写这篇的起因是前段时间同事处理了一个打开基于ovs的安全组功能后,重启云主机后ovs流表刷新太慢导致云主机网络不通的问题,这个问题最终定位是neutron已经修复的bug:https://bugs.launchpad.net/neutron/+bug/1645655(没有backport到M版本),但由于对整个云主机tap网卡的创建、清理生命周期流程不清楚,所以走了一些弯路,因此决定整体分析下相关流程。
nova相关流程
基于nova Mitaka版本源码
创建云主机
创建云主机的整个nova流程比较复杂,要全部介绍的话得把nova代码翻一遍了,这里只描述跟libvirt相关的部分。
之前创建云主机整理的流程图(基于ceph系统盘),很多细节没考虑比如nova-conductor、neutron、MQ、DB等,供参考吧:
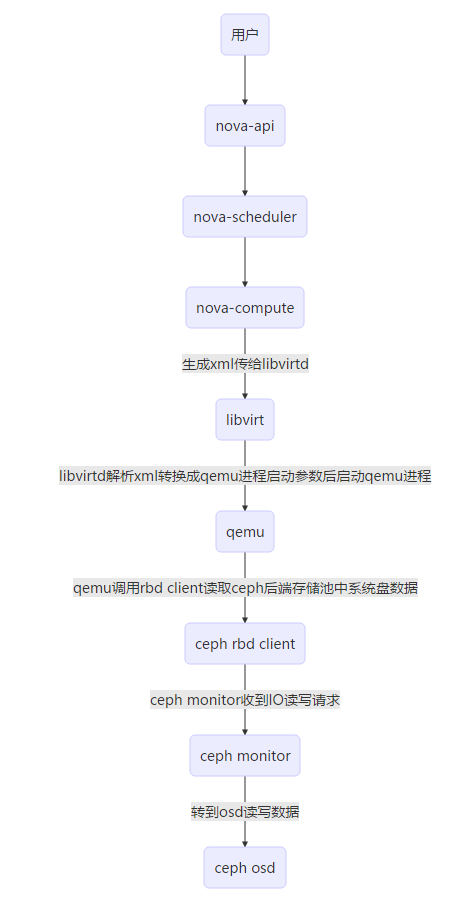
nova准备好云主机启动所需的全部资源后,就调用libvirt接口(通过libvirt-python api调用C库最后转到libvirtd),正式进入libvirt的create流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# NOTE(ilyaalekseyev): Implementation like in multinics # for xenapi(tr3buchet) def spawn(self, context, instance, image_meta, injected_files, admin_password, network_info=None, block_device_info=None): disk_info = blockinfo.get_disk_info(CONF.libvirt.virt_type, instance, image_meta, block_device_info) self._create_image(context, instance, ### 准备系统盘 disk_info['mapping'], network_info=network_info, block_device_info=block_device_info, files=injected_files, admin_pass=admin_password) xml = self._get_guest_xml(context, instance, network_info, ### 生成libvirt所需的xml disk_info, image_meta, block_device_info=block_device_info, write_to_disk=True) self._create_domain_and_network(context, xml, instance, network_info, ### 创建vm disk_info, block_device_info=block_device_info) LOG.debug("Instance is running", instance=instance) def _wait_for_boot(): """Called at an interval until the VM is running.""" state = self.get_info(instance).state if state == power_state.RUNNING: LOG.info(_LI("Instance spawned successfully."), instance=instance) raise loopingcall.LoopingCallDone() timer = loopingcall.FixedIntervalLoopingCall(_wait_for_boot) ### 等待vm变成running状态 timer.start(interval=0.5).wait() |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
## 中间省略了_create_domain_and_network代码分析 # TODO(sahid): Consider renaming this to _create_guest. def _create_domain(self, xml=None, domain=None, power_on=True, pause=False): """Create a domain. Either domain or xml must be passed in. If both are passed, then the domain definition is overwritten from the xml. :returns guest.Guest: Guest just created """ if xml: guest = libvirt_guest.Guest.create(xml, self._host) ### define vm by xml else: guest = libvirt_guest.Guest(domain) if power_on or pause: guest.launch(pause=pause) ### start vm if not utils.is_neutron(): guest.enable_hairpin() return guest |
|
|
def launch(self, pause=False): """Starts a created guest. :param pause: Indicates whether to start and pause the guest """ flags = pause and libvirt.VIR_DOMAIN_START_PAUSED or 0 try: return self._domain.createWithFlags(flags) ### libvirt python api,底层C api是virDomainCreateWithFlags except Exception: with excutils.save_and_reraise_exception(): LOG.error(_LE('Error launching a defined domain ' 'with XML: %s'), self._encoded_xml, errors='ignore') |
重启云主机
重启分为两种类型,soft和hard,区别是soft调用的libvirt接口是virDomainShutdownFlags+virDomainCreateWithFlags(virsh命令对应shutdown+start),hard是virDomainDestroyFlags+virDomainCreateWithFlags(virsh命令对应destroy+start)。
