admin socket
client及server、osd及mon
|
1 2 3 4 5 6 7 8 9 10 |
# /var/run/ceph srwxr-xr-x 1 root root 0 Jul 17 14:01 ceph-client.admin.21723.24796272.asok srwxr-xr-x 1 root root 0 Jul 29 10:30 ceph-client.admin.2583.54700240.asok srwxr-xr-x 1 root root 0 Jul 29 10:30 ceph-client.admin.2583.55071360.asok srwxr-xr-x 1 root root 0 Jul 29 16:45 ceph-mon.ceph-l.asok srwxr-xr-x 1 root root 0 Jul 29 17:09 ceph-osd.0.asok srwxr-xr-x 1 root root 0 Jul 29 16:44 ceph-osd.1.asok srwxr-xr-x 1 root root 0 Jul 29 16:44 ceph-osd.2.asok srwxr-xr-x 1 root root 0 Jul 29 16:44 ceph-osd.3.asok |
创建流程
注册命令hook函数
|
1 2 3 4 5 6 7 8 9 10 11 |
CephContext::CephContext(uint32_t module_type_) ... { ... _admin_socket = new AdminSocket(this); _admin_hook = new CephContextHook(this); _admin_socket->register_command("perf dump", "perf dump name=logger,type=CephString,req=false name=counter,type=CephString,req=false", _admin_hook, "dump perfcounters value"); ... _admin_socket->register_command("log reopen", "log reopen", _admin_hook, "reopen log file"); } |
线程创建及启动
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
// ceph_osd.cc:main->common_init_finish->start_service_thread->AdminSocket::init class AdminSocket : public Thread { public: AdminSocket(CephContext *cct); virtual ~AdminSocket(); ... } bool AdminSocket::init(const std::string &path) { ... err = create_shutdown_pipe(&pipe_rd, &pipe_wr); ... int sock_fd; err = bind_and_listen(path, &sock_fd); ... /* Create new thread */ m_sock_fd = sock_fd; m_shutdown_rd_fd = pipe_rd; m_shutdown_wr_fd = pipe_wr; m_path = path; m_version_hook = new VersionHook; register_command("0", "0", m_version_hook, ""); register_command("version", "version", m_version_hook, "get ceph version"); register_command("git_version", "git_version", m_version_hook, "get git sha1"); m_help_hook = new HelpHook(this); register_command("help", "help", m_help_hook, "list available commands"); m_getdescs_hook = new GetdescsHook(this); register_command("get_command_descriptions", "get_command_descriptions", m_getdescs_hook, "list available commands"); create(); // Thread::create add_cleanup_file(m_path.c_str()); return true; } |
命令处理
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// perfcounter hooks class CephContextHook : public AdminSocketHook { CephContext *m_cct; public: CephContextHook(CephContext *cct) : m_cct(cct) {} bool call(std::string command, cmdmap_t& cmdmap, std::string format, bufferlist& out) { m_cct->do_command(command, cmdmap, format, &out); return true; } }; void CephContext::do_command(std::string command, cmdmap_t& cmdmap, std::string format, bufferlist *out) { Formatter *f = Formatter::create(format, "json-pretty", "json-pretty"); stringstream ss; for (cmdmap_t::iterator it = cmdmap.begin(); it != cmdmap.end(); ++it) { if (it->first != "prefix") { ss < < it->first < < ":" << cmd_vartype_stringify(it->second) < < " "; } } lgeneric_dout(this, 1) << "do_command '" << command << "' '" << ss.str() << dendl; if (command == "perfcounters_dump" || command == "1" || command == "perf dump") { std::string logger; std::string counter; cmd_getval(this, cmdmap, "logger", logger); cmd_getval(this, cmdmap, "counter", counter); _perf_counters_collection->dump_formatted(f, false, logger, counter); } else if (command == "perfcounters_schema" || command == "2" || command == "perf schema") { _perf_counters_collection->dump_formatted(f, true); } ... } |
功能用途
查询版本/配置项信息/限流/性能计数器数据/reopen log/dump log/dump_mempools/dump_objectstore_kv_stats/dump_historic_ops等
使用场景举例:
Paxos耗时监控
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
hzwangpan@pubt2-ceph27:/usr/local/nagent/libexec$ sudo ceph daemon mon.pubt2-ceph27 perf dump paxos { "paxos": { ... "begin_latency": { "avgcount": 0, "sum": 0.000000000 }, "commit": 0, "commit_keys": { "avgcount": 0, "sum": 0 }, "commit_bytes": { "avgcount": 0, "sum": 0 }, "commit_latency": { "avgcount": 0, "sum": 0.000000000 }, ... } } |
peering耗时监控
|
1 2 3 4 5 6 7 8 9 10 11 |
hzwangpan@pubt2-ceph27:/usr/local/nagent/libexec$ sudo ceph daemon osd.1 perf dump recoverystate_perf | egrep "peering|waitup" -A3 "peering_latency": { "avgcount": 803, "sum": 88.156743622 }, -- "waitupthru_latency": { "avgcount": 0, "sum": 0.000000000 } |
overflow巡检脚本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
for mon in `ls /var/run/ceph/ceph-mon.*.asok`; do echo config set debug_ms=0/15 for $mon sudo ceph --admin-daemon $mon config set debug_ms 0/15 done sleep 5 for mon in `ls /var/run/ceph/ceph-mon.*.asok`; do echo dump log for $mon sudo ceph --admin-daemon $mon log dump done sleep 2 for mon in `ls /var/run/ceph/ceph-mon.*.asok`; do echo config set debug_ms=0/5 for $mon sudo ceph --admin-daemon $mon config set debug_ms 0/5 done echo ==========WARNING MON start============== grep -H "got ack seq" /data/log/ceph/ceph-mon.*.log | grep " 15 -- " | awk '$NF>1073741824 {print $0}' | awk -F'ceph-|.log:' '{print $2}' | sort | uniq echo ==========WARNING MON end============== |
修改配置项
单实例配置项修改
|
1 2 |
ceph daemon osd.0 config set debug_ms 15 |
实现:参考上面的admin socket创建注册流程,会有针对config set命令的处理函数。
多实例配置项修改
|
1 2 |
ceph tell osd.* injectargs '--debug_ms=15' |
实现:
在/usr/bin/ceph中检测tell命令的后续参数,如果是指定了target(如osd.0)则直接发送injectargs message给osd.0,由osd进程的tp_osd_cmd线程调用do_command函数对其进行处理(L版本代码流程),之后调用md_config_t::injectargs进行实际的配置项修改,最后handle_conf_change执行配置项修改的side effect相关操作。
如果指定的是osd.*,则先通过mon获取所有osd id列表,然后对每个osd循环执行上面的操作。
性能分析相关
性能概览
ceph osd perf
查看osd的FileStore时延信息
|
1 2 3 4 5 6 7 |
root@ceph-l ceph $ ceph osd perf osd fs_commit_latency(ms) fs_apply_latency(ms) 0 65 72 1 27 36 2 22 31 3 0 0 |
ceph -s
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
hzwangpan@prit1-ceph19:~$ ceph -s cluster ee7b0372-f77e-4504-a4cf-4f5a3f503857 health HEALTH_WARN pool bigceph_jiande2_sas_vol01 has too few pgs monmap e1: 3 mons at {prit1-ceph19=10.198.136.19:6789/0,prit1-ceph20=10.198.136.20:6789/0,prit1-ceph21=10.198.136.21:6789/0} election epoch 36, quorum 0,1,2 prit1-ceph19,prit1-ceph20,prit1-ceph21 osdmap e12259: 267 osds: 267 up, 267 in pgmap v10782798: 8192 pgs, 9 pools, 12860 GB data, 3235 kobjects 38661 GB used, 417 TB / 454 TB avail 8182 active+clean 10 active+clean+scrubbing+deep client io 57582 kB/s rd, 14104 kB/s wr, 2831 op/s |
ceph osd pool stat
|
1 2 3 4 5 6 7 8 9 10 11 |
// 没有物理池级别统计 hzwangpan@prit1-ceph19:~$ ceph osd pool stats pool bigceph_jiande2_sas_vol01 id 4 client io 56782 kB/s rd, 15450 kB/s wr, 2498 op/s pool bigceph_jiande2_ssd_vol01 id 5 client io 77283 B/s rd, 6136 kB/s wr, 1846 op/s pool data02_bigdata_ssd_vol01 id 7 nothing is going on |
这些数据是由osd定期上报给mon(OSD::tick->OSD::do_mon_report->OSD::send_pg_stats:m->osd_stat),然后mon直接dump出来即可,不是特别实时。
perf counter
perf counter的初始化过程
代码流程:ceph_osd.cc:main->OSD::init->OSD::create_recoverystate_perf/OSD::create_logger
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
// OSD.h enum { l_osd_first = 10000, l_osd_op_wip, l_osd_op, l_osd_op_inb, l_osd_op_outb, l_osd_op_lat, ... }; void OSD::create_logger() { dout(10) < < "create_logger" << dendl; PerfCountersBuilder osd_plb(cct, "osd", l_osd_first, l_osd_last); osd_plb.add_u64(l_osd_op_wip, "op_wip"); // rep ops currently being processed (primary) osd_plb.add_u64_counter(l_osd_op, "op"); // client ops ... logger = osd_plb.create_perf_counters(); cct->get_perfcounters_collection()->add(logger); } void OSD::create_recoverystate_perf() { dout(10) < < "create_recoverystate_perf" << dendl; PerfCountersBuilder rs_perf(cct, "recoverystate_perf", rs_first, rs_last); ... rs_perf.add_time_avg(rs_peering_latency, "peering_latency"); ... rs_perf.add_time_avg(rs_getmissing_latency, "getmissing_latency"); rs_perf.add_time_avg(rs_waitupthru_latency, "waitupthru_latency"); recoverystate_perf = rs_perf.create_perf_counters(); cct->get_perfcounters_collection()->add(recoverystate_perf); } void PerfCountersBuilder::add_time_avg(int idx, const char *name) { add_impl(idx, name, PERFCOUNTER_TIME | PERFCOUNTER_LONGRUNAVG); } |
- add_u64/add_u64_counter:累加值
|
1 2 3 4 |
root@ceph-l ceph $ ceph daemon osd.0 perf dump | grep op_wip -A3 "op_wip": 0, "op": 679522, |
- add_u64_avg:总/平均值
|
1 2 3 4 5 6 |
root@ceph-l ceph $ ceph daemon osd.0 perf dump | grep journal_wr_bytes -A3 "journal_wr_bytes": { "avgcount": 414183, "sum": 11194507264 }, |
- add_time:累加值
|
1 2 3 4 5 6 7 |
} else if (d->type & PERFCOUNTER_TIME) { f->dump_format_unquoted(d->name, "%" PRId64 ".%09" PRId64, v / 1000000000ull, // 秒 v % 1000000000ull); // 毫秒 } // 结果类似"sum": 123.450000000 |
- add_time_avg:平均值
|
1 2 3 4 5 6 |
root@ceph-l ceph $ ceph daemon osd.0 perf dump | grep op_r_latency -A3 "op_r_latency": { "avgcount": 1234, "sum": 10.300000000 }, |
perf counter使用方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
void ReplicatedPG::log_op_stats(OpContext *ctx) { OpRequestRef op = ctx->op; MOSDOp *m = static_cast<mosdop *>(op->get_req()); utime_t now = ceph_clock_now(cct); utime_t latency = now; latency -= ctx->op->get_req()->get_recv_stamp(); utime_t process_latency = now; process_latency -= ctx->op->get_dequeued_time(); utime_t rlatency; if (ctx->readable_stamp != utime_t()) { rlatency = ctx->readable_stamp; rlatency -= ctx->op->get_req()->get_recv_stamp(); } uint64_t inb = ctx->bytes_written; uint64_t outb = ctx->bytes_read; osd->logger->inc(l_osd_op); osd->logger->inc(l_osd_op_outb, outb); ... osd->logger->tinc(l_osd_op_process_lat, process_latency); if (op->may_read() && op->may_write()) { ... } else if (op->may_read()) { osd->logger->inc(l_osd_op_r); ... osd->logger->tinc(l_osd_op_r_process_lat, process_latency); } ... } void PerfCounters::tinc(int idx, utime_t amt) { if (!m_cct->_conf->perf) return; assert(idx > m_lower_bound); assert(idx < m_upper_bound); perf_counter_data_any_d& data(m_data[idx - m_lower_bound - 1]); if (!(data.type & PERFCOUNTER_TIME)) return; if (data.type & PERFCOUNTER_LONGRUNAVG) { data.avgcount.inc(); data.u64.add(amt.to_nsec()); data.avgcount2.inc(); } else { data.u64.add(amt.to_nsec()); } } |
perf counter结果获取
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
void PerfCounters::dump_formatted(Formatter *f, bool schema, const std::string &counter) { f->open_object_section(m_name.c_str()); for (perf_counter_data_vec_t::const_iterator d = m_data.begin(); d != m_data.end(); ++d) { ... if (schema) { f->open_object_section(d->name); f->dump_int("type", d->type); f->close_section(); } else { if (d->type & PERFCOUNTER_LONGRUNAVG) { f->open_object_section(d->name); pair<uint64_t ,uint64_t> a = d->read_avg(); if (d->type & PERFCOUNTER_U64) { f->dump_unsigned("avgcount", a.second); f->dump_unsigned("sum", a.first); } else if (d->type & PERFCOUNTER_TIME) { f->dump_unsigned("avgcount", a.second); f->dump_format_unquoted("sum", "%" PRId64 ".%09" PRId64, a.first / 1000000000ull, a.first % 1000000000ull); ... } |
举例:peering各阶段耗时、写journal耗时、慢盘检查等
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
hzwangpan@prit1-ceph20:~$ sudo ceph daemon osd.10 perf dump | egrep "peering|getinfo|getlog|getmiss|waitup" -A3 "peering_latency": { "avgcount": 240, "sum": 12.630200202 }, -- "getinfo_latency": { "avgcount": 240, "sum": 7.091297764 }, "getlog_latency": { "avgcount": 187, "sum": 4.670226353 }, -- "getmissing_latency": { "avgcount": 187, "sum": 0.861913789 }, "waitupthru_latency": { "avgcount": 0, "sum": 0.000000000 } hzwangpan@prit1-ceph20:~$ sudo ceph daemon osd.10 perf dump | egrep "journal_latency" -A3 "journal_latency": { "avgcount": 500990, "sum": 128.696573903 }, hzwangpan@prit1-ceph20:~$ sudo ceph daemon osd.10 perf dump | egrep "aio_" -A3 "aio_usual_lat": { "avgcount": 479092, "sum": 72.261508449 }, "aio_unusual_lat": { "avgcount": 0, "sum": 0.000000000 }, "aio_slow_lat": { "avgcount": 0, "sum": 0.000000000 }, |
op tracker
op tracker初始化
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
OSD::OSD(CephContext *cct_, ObjectStore *store_, ... op_tracker(cct, cct->_conf->osd_enable_op_tracker, // 默认true cct->_conf->osd_num_op_tracker_shard), // 默认32 ... { ... op_tracker.set_complaint_and_threshold(cct->_conf->osd_op_complaint_time, cct->_conf->osd_op_log_threshold); op_tracker.set_history_size_and_duration(cct->_conf->osd_op_history_size, cct->_conf->osd_op_history_duration); ... } OpTracker(CephContext *cct_, bool tracking, uint32_t num_shards) : seq(0), num_optracker_shards(num_shards), complaint_time(0), log_threshold(0), tracking_enabled(tracking), cct(cct_) { // tracking_enabled不能动态修改,需要重启osd进程 for (uint32_t i = 0; i < num_optracker_shards; i++) { char lock_name[32] = {0}; snprintf(lock_name, sizeof(lock_name), "%s:%d", "OpTracker::ShardedLock", i); ShardedTrackingData* one_shard = new ShardedTrackingData(lock_name); sharded_in_flight_list.push_back(one_shard); } |
op事件记录
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
void OSD::ms_fast_dispatch(Message *m) { if (service.is_stopping()) { m->put(); return; } OpRequestRef op = op_tracker.create_request<oprequest>(m); // 创建op ... } struct OpRequest : public TrackedOp { friend class OpTracker; ... void mark_queued_for_pg() { mark_flag_point(flag_queued_for_pg, "queued_for_pg"); } void mark_reached_pg() { mark_flag_point(flag_reached_pg, "reached_pg"); } void mark_delayed(const string& s) { mark_flag_point(flag_delayed, s); } void mark_started() { mark_flag_point(flag_started, "started"); } void mark_sub_op_sent(const string& s) { mark_flag_point(flag_sub_op_sent, s); } void mark_commit_sent() { mark_flag_point(flag_commit_sent, "commit_sent"); } ... } void OpRequest::mark_flag_point(uint8_t flag, const string& s) { ... mark_event(s); ... } void ReplicatedBackend::op_commit( InProgressOp *op) { dout(10) < < __func__ << ": " << op->tid < < dendl; if (op->op) op->op->mark_event("op_commit"); ... } |
op事件查看
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
root@ceph1 ~ $ ceph daemon osd.0 dump_ops_in_flight { "ops": [ { "description": "osd_op(client.115363.0:416 6.3c 6:3faa4df8:::benchmark_data_ceph1_589633_object415:head [set-alloc-hint object_size 4194304 write_size 4194304,write 0~4194304] snapc 0=[] ondisk+write+known_if_redirected e337)", "initiated_at": "2019-07-30 21:31:38.924985", "age": 0.080449, "duration": 0.080484, "type_data": { "flag_point": "waiting for sub ops", "client_info": { "client": "client.115363", "client_addr": "192.168.0.2:0/176428539", "tid": 416 }, "events": [ { "time": "2019-07-30 21:31:38.924985", "event": "initiated" }, { "time": "2019-07-30 21:31:38.930980", "event": "queued_for_pg" }, { "time": "2019-07-30 21:31:38.931220", "event": "reached_pg" }, { "time": "2019-07-30 21:31:38.931922", "event": "started" }, { "time": "2019-07-30 21:31:38.932345", "event": "waiting for subops from 1" }, { "time": "2019-07-30 21:31:38.970683", "event": "sub_op_commit_rec from 1" } ] } }, ... root@ceph1 ~ $ ceph daemon osd.0 dump_historic_ops { "size": 20, "duration": 600, "ops": [ { "description": "osd_op(client.115364.0:18 6.11 6:89bb7b70:::benchmark_data_ceph1_589885_object17:head [set-alloc-hint object_size 4194304 write_size 4194304,write 0~4194304] snapc 0=[] ondisk+write+known_if_redirected e337)", "initiated_at": "2019-07-30 21:58:08.250964", "age": 1.486169, "duration": 0.111498, "type_data": { "flag_point": "commit sent; apply or cleanup", "client_info": { "client": "client.115364", "client_addr": "192.168.0.2:0/3144333915", "tid": 18 }, "events": [ { "time": "2019-07-30 21:58:08.250964", "event": "initiated" }, { "time": "2019-07-30 21:58:08.253853", "event": "queued_for_pg" }, { "time": "2019-07-30 21:58:08.253941", "event": "reached_pg" }, { "time": "2019-07-30 21:58:08.254432", "event": "started" }, { "time": "2019-07-30 21:58:08.256617", "event": "waiting for subops from 1" }, { "time": "2019-07-30 21:58:08.317819", "event": "sub_op_commit_rec from 1" }, { "time": "2019-07-30 21:58:08.361995", "event": "op_commit" }, { "time": "2019-07-30 21:58:08.362093", "event": "commit_sent" }, { "time": "2019-07-30 21:58:08.362126", "event": "op_applied" }, { "time": "2019-07-30 21:58:08.362462", "event": "done" } ] } }, ... |
slow request达到阈值也会打印到日志里。
基于op tracker的slow op日志改进
痛点:op history无法长期保存
解决方法:修改代码,把耗时较长的op history信息持久化到日志文件
2019-04-26 06:25:05.454228 7f0ac2c17700 0 — op tracker — slow op: osd_op(client.544152.0:3674314 rbd_data.2af5f6b8b4567.0000000000000065 [write 961608~4096] 0.8c5714c5 snapc 5=[] ondisk+write+known_if_redirected e57939), start at: 2019-04-26 06:25:05.343005, duration: 0.111196, history: (0ms: initiated) (0ms: queued_for_pg) (0ms: reached_pg) (0ms: started) (0ms: waiting for subops from 1,2) (23ms: commit_queued_for_journal_write) (43ms: write_thread_in_journal_buffer) (38ms: sub_op_commit_rec) (0ms: filestore_queued_op) (0ms: journaled_completion_queued) (0ms: op_commit) (0ms: sub_op_commit_rec) (4ms: commit_sent) (0ms: filestore_do_op) (0ms: filestore_do_op_end) (0ms: op_applied) (0ms: done)
举例:线上IO抖动问题分析
blkin+lttng
举例:rbd卷读写全链路时延分析
tcmalloc支持
ceph tell osd.0 heap start_profiler/dump/stats/release
举例:L版本EC OSD内存占用分析
mempool(L版本)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
root@ceph1 ~ $ ceph daemon osd.0 dump_mempools { ... "bluestore_alloc": { "items": 512, "bytes": 512 }, "bluestore_cache_data": { "items": 3, "bytes": 12288 }, "bluestore_cache_onode": { "items": 879, "bytes": 590688 }, "bluestore_cache_other": { "items": 96422, "bytes": 2844381 }, ... "bluestore_writing": { "items": 2, "bytes": 8388608 }, "bluefs": { "items": 90, "bytes": 5496 }, ... "osd": { "items": 64, "bytes": 773632 }, "osd_mapbl": { "items": 0, "bytes": 0 }, "osd_pglog": { "items": 643642, "bytes": 308785360 }, "osdmap": { "items": 245, "bytes": 18752 }, "osdmap_mapping": { "items": 0, "bytes": 0 }, "pgmap": { "items": 0, "bytes": 0 }, ... "total": { "items": 741904, "bytes": 323610213 } } |
打开debug开关可以dump更详细的信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
root@ceph1 ~ $ ceph daemon osd.0 config get mempool_debug { "mempool_debug": "false" } root@ceph1 ~ $ ceph daemon osd.0 config set mempool_debug true { "success": "mempool_debug = 'true' osd_objectstore = 'bluestore' (not observed, change may require restart) rocksdb_separate_wal_dir = 'false' (not observed, change may require restart) " } root@ceph1 ~ $ ceph daemon osd.0 dump_mempools { "bloom_filter": { "items": 0, "bytes": 0, "by_type": { "unsigned char": { "items": 0, "bytes": 0 } } }, "bluestore_alloc": { "items": 512, "bytes": 512, "by_type": { "BitAllocator": { "items": 0, "bytes": 0 }, "BitMapArea": { "items": 0, "bytes": 0 }, "BitMapAreaIN": { "items": 0, "bytes": 0 }, "BitMapAreaLeaf": { "items": 0, "bytes": 0 }, "BitMapZone": { "items": 0, "bytes": 0 }, "BmapEntry": { "items": 0, "bytes": 0 } } }, "bluestore_cache_data": { "items": 3, "bytes": 12288 }, "bluestore_cache_onode": { "items": 879, "bytes": 590688, "by_type": { "BlueStore::Onode": { "items": 879, "bytes": 590688 } } }, ... |
mempool介绍
在src\include\mempool.h头文件里有详细的使用方法介绍。引入mempool的主要目的是统计内存占用情况,绝大部分占用内存的组件或对象都已经加入mempool的管理中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
// src\include\mempool.h #define DEFINE_MEMORY_POOLS_HELPER(f) \ f(bloom_filter) \ f(bluestore_alloc) \ f(bluestore_cache_data) \ f(bluestore_cache_onode) \ f(bluestore_cache_other) \ f(bluestore_fsck) \ f(bluestore_txc) \ f(bluestore_writing_deferred) \ f(bluestore_writing) \ f(bluefs) \ f(buffer_anon) \ f(buffer_meta) \ f(osd) \ f(osd_mapbl) \ f(osd_pglog) \ f(osdmap) \ f(osdmap_mapping) \ f(pgmap) \ f(mds_co) \ f(unittest_1) \ f(unittest_2) |
rocksdb内存及其他统计信息获取(L版本)
需要打开rocksdb_perf配置项才可以使用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
root@ceph1 ~ $ ceph daemon osd.1 perf dump rocksdb { "rocksdb": { "get": 531, "submit_transaction": 352, "submit_transaction_sync": 195, "get_latency": { "avgcount": 531, "sum": 0.086399156, "avgtime": 0.000162710 }, ... "submit_sync_latency": { "avgcount": 195, "sum": 0.995746355, "avgtime": 0.005106391 }, ... "rocksdb_write_memtable_time": { "avgcount": 513, "sum": 0.008326307, "avgtime": 0.000016230 }, "rocksdb_write_delay_time": { "avgcount": 513, "sum": 0.000000000, "avgtime": 0.000000000 }, ... |
还有rocksdb本身的一些统计信息,都是从rocksdb自身的统计接口里获取的数据。这些信息需要打开rocksdb_collect_memory_stats、rocksdb_collect_extended_stats、rocksdb_collect_compaction_stats配置项。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
root@ceph1 ~ $ ceph daemon osd.0 dump_objectstore_kv_stats { "rocksdb_compaction_statistics": "", "": "", "": "** Compaction Stats [default] **", "": "Level Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop", "": "----------------------------------------------------------------------------------------------------------------------------------------------------------", "": " L0 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 4.0 0 1 0.018 0 0", "": " L1 3/0 132.66 MB 0.5 0.2 0.1 0.1 0.1 0.0 0.0 1.8 39.0 25.0 5 1 5.303 1432K 722K", "": " Sum 3/0 132.66 MB 0.0 0.2 0.1 0.1 0.1 0.0 0.0 1862.6 38.9 24.9 5 2 2.661 1432K 722K", "": " Int 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0.000 0 0", ... "": "** File Read Latency Histogram By Level [default] **", "": "** Level 0 read latency histogram (micros):", "": "Count: 2280 Average: 908.5671 StdDev: 1394.78", "": "Min: 455 Median: 789.0152 Max: 24077", "": "Percentiles: P50: 789.02 P75: 868.51 P99: 3150.00 P99.9: 23371.43 P99.99: 24077.00", "": "------------------------------------------------------", "": "[ 450, 500 ) 4 0.175% 0.175% ", "": "[ 500, 600 ) 89 3.904% 4.079% #", "": "[ 600, 700 ) 342 15.000% 19.079% ###", "": "[ 700, 800 ) 792 34.737% 53.816% #######", "": "[ 800, 900 ) 705 30.921% 84.737% ######", "": "[ 900, 1000 ) 253 11.096% 95.833% ##", ... "": "[ 14000, 16000 ) 2 0.088% 99.693% ", "": "[ 20000, 25000 ) 7 0.307% 100.000% ", "": "", "": "** Level 1 read latency histogram (micros):", "": "Count: 33743 Average: 849.7653 StdDev: 522.51", "": "Min: 434 Median: 825.1231 Max: 26385", "": "Percentiles: P50: 825.12 P75: 914.89 P99: 1195.47 P99.9: 5564.25 P99.99: 24141.06", "": "------------------------------------------------------", "": "[ 400, 450 ) 8 0.024% 0.024% ", "": "[ 450, 500 ) 66 0.196% 0.219% ", "": "[ 500, 600 ) 1067 3.162% 3.381% #", "": "[ 600, 700 ) 4231 12.539% 15.920% ###", "": "[ 700, 800 ) 8999 26.669% 42.590% #####", "": "[ 800, 900 ) 9953 29.496% 72.086% ######", "": "[ 900, 1000 ) 6605 19.574% 91.660% ####", "": "[ 1000, 1200 ) 2534 7.510% 99.170% ##", "": "[ 1200, 1400 ) 58 0.172% 99.342% ", "": "[ 1400, 1600 ) 25 0.074% 99.416% ", ... "": "[ 10000, 12000 ) 2 0.006% 99.947% ", "": "[ 14000, 16000 ) 2 0.006% 99.953% ", "": "[ 16000, 18000 ) 3 0.009% 99.961% ", "": "[ 18000, 20000 ) 3 0.009% 99.970% ", "": "[ 20000, 25000 ) 8 0.024% 99.994% ", "": "[ 25000, 30000 ) 2 0.006% 100.000% ", "": "", "": "", "": "** DB Stats **", "": "Uptime(secs): 1554.3 total, 938.9 interval", "": "Cumulative writes: 2292 writes, 5842 keys, 2292 commit groups, 1.0 writes per commit group, ingest: 0.00 GB, 0.00 MB/s", "": "Cumulative WAL: 2292 writes, 606 syncs, 3.78 writes per sync, written: 0.00 GB, 0.00 MB/s", "": "Cumulative stall: 00:00:0.000 H:M:S, 0.0 percent", "": "Interval writes: 0 writes, 0 keys, 0 commit groups, 0.0 writes per commit group, ingest: 0.00 MB, 0.00 MB/s", "": "Interval WAL: 0 writes, 0 syncs, 0.00 writes per sync, written: 0.00 MB, 0.00 MB/s", "": "Interval stall: 00:00:0.000 H:M:S, 0.0 percent" } { "rocksdb_extended_statistics": "", ".": "rocksdb.block.cache.miss COUNT : 85828", ".": "rocksdb.block.cache.hit COUNT : 8066", ".": "rocksdb.block.cache.add COUNT : 36002", ... ".": "rocksdb.num.subcompactions.scheduled statistics Percentiles :=> 50 : 0.000000 95 : 0.000000 99 : 0.000000 100 : 0.000000", ".": "rocksdb.bytes.per.read statistics Percentiles :=> 50 : 0.610333 95 : 191.390625 99 : 871.390625 100 : 883.000000", ".": "rocksdb.bytes.per.write statistics Percentiles :=> 50 : 997.607656 95 : 1954.814815 99 : 1997.259259 100 : 30050.000000", ... } { "rocksdb": { "get": 1831, "submit_transaction": 1686, "submit_transaction_sync": 606, "get_latency": { "avgcount": 1831, "sum": 0.262964280, "avgtime": 0.000143617 }, ... { "block_cache_usage": "155874833", "block_cache_pinned_blocks_usage": "0", "rocksdb_memtable_usage": "2228896" } |
dump数据流程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
void RocksDBStore::get_statistics(Formatter *f) { if (!g_conf->rocksdb_perf) { dout(20) < < __func__ << "RocksDB perf is disabled, can't probe for stats" << dendl; return; } if (g_conf->rocksdb_collect_compaction_stats) { std::string stat_str; bool status = db->GetProperty("rocksdb.stats", &stat_str); ... } if (g_conf->rocksdb_collect_extended_stats) { if (dbstats) { f->open_object_section("rocksdb_extended_statistics"); string stat_str = dbstats->ToString(); ... } if (g_conf->rocksdb_collect_memory_stats) { f->open_object_section("rocksdb_memtable_statistics"); std::string str(stringify(bbt_opts.block_cache->GetUsage())); f->dump_string("block_cache_usage", str.data()); str.clear(); str.append(stringify(bbt_opts.block_cache->GetPinnedUsage())); f->dump_string("block_cache_pinned_blocks_usage", str); str.clear(); db->GetProperty("rocksdb.cur-size-all-mem-tables", &str); f->dump_string("rocksdb_memtable_usage", str); f->close_section(); } } |
异常问题分析相关
signal处理/assert打印调用栈
线程健康状态监控及调用栈打印(当前及其他线程)
valgrind
ceph在teuthology集成了valgrind测试(并且有专门的配置文件:src/valgrind.sup),在跑用例过程中同时监控osd、mon的内存使用情况,发现内存泄露问题可以报出来。
https://blog.dachary.org/2013/08/14/howto-valgrind-ceph-with-teuthology/
crash dump或者正常退出可以打印保存在内存缓冲区的日志
默认内存缓冲区日志级别比较高,可以打印更多日志。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
int OSD::shutdown() { ... if (cct->_conf->get_val<bool>("osd_debug_shutdown")) { // 默认关闭 cct->_conf->set_val("debug_osd", "100"); cct->_conf->set_val("debug_journal", "100"); cct->_conf->set_val("debug_filestore", "100"); cct->_conf->set_val("debug_bluestore", "100"); cct->_conf->set_val("debug_ms", "100"); cct->_conf->apply_changes(NULL); } ... |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// src\common\assert.cc void __ceph_assert_fail(const char *assertion, const char *file, int line, const char *func) { ... if (g_assert_context) { lderr(g_assert_context) < < buf << std::endl; *_dout << oss.str(); *_dout << " NOTE: a copy of the executable, or `objdump -rdS <executable>` " < < "is needed to interpret this.\n" << dendl; g_assert_context->_log->dump_recent(); // 打印内存缓冲区日志,包括所有子模块 } abort(); } |
wireshark ceph协议支持
- https://docs.ceph.com/docs/master/dev/wireshark/
- https://www.wireshark.org/docs/dfref/c/ceph.html
- http://aspirer.wang/?p=1312 (第三节:使用tcpdump+wireshark解析Ceph网络包)
rbd客户端
krbd
使用
|
1 2 3 4 5 |
modprobe rbd rbd map pool/volume rbd unmap /dev/rbd0 rbd showmapped |
原理
与rbd-nbd类似,只是把用户态的nbd server转发librbd,改为在内核态直接发送到librbd,相当于实现了一个内核态的librbd client。
注意事项
- krbd方式需要卷的feature只有layering一个,如含有其他feature则无法映射卷到物理机的块设备
- 对内核版本有要求,随内核版本更新,更新缓慢,不支持新功能
- 调试不便
rbd-nbd是为了解决上述问题而开发的。
rbd-nbd
使用
|
1 2 3 4 5 6 |
// L版本 modprobe nbd rbd-nbd map pool/volume rbd-nbd unmap /dev/nbd0 rbd-nbd list-mapped |
原理
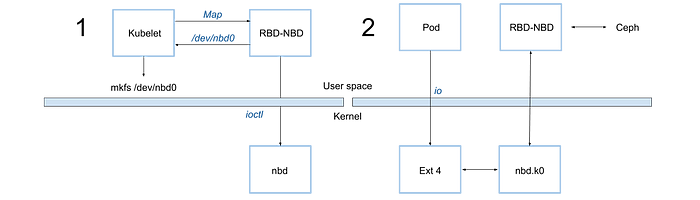
注意事项
有一些内核bug:
– nbd设备设置IO超时时间无效
– 4.9.65内核nbd设备+ext4文件系统mount状态resize后端盘大小导致文件系统异常
– 4.9.65内核umount一个断开连接的nbd设备挂载目录导致内核oops
fio支持
rbd
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@ceph-l ~ $ cat fio.rbd [global] ioengine=rbd clientname=admin pool=rbd rbdname=vol1 invalidate=0 rw=randwrite bs=4k runtime=6000 [rbd_iodepth128] iodepth=64 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
root@ceph-l ~ $ fio --enghelp Available IO engines: cpuio mmap sync psync ... splice rbd ### sg binject |
objectstore
对比
fio+librbd与krbd接近,但librbd方式对用户态CPU资源占用较多,rbd-nbd性能稍差
死锁检查
- 支持mutex、rwlock的死锁检查
- 可以打印加锁、解锁操作和锁的调用栈
- 可以记录等待锁的耗时信息
配置项lockdep/lockdep_force_backtrace/mutex_perf_counter
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
root@ceph-l ceph $ ceph daemon osd.0 perf dump | grep -i mutex -A3 "mutex-FileJournal::completions_lock": { "wait": { "avgcount": 29, "sum": 0.002629507 -- "mutex-FileJournal::finisher_lock": { "wait": { "avgcount": 0, "sum": 0.000000000 -- "mutex-FileJournal::write_lock": { "wait": { "avgcount": 0, "sum": 0.000000000 -- "mutex-FileJournal::writeq_lock": { "wait": { "avgcount": 87, "sum": 0.006935580 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
void Mutex::Lock(bool no_lockdep) { utime_t start; int r; if (lockdep && g_lockdep && !no_lockdep) _will_lock(); // 准备工作,死锁检查 if (TryLock()) { // 记录加锁信息,锁id、线程id、调用栈等,为下次的死锁检查做准备 goto out; } if (logger && cct && cct->_conf->mutex_perf_counter) start = ceph_clock_now(cct); r = pthread_mutex_lock(&_m); if (logger && cct && cct->_conf->mutex_perf_counter) logger->tinc(l_mutex_wait, ceph_clock_now(cct) - start); assert(r == 0); if (lockdep && g_lockdep) _locked(); _post_lock(); out: ; } void Mutex::Unlock() { _pre_unlock(); if (lockdep && g_lockdep) _will_unlock(); // 调用lockdep_will_unlock,打印解锁信息并清理记录 int r = pthread_mutex_unlock(&_m); assert(r == 0); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
int lockdep_will_lock(const char *name, int id, bool force_backtrace) { pthread_t p = pthread_self(); if (id < 0) id = lockdep_register(name); pthread_mutex_lock(&lockdep_mutex); lockdep_dout(20) << "_will_lock " << name << " (" << id << ")" << dendl; // 打印加锁信息 // check dependency graph map<int, BackTrace *> &m = held[p]; for (map<int , BackTrace *>::iterator p = m.begin(); p != m.end(); ++p) { if (p->first == id) { // 死锁条件1检查,二次加锁 lockdep_dout(0) < < "\n"; *_dout << "recursive lock of " << name << " (" << id << ")\n"; BackTrace *bt = new BackTrace(BACKTRACE_SKIP); bt->print(*_dout); if (p->second) { *_dout < < "\npreviously locked at\n"; p->second->print(*_dout); } delete bt; *_dout < < dendl; assert(0); } else if (!follows[p->first][id]) { // 死锁条件2检查,循环依赖 // new dependency // did we just create a cycle? if (does_follow(id, p->first)) { BackTrace *bt = new BackTrace(BACKTRACE_SKIP); lockdep_dout(0) < < "new dependency " << lock_names[p->first] < < " (" << p->first < < ") -> " < < name << " (" << id << ")" << " creates a cycle at\n"; bt->print(*_dout); *_dout < < dendl; lockdep_dout(0) << "btw, i am holding these locks:" << dendl; for (map<int, BackTrace *>::iterator q = m.begin(); q != m.end(); ++q) { lockdep_dout(0) < < " " << lock_names[q->first] < < " (" << q->first < < ")" << dendl; if (q->second) { lockdep_dout(0) < < " "; q->second->print(*_dout); *_dout < < dendl; } } lockdep_dout(0) << "\n" << dendl; // don't add this dependency, or we'll get aMutex. cycle in the graph, and // does_follow() won't terminate. assert(0); // actually, we should just die here. } else { BackTrace *bt = NULL; if (force_backtrace || lockdep_force_backtrace()) { bt = new BackTrace(BACKTRACE_SKIP); } follows[p->first][id] = bt; lockdep_dout(10) < < lock_names[p->first] < < " -> " < < name << " at" << dendl; //bt->print(*_dout); } } } pthread_mutex_unlock(&lockdep_mutex); return id; } |
pg锁增加等待耗时统计
|
1 2 3 4 5 6 7 8 9 |
PG::PG(OSDService *o, OSDMapRef curmap, const PGPool &_pool, spg_t p) : osd(o), cct(o->cct), ... - _lock("PG::_lock"), + _lock((std::string("PG::_lock") + _pool.name.c_str()).c_str(), false, true, false, o->cct), // cct传入才可以初始化perf counter |
throttle限流
查看限流统计信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
root@ceph-l ceph $ ceph daemon osd.0 perf dump throttle-osd_client_messages { "throttle-osd_client_messages": { "val": 19, "max": 500, "get": 811801, "get_sum": 811801, "get_or_fail_fail": 0, "get_or_fail_success": 0, "take": 0, "take_sum": 0, "put": 811782, "put_sum": 811782, "wait": { "avgcount": 0, "sum": 0.000000000 } } } |
throttle使用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
// ceph_osd.cc int main(int argc, const char **argv) { ... boost::scoped_ptr<throttle> client_msg_throttler( new Throttle(g_ceph_context, "osd_client_messages", g_conf->osd_client_message_cap)); ... ms_public->set_policy_throttlers(entity_name_t::TYPE_CLIENT, client_byte_throttler.get(), client_msg_throttler.get()); ... } int Pipe::read_message(Message **pm, AuthSessionHandler* auth_handler) { ... if (policy.throttler_messages) { ldout(msgr->cct,10) < < "reader wants " << 1 << " message from policy throttler " << policy.throttler_messages->get_current() < < "/" << policy.throttler_messages->get_max() < < dendl; policy.throttler_messages->get(); } ... out_dethrottle: // release bytes reserved from the throttlers on failure if (policy.throttler_messages) { ldout(msgr->cct,10) < < "reader releasing " << 1 << " message to policy throttler " << policy.throttler_messages->get_current() < < "/" << policy.throttler_messages->get_max() < < dendl; policy.throttler_messages->put(); } ... |
缺陷
目前只支持按op数量和大小进行限制,只用在了正常io处理流程,异常恢复等流程还没有实现。
日志相关
日志级别
|
1 2 3 4 5 6 7 8 9 |
# 文件日志级别,内存日志级别 root@ceph-l ceph $ ceph daemon osd.0 config show | grep debug_ "debug_none": "0\/5", ... "debug_mon": "1\/5", "debug_monc": "0\/10", "debug_paxos": "1\/5", ... |
日志子模块
|
1 2 3 4 5 6 7 8 9 10 |
// src\common\config_opts.h DEFAULT_SUBSYS(0, 5) SUBSYS(lockdep, 0, 1) SUBSYS(context, 0, 1) SUBSYS(crush, 1, 1) ... SUBSYS(throttle, 1, 1) SUBSYS(refs, 0, 0) SUBSYS(xio, 1, 5) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// src\common\config.cc void md_config_t::init_subsys() { #define SUBSYS(name, log, gather) \ subsys.add(ceph_subsys_##name, STRINGIFY(name), log, gather); #define DEFAULT_SUBSYS(log, gather) \ subsys.add(ceph_subsys_, "none", log, gather); #define OPTION(a, b, c) #include "common/config_opts.h" #undef OPTION #undef SUBSYS #undef DEFAULT_SUBSYS } |
|
1 2 3 4 5 6 7 8 9 10 11 |
// src\osd\OSD.cc #define dout_subsys ceph_subsys_osd #undef dout_prefix #define dout_prefix _prefix(_dout, whoami, get_osdmap_epoch()) static ostream& _prefix(std::ostream* _dout, int whoami, epoch_t epoch) { return *_dout < < "osd." << whoami << " " << epoch << " "; } dout(0) << " have superblock" << dendl; // 打印日志示例 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// src\common\debug.h #define dout(v) ldout((g_ceph_context), v) // src\common\dout.h #define dout_impl(cct, sub, v) \ do { \ if (cct->_conf->subsys.should_gather(sub, v)) { \ if (0) { \ char __array[((v >= -1) && (v < = 200)) ? 0 : -1] __attribute__((unused)); \ } \ ceph::log::Entry *_dout_e = cct->_log->create_entry(v, sub); \ ostream _dout_os(&_dout_e->m_streambuf); \ CephContext *_dout_cct = cct; \ std::ostream* _dout = &_dout_os; ... #define ldout(cct, v) dout_impl(cct, dout_subsys, v) dout_prefix ... #define dendl std::flush; \ _ASSERT_H->_log->submit_entry(_dout_e); \ } \ } while (0) ... |
集群日志
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
void OSD::handle_osd_map(MOSDMap *m) { ... } else { clog->warn() < < "map e" << osdmap->get_epoch() < < " wrongly marked me down"; } ... // 由mon的LogMonitor::preprocess_log/prepare_log处理来自osd的集群日志打印请求,最终打印到ceph.log文件中。 # /var/log/ceph/ceph.log 2019-07-31 02:07:32.191716 osd.92 10.171.5.122:6818/2755462 1588 : cluster [WRN] map e250674 wrongly marked me down |
日志回滚
kill -HUP/log reopen
举例:logrotate(reload)
|
1 2 3 4 5 6 7 |
# /etc/init.d/ceph ... force-reload | reload) signal_daemon $name ceph-$type $pid_file -1 "Reloading" ## kill -HUP $pid ;; ... |
也可以直接使用ceph daemon osd.X log reopen
全链路日志跟踪(优化目标)
痛点:跨节点、跨进程的日志无法串联起来,分析比较困难,需要对IO流程代码非常熟悉
解决方法:参考blkin流程,在日志里增加全局request id,从客户端到osd,以及osd内部的各子模块pg、journal、FileStore等统一使用request id来区分客户端io请求。
数据编解码
ceph-objectstore-tool
Ceph高级工具介绍之ceph-objectstore-tool的使用
ceph-dencoder
在ceph-dencoder中增加修改osd superblock中oldest_map字段功能
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
root@ceph-l ~ $ ceph-dencoder -h usage: ceph-dencoder [commands ...] ... editsb <oldest_map> <input sb file/> <output sb file> edit OSDSuperblock oldest_map section root@ceph-l ~ $ ceph-dencoder editsb 10000 superblock.orig superblock.new { "cluster_fsid": "238c3b45-c884-4911-942b-a424910250bf", "osd_fsid": "ca873f75-8cd1-4fbf-91fc-7cd6784b7e2c", "whoami": 0, "current_epoch": 354773, "oldest_map": 10000, ## superblock.new中的这个字段被改成10000 "newest_map": 354773, "weight": 0.000000, .... } |
安装部署
ceph-deploy
crush rule编辑工具
|
1 2 3 4 5 6 |
sudo ceph osd getcrushmap -o map sudo crushtool -d map -o dmap sudo vi dmap sudo crushtool -c dmap -o nmap sudo ceph osd setcrushmap -i nmap |
pg balance
开发者工具
vstart
blackhole开关
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
int FileStore::queue_transactions(Sequencer *posr, list<transaction *> &tls, TrackedOpRef osd_op, ThreadPool::TPHandle *handle) { Context *onreadable; Context *ondisk; Context *onreadable_sync; ObjectStore::Transaction::collect_contexts( tls, &onreadable, &ondisk, &onreadable_sync); if (g_conf->filestore_blackhole) { dout(0) < < "queue_transactions filestore_blackhole = TRUE, dropping transaction" << dendl; delete ondisk; delete onreadable; delete onreadable_sync; return 0; } ... |
异常(延时)注入
kill/error/心跳异常/ms异常/injectdataerr等:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
root@ceph-l common [CLDNBS-1301] $ grep inject config_opts.h OPTION(heartbeat_inject_failure, OPT_INT, 0) // force an unhealthy heartbeat for N seconds OPTION(ms_inject_socket_failures, OPT_U64, 0) OPTION(ms_inject_delay_type, OPT_STR, "") // "osd mds mon client" allowed OPTION(ms_inject_delay_msg_type, OPT_STR, "") // the type of message to delay, as returned by Message::get_type_name(). This is an additional restriction on the general type filter ms_inject_delay_type. OPTION(ms_inject_delay_max, OPT_DOUBLE, 1) // seconds OPTION(ms_inject_delay_probability, OPT_DOUBLE, 0) // range [0, 1] OPTION(ms_inject_internal_delays, OPT_DOUBLE, 0) // seconds OPTION(inject_early_sigterm, OPT_BOOL, false) OPTION(mon_inject_sync_get_chunk_delay, OPT_DOUBLE, 0) // inject N second delay on each get_chunk request OPTION(mon_inject_transaction_delay_max, OPT_DOUBLE, 10.0) // seconds OPTION(mon_inject_transaction_delay_probability, OPT_DOUBLE, 0) // range [0, 1] OPTION(client_debug_inject_tick_delay, OPT_INT, 0) // delay the client tick for a number of seconds OPTION(client_inject_release_failure, OPT_BOOL, false) // synthetic client bug for testing OPTION(objecter_inject_no_watch_ping, OPT_BOOL, false) // suppress watch pings OPTION(mds_inject_traceless_reply_probability, OPT_DOUBLE, 0) /* percentage OPTION(osd_inject_bad_map_crc_probability, OPT_FLOAT, 0) OPTION(osd_inject_failure_on_pg_removal, OPT_BOOL, false) OPTION(osd_debug_inject_copyfrom_error, OPT_BOOL, false) // inject failure during copyfrom completion // Allow object read error injection OPTION(filestore_debug_inject_read_err, OPT_BOOL, false) OPTION(filestore_kill_at, OPT_INT, 0) // inject a failure at the n'th opportunity OPTION(filestore_inject_stall, OPT_INT, 0) // artificially stall for N seconds in op queue thread |
|
1 2 3 4 5 6 7 8 9 10 11 |
bool HeartbeatMap::is_healthy() { m_rwlock.get_read(); time_t now = time(NULL); if (m_cct->_conf->heartbeat_inject_failure) { ldout(m_cct, 0) < < "is_healthy injecting failure for next " << m_cct->_conf->heartbeat_inject_failure < < " seconds" << dendl; m_inject_unhealthy_until = now + m_cct->_conf->heartbeat_inject_failure; m_cct->_conf->set_val("heartbeat_inject_failure", "0"); } ... |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// src\mon\MonitorDBStore.h struct C_DoTransaction : public Context { MonitorDBStore *store; MonitorDBStore::TransactionRef t; Context *oncommit; C_DoTransaction(MonitorDBStore *s, MonitorDBStore::TransactionRef t, Context *f) : store(s), t(t), oncommit(f) {} void finish(int r) { /* The store serializes writes. Each transaction is handled * sequentially by the io_work Finisher. If a transaction takes longer * to apply its state to permanent storage, then no other transaction * will be handled meanwhile. * * We will now randomly inject random delays. We can safely sleep prior * to applying the transaction as it won't break the model. */ double delay_prob = g_conf->mon_inject_transaction_delay_probability; if (delay_prob && (rand() % 10000 < delay_prob * 10000.0)) { utime_t delay; double delay_max = g_conf->mon_inject_transaction_delay_max; delay.set_from_double(delay_max * (double)(rand() % 10000) / 10000.0); lsubdout(g_ceph_context, mon, 1) < < "apply_transaction will be delayed for " << delay << " seconds" << dendl; delay.sleep(); } int ret = store->apply_transaction(t); oncommit->complete(ret); } |