新做的centos7.4镜像的cloud-init安装好之后,修改密码失败,但是同样的配置文件在7.2上的是正常的,对比了一下版本,centos7.4上的是0.7.9,7.2上的是0.7.5,经过调试发现是0.7.9版本的cloud-init有bug导致的,发现问题之后通过降级到0.7.5版本解决。之前也加断点调试过几次,但没有记录下来,这里记录下调试方法,因为默认直接加pdb断点是没法调试的。
首先要知道如何手工运行cloud-init工具,可以命令行执行: cloud-init -h ,看到有多个命令供选择,但我们只需要执行 cloud-init init 命令和 cloud-init init --local 命令即可,这两个命令就是开机自启动服务中会执行的,差异就是 --local 仅读取本地数据源(如config drive数据源),不加这个参数,可能尝试读取EC2等网络数据源(http://169.254.169.254)。
执行的时候要注意,cloud-init很多操作都是默认仅第一次开机的时候执行的(once-per-instance),也就是说默认情况下,每个云主机仅在第一次创建后启动的时候执行一次初始化操作,后面无论你怎么重启都不会执行的(当然不是全部初始化操作都不执行,要看具体的配置,但绝大部分操作都是once-per-instance)。所以为了保证每次手工执行的时候,都执行所有初始化操作,可以手工删除cloud-init的缓存目录,cloud-init是根据缓存中的云主机id(instance-id,一般就是云主机uuid)和数据源中获取的id来对比,确认是否是新建云主机第一次启动的。该缓存目录一般位于(/var/lib/cloud),直接删除整个目录即可清空缓存,调试过程中每次执行cloud-init命令前都需要删除一次。
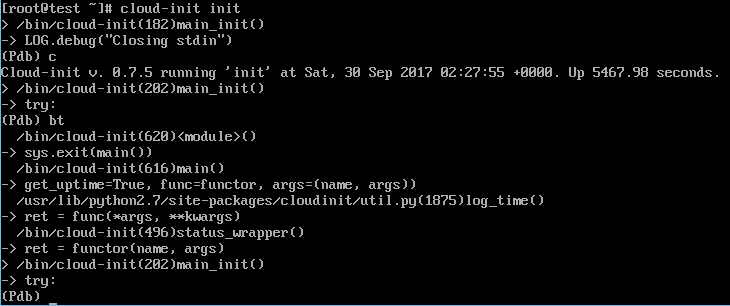
直接加pdb断点到源码里是无法调试的,因为cloud-init会重定向标准输入stdin,所以还要注释掉这行代码才行:
|
1 2 3 4 5 6 7 |
173 try: 174 LOG.debug("Closing stdin") 175 #util.close_stdin() ########### 注释掉这行 176 (outfmt, errfmt) = util.fixup_output(init.cfg, name) 177 except Exception: 178 util.logexc(LOG, "Failed to setup output redirection!") 179 print_exc("Failed to setup output redirection!") |
上面是cloud-init init命令需要注释掉代码的示例(基于0.7.9版本源码,0.7.5版本的入口在/usr/bin/cloud-init或者/bin/cloud-init,可使用 which cloud-init 命令查看具体路径,需要在这个文件里注释掉这行代码),如果你要调试其他命令如cloud-init modules还有其他地方需要注释:
|
1 2 3 4 5 6 7 8 |
$:/usr/lib/python2.7/site-packages/cloudinit/cmd# grep -rn stdin main.py ### (基于0.7.9版本,0.7.5的是/usr/bin/cloud-init) 174: LOG.debug("Closing stdin") 175: util.close_stdin() 356: LOG.debug("Closing stdin") 357: util.close_stdin() 419: LOG.debug("Closing stdin") 420: util.close_stdin() |
之后在main_init方法的入口处加入断点(0.7.5的不加会进入不了调试模式,0.7.9的可以不加,为了保险,可以加上,然后执行c命令跳到你真正想调试的断点处即可),然后再在你想要的任何地方加断点即可调试。
|
1 2 3 4 5 6 7 8 9 10 11 |
170 # Stage 2 171 outfmt = None 172 errfmt = None 173 import pdb;pdb.set_trace() ### 加入pdb断点 174 try: 175 LOG.debug("Closing stdin") 176 #util.close_stdin() ########### 注释掉这行 177 (outfmt, errfmt) = util.fixup_output(init.cfg, name) 178 except Exception: 179 util.logexc(LOG, "Failed to setup output redirection!") 180 print_exc("Failed to setup output redirection!") |