这里仅分析soft类型,hard类似:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
def reboot(self, context, instance, network_info, reboot_type, block_device_info=None, bad_volumes_callback=None): """Reboot a virtual machine, given an instance reference.""" if reboot_type == 'SOFT': # NOTE(vish): This will attempt to do a graceful shutdown/restart. try: soft_reboot_success = self._soft_reboot(instance) except libvirt.libvirtError as e: LOG.debug("Instance soft reboot failed: %s", e, instance=instance) soft_reboot_success = False if soft_reboot_success: LOG.info(_LI("Instance soft rebooted successfully."), instance=instance) return else: LOG.warn(_LW("Failed to soft reboot instance. " "Trying hard reboot."), instance=instance) return self._hard_reboot(context, instance, network_info, block_device_info) def _soft_reboot(self, instance): """Attempt to shutdown and restart the instance gracefully. We use shutdown and create here so we can return if the guest responded and actually rebooted. Note that this method only succeeds if the guest responds to acpi. Therefore we return success or failure so we can fall back to a hard reboot if necessary. :returns: True if the reboot succeeded """ guest = self._host.get_guest(instance) state = guest.get_power_state(self._host) old_domid = guest.id # NOTE(vish): This check allows us to reboot an instance that # is already shutdown. if state == power_state.RUNNING: guest.shutdown() ### shutdown # NOTE(vish): This actually could take slightly longer than the # FLAG defines depending on how long the get_info # call takes to return. self._prepare_pci_devices_for_use( pci_manager.get_instance_pci_devs(instance, 'all')) for x in range(CONF.libvirt.wait_soft_reboot_seconds): ### 等待vm启动 guest = self._host.get_guest(instance) state = guest.get_power_state(self._host) new_domid = guest.id # NOTE(ivoks): By checking domain IDs, we make sure we are # not recreating domain that's already running. if old_domid != new_domid: ### 通过比较新老domid判断是否重启,这段代码原本有个bug是我修复的 if state in [power_state.SHUTDOWN, power_state.CRASHED]: LOG.info(_LI("Instance shutdown successfully."), instance=instance) self._create_domain(domain=guest._domain) ### 关机后启动vm timer = loopingcall.FixedIntervalLoopingCall( self._wait_for_running, instance) timer.start(interval=0.5).wait() return True else: LOG.info(_LI("Instance may have been rebooted during soft " "reboot, so return now."), instance=instance) return True greenthread.sleep(1) return False |
删除过程主要是destroy并清理资源,就不多介绍了。
上述流程分析可以看到,nova里面其实是不管理tap设备的,只是通过查询neutron接口,找到云主机上绑定的port信息,用来生成libvirt所需的xml文件,tap设备的生命周期管理交给libvirt维护。
libvirt相关流程
基于libvirt v3.2.0版本源码
nova创建、重启过程中的启动过程,类似virsh start vm,会执行add-port命令,libvirtd的debug日志如下:
|
|
