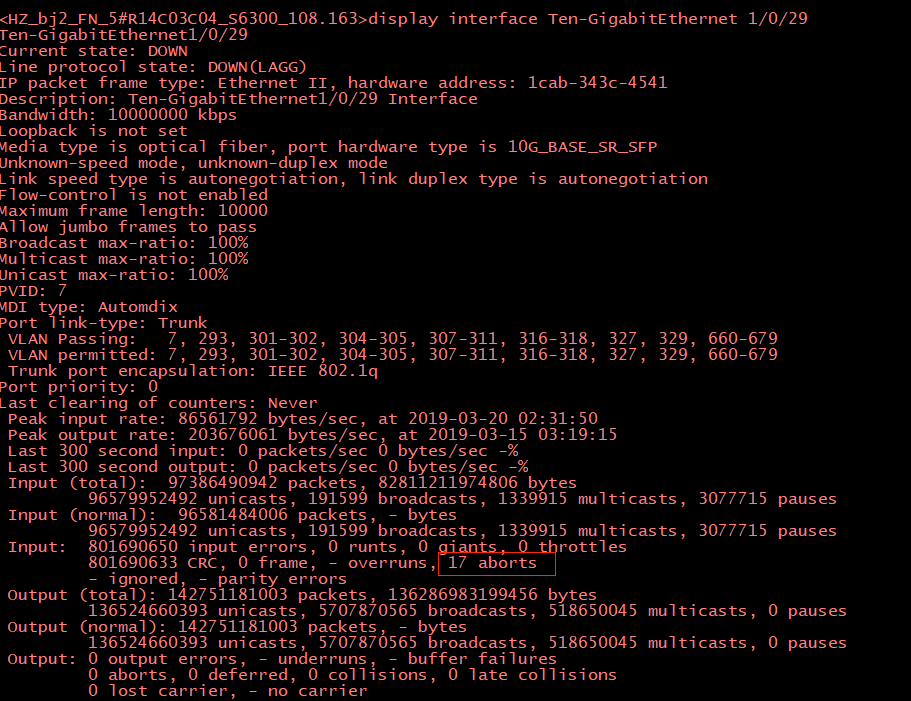
但问题的根本原因还是没有找到,于是第二天再次把eth0网卡up起来,跑了一天还是正常的。目前还没有找到问题出在哪儿,哨兵上查看网卡监控都是正常的。
只是机房给出的交换机信息里有异常(大量input errors和17个aborts),但也没能解释出现这些错误的原因: