jira是什么?
请参考官网和国内零售商介绍:
https://www.atlassian.com/software/jira/features
http://www.unlimax.com/jira.html
以及演示网站:
http://www.jira.cn/secure/Dashboard.jspa
如何部署?
物理机或云主机
使用物理服务器或者云主机(vps)部署过程,网上有很多教程,看起来十分复杂繁琐,这里列出来一些搜索到的教程文档供大家对比参考:
http://blog.itpub.net/26230597/viewspace-1275597/
http://www.jb51.net/LINUXjishu/84221.html
http://www.linuxdiyf.com/linux/10492.html
总结起来这些教程主要是教大家如何部署tomcat、Jdk、MySQL,以及下载jira源码,准备安装环境等前期步骤。
接下来我们再来看下在网易蜂巢容器云平台上如何部署jira6。
网易蜂巢
首先我们要准备一个jira6的docker镜像,这里我是通过google搜索“jira docker image”,找到的其他人已经编写好的放在github上的Dockerfile,我就尝试直接拿来用到网易蜂巢云平台里面,以下是具体的部署步骤,供大家参考(如无特殊说明,下面的步骤均在本地Linux系统上执行):
- 安装docker运行环境,我的是Ubuntu 14.04系统,执行命令 apt-get install docker.io ,为啥是docker.io不是docker?据说是因为Ubuntu源里有个桌面主题的包名称叫docker,其他Linux发行版也是类似,比如redhat系列可以参考这篇文章,当然你也可以直接从docker官网下载安装docker运行环境 curl -sSL https://get.docker.com/ | sh
- 下载Dockerfile,执行 git clone https://github.com/cptactionhank/docker-atlassian-jira.git ,切换到想要安装的jira版本的分支,比如我想安装的是6.3.6版本,执行 git checkout origin/6.3.6 -b jira636 即可
- 在docker-atlassian-jira目录下可以看到Dockerfile文件,jira系统的默认访问端口号可以通过修改Dockerfile中EXPOSE 8080这行来改变,执行 docker build -t jira:636 . ,这一步是制作docker image
- 如果一切顺利,docker image会制作完成,屏幕输出类似 Successfully built f84ca46ff33e ,恭喜你,你可以跳过下面的第5、6两步,直接进入第7步
- 如果你比较悲剧,制作失败了,一般原因都是下载jira安装包或者mysql-connector-java包失败导致的,至于为啥失败,原因是国内的网络环境比较差,这两个包都是从国外的服务器上下载的,如果不采用一些特殊手段,下载失败是很正常的,如果你遇到下载timeout之类的问题,建议手工下载相关安装包,建议使用国内的下载站点或者翻 – 墙,可能用迅雷等下载工具也是一个可行的方法
- 这里我是遇到了下载安装包失败的问题,我是使用国外的代理手工下载的jira6.3.6安装包和mysql-connector-java安装包,下载完毕后,手工修改Dockerfile,其实就是修改两行,把curl下载安装包步骤去掉,改为直接从本地下载(在jira压缩包目录执行python -m SimpleHTTPServer即可启动简单的http服务器),把 curl -Ls "http://www.atlassian.com/software/jira/downloads/binary/atlassian-jira-${JIRA_VERSION}.tar.gz" | tar -xz --directory "${JIRA_INSTALL}" --strip-components=1 --no-same-owner 改为 curl -Ls "http://本机ip:8000/atlassian-jira-${JIRA_VERSION}.tar.gz" | tar -xz --directory "${JIRA_INSTALL}" --strip-components=1 --no-same-owner ,其中本机ip要替换为实际的ip,另外一个mysql-connector-java安装包也是同样的修改方法,另外要注意tar命令的解压参数需要从xz改为xf,之后重新执行第3步
- 执行 docker images 命令,你可以看到你刚刚制作的image,之后推送本地docker image到网易蜂巢镜像仓库,可以参考蜂巢的这篇文档,依次执行 docker login -u aspirer@163.com -p your-password -e aspirer@163.com hub.c.163.com 、 docker tag f84ca46ff33e hub.c.163.com/wang/jira:636 、 docker push hub.c.163.com/wang/jira:636 ,其中tag是你jira镜像的tag,不是java镜像那个,用户名也不是登录蜂巢控制台用的邮箱,而是网易蜂巢用户中心里面显示的那个用户名
- 等待镜像推送完毕后,会在屏幕输出类似 77e39ee82117: Image successfully pushed Digest: sha256:ef12633ff330b1301f86b30a6b3cd4d3db46c1f9f7551c26c76c94b4855a2950 信息
下面的步骤需要在网易蜂巢的控制台页面进行操作:
- 登录后进入镜像仓库页面,可以看到一个名为 jira/636 的镜像,jira为镜像名,636为标签
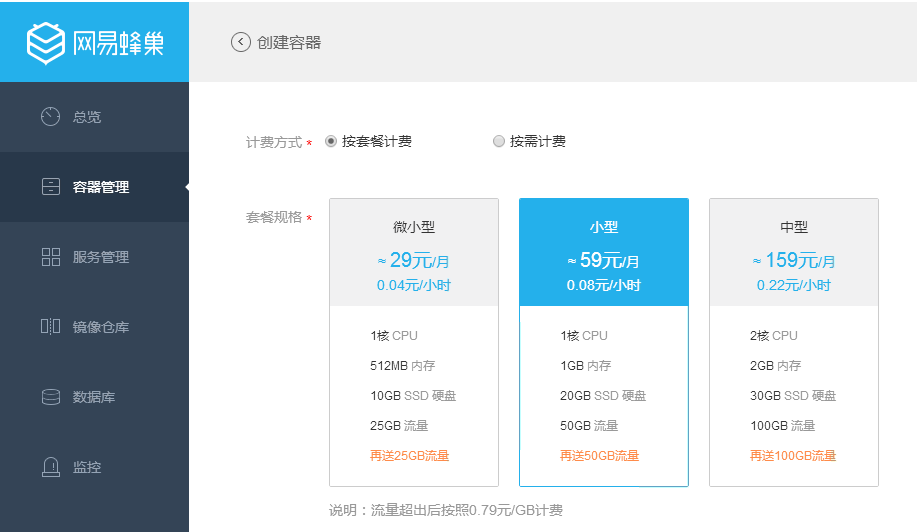
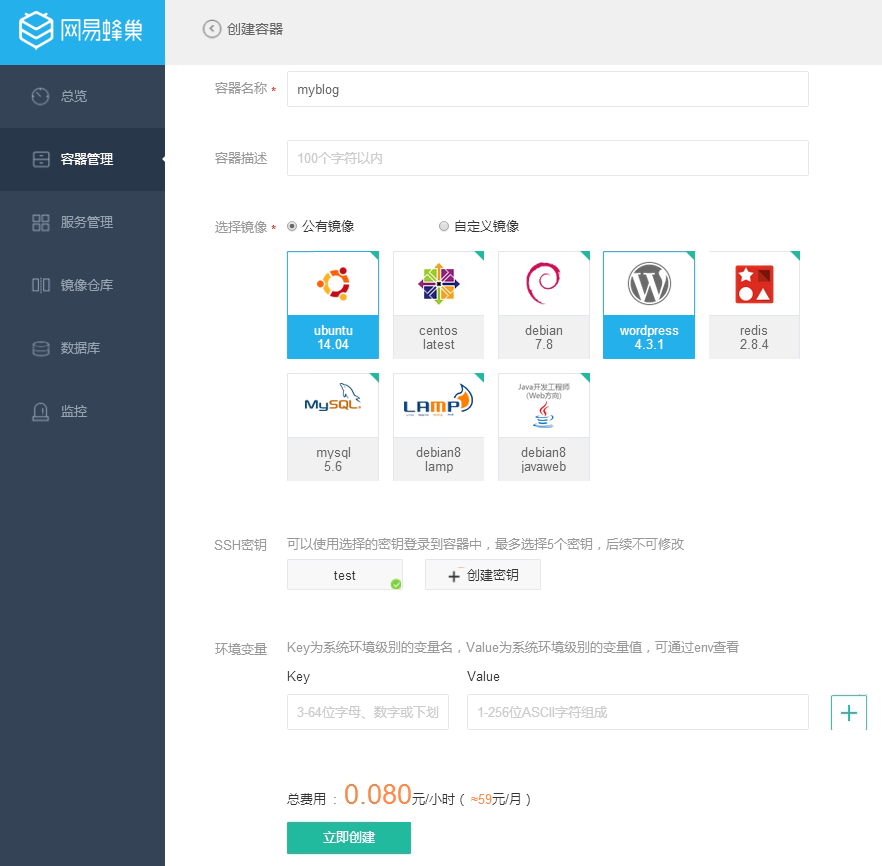
- 进入容器管理页面,点击创建容器,选择自定义镜像jira/636,选择合适的规格(建议至少1G内存),填写容器名称及其他相关设置后,点击立即创建即可
- 之后在列表页面点击容器名称,查看容器详情,可以看到容器的公网IP地址
- 等待容器创建完毕后
- 创建完毕后,jira的相关目录位于 ENV JIRA_HOME /var/local/atlassian/jira ENV JIRA_INSTALL /usr/local/atlassian/jira ,这两个目录在Dockerfile中有声明
下面的步骤在浏览器里进行操作:
- 在浏览器打开容器的公网IP加上默认的8080端口号,即可访问到jira系统
- 之后你可以对jira系统进行各种设置
下面是一些建议:
- 在此我建议你不要着急进行配置操作,而是再创建一个网易蜂巢数据库实例,用来作为jira系统的数据库,来保障你的数据安全可靠
- 在网易蜂巢上创建数据库实例非常简单,也可以方便的创建数据库用户和库,并支持ip白名单和安全组,以及只读数据库实例,具体使用方法你可以参考这篇文档
- 之后配置jira的数据库为蜂巢数据库实例的地址即可,有个提示就是你可以使用内网IP来让jira系统访问你的数据库实例,加快访问速度,提升安全性
之后的jira配置过程我不再多说,网上有很多教程可以参考。
最后我要说明一点,jira是一个非常优秀的任务跟踪、流程管理软件,强烈建议大家能够购买使用正版软件,自觉抵制各类安装教程中提供的破解版本,减少因使用盗版软件带来的安全风险和系统不稳定因素。