2018-01-08 07:02:19.309+0000: 1555: debug : virCommandRunAsync:2448 : About to run ovs-vsctl --timeout=5 -- --if-exists del-port tap99a07591-94 -- add-port br-int tap99a07591-94 -- set Interface tap99a07591-94 'external-ids:attached-mac="fa:16:3e:21:96:bc"' -- set Interface tap99a07591-94 'external-ids:iface-id="99a07591-9449-4969-b167-9b51dcc404b6"' -- set Interface tap99a07591-94 'external-ids:vm-id="cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"' -- set Interface tap99a07591-94 external-ids:iface-status=active 2018-01-08 07:02:19.310+0000: 1555: debug : virCommandRunAsync:2451 : Command result 0, with PID 12341 |
gdb debug调用栈如下,流程比较清晰,没有回调之类的,因此不再分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
Breakpoint 4, virCommandRunAsync (cmd=cmd@entry=0x7f43e8003dc0, pid=pid@entry=0x0) at util/vircommand.c:2360 2360 { (gdb) bt #0 virCommandRunAsync (cmd=cmd@entry=0x7f43e8003dc0, pid=pid@entry=0x0) at util/vircommand.c:2360 #1 0x00007f440a8ad994 in virCommandRun (cmd=cmd@entry=0x7f43e8003dc0, exitstatus=exitstatus@entry=0x0) at util/vircommand.c:2281 #2 0x00007f440a8e9883 in virNetDevOpenvswitchAddPort (brname=brname@entry=0x7f43e0015c60 "br-int", ifname=ifname@entry=0x7f43e8002090 "tap99a07591-94", macaddr=macaddr@entry=0x7f43e0015d04, vmuuid=vmuuid@entry=0x7f43e0014768 "͇\032\213-zJC\272c\357d\373\277\340\267 .", ovsport=ovsport@entry=0x7f43e0015230, virtVlan=virtVlan@entry=0x0) at util/virnetdevopenvswitch.c:179 #3 0x00007f440a8eac77 in virNetDevTapAttachBridge (tapname=0x7f43e8002090 "tap99a07591-94", brname=brname@entry=0x7f43e0015c60 "br-int", macaddr=macaddr@entry=0x7f43e0015d04, vmuuid=vmuuid@entry=0x7f43e0014768 "͇\032\213-zJC\272c\357d\373\277\340\267 .", virtPortProfile=virtPortProfile@entry=0x7f43e0015230, virtVlan=virtVlan@entry=0x0, mtu=mtu@entry=0, actualMTU=actualMTU@entry=0x0) at util/virnetdevtap.c:562 #4 0x00007f440a8eadc6 in virNetDevTapCreateInBridgePort (brname=brname@entry=0x7f43e0015c60 "br-int", ifname=ifname@entry=0x7f43e0015e10, macaddr=macaddr@entry=0x7f43e0015d04, vmuuid=vmuuid@entry=0x7f43e0014768 "͇\032\213-zJC\272c\357d\373\277\340\267 .", tunpath=tunpath@entry=0x7f43c514269c "/dev/net/tun", tapfd=tapfd@entry=0x7f43e8002050, tapfdSize=1, virtPortProfile=0x7f43e0015230, virtVlan=virtVlan@entry=0x0, coalesce=coalesce@entry=0x0, mtu=mtu@entry=0, actualMTU=actualMTU@entry=0x0, flags=flags@entry=3) at util/virnetdevtap.c:658 #5 0x00007f43c5108024 in qemuInterfaceBridgeConnect (def=def@entry=0x7f43e0014760, driver=driver@entry=0x7f440cb3eae0, net=net@entry=0x7f43e0015d00, tapfd=0x7f43e8002050, tapfdSize=tapfdSize@entry=0x7f43fadd1388) at qemu/qemu_interface.c:543 #6 0x00007f43c505a28d in qemuBuildInterfaceCommandLine (driver=driver@entry=0x7f440cb3eae0, logManager=logManager@entry=0x7f43e8002bb0, cmd=cmd@entry=0x7f43e8002a90, def=def@entry=0x7f43e0014760, net=net@entry=0x7f43e0015d00, qemuCaps=qemuCaps@entry=0x7f43e8003610, vlan=-1, bootindex=bootindex@entry=0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, standalone=standalone@entry=false, nnicindexes=nnicindexes@entry=0x7f43fadd16a8, nicindexes=nicindexes@entry=0x7f43fadd16b0) at qemu/qemu_command.c:8514 #7 0x00007f43c505fd90 in qemuBuildNetCommandLine (bootHostdevNet=0x7f43fadd14cc, nicindexes=0x7f43fadd16b0, nnicindexes=0x7f43fadd16a8, standalone=false, vmop=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, qemuCaps=0x7f43e8003610, def=0x7f43e0014760, cmd=0x7f43e8002a90, logManager=0x7f43e8002bb0, driver=0x7f440cb3eae0) at qemu/qemu_command.c:8787 #8 qemuBuildCommandLine (driver=driver@entry=0x7f440cb3eae0, logManager=0x7f43e8002bb0, def=def@entry=0x7f43e0014760, monitor_chr=monitor_chr@entry=0x7f43e8002f10, monitor_json=monitor_json@entry=true, qemuCaps=qemuCaps@entry=0x7f43e8003610, migrateURI=migrateURI@entry=0x0, snapshot=snapshot@entry=0x0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, standalone=standalone@entry=false, enableFips=enableFips@entry=false, nodeset=nodeset@entry=0x0, nnicindexes=nnicindexes@entry=0x7f43fadd16a8, nicindexes=nicindexes@entry=0x7f43fadd16b0, domainLibDir=0x7f43e80060b0 "/var/lib/libvirt/qemu/domain-3-instance-0000000e") at qemu/qemu_command.c:10111 #9 0x00007f43c509e210 in qemuProcessLaunch (conn=conn@entry=0x7f43e400adf0, driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, asyncJob=asyncJob@entry=QEMU_ASYNC_JOB_START, incoming=incoming@entry=0x0, snapshot=snapshot@entry=0x0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, flags=flags@entry=17) at qemu/qemu_process.c:5432 #10 0x00007f43c509e899 in qemuProcessStart (conn=conn@entry=0x7f43e400adf0, driver=driver@entry=0x7f440cb3eae0, ---Type <return> to continue, or q <return> to quit--- vm=vm@entry=0x7f440cbc0e60, updatedCPU=updatedCPU@entry=0x0, asyncJob=asyncJob@entry=QEMU_ASYNC_JOB_START, migrateFrom=migrateFrom@entry=0x0, migrateFd=migrateFd@entry=-1, migratePath=migratePath@entry=0x0, snapshot=snapshot@entry=0x0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, flags=17, flags@entry=1) at qemu/qemu_process.c:5794 #11 0x00007f43c5101026 in qemuDomainObjStart (conn=0x7f43e400adf0, driver=driver@entry=0x7f440cb3eae0, vm=0x7f440cbc0e60, flags=flags@entry=0, asyncJob=QEMU_ASYNC_JOB_START) at qemu/qemu_driver.c:7121 #12 0x00007f43c5101766 in qemuDomainCreateWithFlags (dom=0x7f43e8003140, flags=0) at qemu/qemu_driver.c:7175 #13 0x00007f440a9c189c in virDomainCreate (domain=domain@entry=0x7f43e8003140) at libvirt-domain.c:6532 #14 0x00007f440b64522e in remoteDispatchDomainCreate (server=0x7f440c9ce2e0, msg=0x7f440cc0e5c0, args=<optimized out>, rerr=0x7f43fadd1c50, client=0x7f440cbc2b90) at remote_dispatch.h:4222 #15 remoteDispatchDomainCreateHelper (server=0x7f440c9ce2e0, client=0x7f440cbc2b90, msg=0x7f440cc0e5c0, rerr=0x7f43fadd1c50, args=<optimized out>, ret=0x7f43e8003450) at remote_dispatch.h:4198 #16 0x00007f440aa2fdc2 in virNetServerProgramDispatchCall (msg=0x7f440cc0e5c0, client=0x7f440cbc2b90, server=0x7f440c9ce2e0, prog=0x7f440c9e72e0) at rpc/virnetserverprogram.c:437 #17 virNetServerProgramDispatch (prog=0x7f440c9e72e0, server=server@entry=0x7f440c9ce2e0, client=0x7f440cbc2b90, msg=0x7f440cc0e5c0) at rpc/virnetserverprogram.c:307 #18 0x00007f440b655f0d in virNetServerProcessMsg (msg=<optimized out>, prog=<optimized out>, client=<optimized out>, srv=0x7f440c9ce2e0) at rpc/virnetserver.c:148 #19 virNetServerHandleJob (jobOpaque=<optimized out>, opaque=0x7f440c9ce2e0) at rpc/virnetserver.c:169 #20 0x00007f440a9139e1 in virThreadPoolWorker (opaque=opaque@entry=0x7f440c9c37f0) at util/virthreadpool.c:167 #21 0x00007f440a912d68 in virThreadHelper (data=<optimized out>) at util/virthread.c:206 #22 0x00007f4407d28e25 in start_thread (arg=0x7f43fadd2700) at pthread_create.c:308 #23 0x00007f4407a5634d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:113 |
nova删除、关机、重启过程中的关机流程,类似virsh shutdown/destroy vm(shutdown的话,还分为使用qemu guest agent关机和使用ACPI接口关机两种,优先使用前一种),会删除ovs tap设备执行del-port命令,libvirtd的debug日志如下:
|
|
2018-01-08 07:38:18.407+0000: 12418: debug : virCommandRunAsync:2448 : About to run ovs-vsctl --timeout=5 -- --if-exists del-port tap99a07591-94 2018-01-08 07:38:18.409+0000: 12418: debug : virCommandRunAsync:2451 : Command result 0, with PID 18120 |
调用栈如下:
qemuProcessEventHandler发现qemu monitor退出,执行processMonitorEOFEvent,qemuProcessEventHandler为回调函数,负责处理qemu进程状态变更事件,回调函数的流程一般分为注册和执行两部分,
- 注册流程:libvirtd.c:main–>libvirtd.c:daemonInitialize(VIR_DAEMON_LOAD_MODULE(qemuRegister, “qemu”))–>src\qemu\qemu_driver.c:qemuRegister–>libvirt.c:virRegisterStateDriver(完成注册);
- 执行流程:main–>daemonStateInit–>daemonRunStateInit–>virStateInitialize–>qemuStateInitialize(qemu_driver->workerPool = virThreadPoolNew(0, 1, 0, qemuProcessEventHandler, qemu_driver))(遍历所有注册的state driver并执行完成初始化调用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Breakpoint 4, virCommandRunAsync (cmd=cmd@entry=0x7f43b0000fb0, pid=pid@entry=0x0) at util/vircommand.c:2360 2360 { (gdb) bt #0 virCommandRunAsync (cmd=cmd@entry=0x7f43b0000fb0, pid=pid@entry=0x0) at util/vircommand.c:2360 #1 0x00007f440a8ad994 in virCommandRun (cmd=cmd@entry=0x7f43b0000fb0, exitstatus=exitstatus@entry=0x0) at util/vircommand.c:2281 #2 0x00007f440a8e9cae in virNetDevOpenvswitchRemovePort (brname=<optimized out>, ifname=ifname@entry=0x7f43e8002090 "tap99a07591-94") at util/virnetdevopenvswitch.c:214 #3 0x00007f43c509a88a in qemuProcessStop (driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, reason=reason@entry=VIR_DOMAIN_SHUTOFF_SHUTDOWN, asyncJob=asyncJob@entry=QEMU_ASYNC_JOB_NONE, flags=flags@entry=0) at qemu/qemu_process.c:6162 #4 0x00007f43c5105d98 in processMonitorEOFEvent (vm=0x7f440cbc0e60, driver=0x7f440cb3eae0) at qemu/qemu_driver.c:4717 #5 qemuProcessEventHandler (data=<optimized out>, opaque=0x7f440cb3eae0) at qemu/qemu_driver.c:4762 #6 0x00007f440a9139e1 in virThreadPoolWorker (opaque=opaque@entry=0x7f440cc821c0) at util/virthreadpool.c:167 #7 0x00007f440a912d68 in virThreadHelper (data=<optimized out>) at util/virthread.c:206 #8 0x00007f4407d28e25 in start_thread (arg=0x7f43c2370700) at pthread_create.c:308 #9 0x00007f4407a5634d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:113 (gdb) p cmd.args[0] $21 = 0x7f43b0000b00 "ovs-vsctl" (gdb) p cmd.args[1] $22 = 0x7f43b0000ae0 "--timeout=5" (gdb) p cmd.args[2] $23 = 0x7f43b0000bf0 "--" (gdb) p cmd.args[3] $24 = 0x7f43b0000ac0 "--if-exists" (gdb) p cmd.args[4] $25 = 0x7f43b0000d70 "del-port" (gdb) p cmd.args[5] $26 = 0x7f43b0000d90 "tap99a07591-94" (gdb) p cmd.args[6] $27 = 0x0 (gdb) p cmd.args[7] $28 = 0x25 <Address 0x25 out of bounds> |
processMonitorEOFEvent事件回调函数的处理流程的另一个分支是结束qemu进程,libvirt发现qemu monitor socket关闭就会kill qemu主进程(monitor是libvirtd跟qemu进程的通信通道,通道断了libvirtd就无法控制qemu进程了,也就无法响应用户的各种查询、热插拔等操作,因此libvirtd选择杀死qemu进程,一了百了,不留后患),正常情况下都是qemu进程退出导致的monitor socket关闭,所以这种情况下会打日志“2018-01-08 07:38:18.427+0000: 1560: debug : qemuProcessKill:5897 : VM ‘instance-0000000e’ not active”,提示vm已关机,return 0返回不执行任何操作;异常退出情况下会kill掉qemu进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
int qemuProcessKill(virDomainObjPtr vm, unsigned int flags) { int ret; VIR_DEBUG("vm=%p name=%s pid=%lld flags=%x", vm, vm->def->name, (long long) vm->pid, flags); if (!(flags & VIR_QEMU_PROCESS_KILL_NOCHECK)) { if (!virDomainObjIsActive(vm)) { VIR_DEBUG("VM '%s' not active", vm->def->name); return 0; } } if (flags & VIR_QEMU_PROCESS_KILL_NOWAIT) { virProcessKill(vm->pid, (flags & VIR_QEMU_PROCESS_KILL_FORCE) ? SIGKILL : SIGTERM); return 0; } ret = virProcessKillPainfully(vm->pid, !!(flags & VIR_QEMU_PROCESS_KILL_FORCE)); return ret; } |
gdb调试调用栈如下:
|
|
Breakpoint 5, qemuProcessKill (vm=vm@entry=0x7f440cbc0e60, flags=flags@entry=1) at qemu/qemu_process.c:5888 5888 { (gdb) bt #0 qemuProcessKill (vm=vm@entry=0x7f440cbc0e60, flags=flags@entry=1) at qemu/qemu_process.c:5888 #1 0x00007f43c509965c in qemuProcessBeginStopJob (driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, job=job@entry=QEMU_JOB_DESTROY, forceKill=forceKill@entry=true) at qemu/qemu_process.c:5938 #2 0x00007f43c5105d31 in processMonitorEOFEvent (vm=0x7f440cbc0e60, driver=0x7f440cb3eae0) at qemu/qemu_driver.c:4692 #3 qemuProcessEventHandler (data=<optimized out>, opaque=0x7f440cb3eae0) at qemu/qemu_driver.c:4762 #4 0x00007f440a9139e1 in virThreadPoolWorker (opaque=opaque@entry=0x7f440cc821c0) at util/virthreadpool.c:167 #5 0x00007f440a912d68 in virThreadHelper (data=<optimized out>) at util/virthread.c:206 #6 0x00007f4407d28e25 in start_thread (arg=0x7f43c2370700) at pthread_create.c:308 #7 0x00007f4407a5634d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:113 (gdb) c |
|
|
Breakpoint 7, qemuMonitorIO (watch=watch@entry=81, fd=<optimized out>, events=<optimized out>, events@entry=9, opaque=opaque@entry=0x7f43e0003de0) at qemu/qemu_monitor.c:766 766 VIR_DEBUG("Triggering EOF callback"); (gdb) bt #0 qemuMonitorIO (watch=watch@entry=81, fd=<optimized out>, events=<optimized out>, events@entry=9, opaque=opaque@entry=0x7f43e0003de0) at qemu/qemu_monitor.c:766 #1 0x00007f440a8bd247 in virEventPollDispatchHandles (fds=<optimized out>, nfds=<optimized out>) at util/vireventpoll.c:508 #2 virEventPollRunOnce () at util/vireventpoll.c:657 #3 0x00007f440a8bb912 in virEventRunDefaultImpl () at util/virevent.c:314 #4 0x00007f440aa29f6d in virNetDaemonRun (dmn=dmn@entry=0x7f440c9d0120) at rpc/virnetdaemon.c:818 #5 0x00007f440b619e0c in main (argc=<optimized out>, argv=<optimized out>) at libvirtd.c:1541 |
调用qemu monitor回调,shutdown/destroy时执行(发现qemu monitor服务退出调用eofNotify,发现异常调用errorNotify,其他monitor事件则调用对应的回调,比如qemu进程发送的SHUTDOWN事件会调用qemuMonitorJSONHandleShutdown回调,):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
Breakpoint 7, qemuMonitorIO (watch=watch@entry=76, fd=<optimized out>, events=<optimized out>, events@entry=9, opaque=opaque@entry=0x7f43e0003510) at qemu/qemu_monitor.c:766 766 VIR_DEBUG("Triggering EOF callback"); (gdb) l 761 virDomainObjPtr vm = mon->vm; 762 763 /* Make sure anyone waiting wakes up now */ 764 virCondSignal(&mon->notify); 765 virObjectUnlock(mon); 766 VIR_DEBUG("Triggering EOF callback"); 767 (eofNotify)(mon, vm, mon->callbackOpaque); 768 virObjectUnref(mon); 769 } else if (error) { 770 qemuMonitorErrorNotifyCallback errorNotify = mon->cb->errorNotify; (gdb) p eofNotify $29 = (void (*)(qemuMonitorPtr, virDomainObjPtr, void *)) 0x7f43c5095020 <qemuProcessHandleMonitorEOF> (gdb) p mon->cb $30 = (qemuMonitorCallbacksPtr) 0x7f43c5364fa0 <monitorCallbacks> (gdb) p mon->cb-> destroy domainGraphics domainPMWakeup domainStop diskSecretLookup domainGuestPanic domainPowerdown domainTrayChange domainAcpiOstInfo domainIOError domainRTCChange domainWatchdog domainBalloonChange domainMigrationPass domainReset eofNotify domainBlockJob domainMigrationStatus domainResume errorNotify domainBlockThreshold domainNicRxFilterChanged domainSerialChange domainDeviceDeleted domainPMSuspend domainShutdown domainEvent domainPMSuspendDisk domainSpiceMigrated (gdb) p mon->cb->errorNotify $31 = (qemuMonitorErrorNotifyCallback) 0x7f43c5094f90 <qemuProcessHandleMonitorError> (gdb) p mon->cb->domainPowerdown $32 = (qemuMonitorDomainPowerdownCallback) 0x0 (gdb) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Breakpoint 4, qemuMonitorJSONHandleShutdown (mon=0x7f2dcc013ce0, data=0x0) at qemu/qemu_monitor_json.c:527 527 { (gdb) bt #0 qemuMonitorJSONHandleShutdown (mon=0x7f2dcc013ce0, data=0x0) at qemu/qemu_monitor_json.c:527 #1 0x00007f2da85a3fc2 in qemuMonitorJSONIOProcessEvent (obj=0x7f2dea7b7b20, mon=0x7f2dcc013ce0) at qemu/qemu_monitor_json.c:180 #2 qemuMonitorJSONIOProcessLine (mon=mon@entry=0x7f2dcc013ce0, line=<optimized out>, msg=msg@entry=0x0) at qemu/qemu_monitor_json.c:209 #3 0x00007f2da85a4198 in qemuMonitorJSONIOProcess (mon=mon@entry=0x7f2dcc013ce0, data=0x7f2dea7b9290 "{\"timestamp\": {\"seconds\": 1515459631, \"microseconds\": 886362}, \"event\": \"SHUTDOWN\"}\r\n{\"timestamp\": {\"seconds\": 1515459631, \"microseconds\": 894238}, \"event\": \"DEVICE_TRAY_MOVED\", \"data\": {\"device\": \"dr"..., len=236, msg=msg@entry=0x0) at qemu/qemu_monitor_json.c:251 #4 0x00007f2da858e0f2 in qemuMonitorIOProcess (mon=0x7f2dcc013ce0) at qemu/qemu_monitor.c:434 #5 qemuMonitorIO (watch=watch@entry=19, fd=<optimized out>, events=0, events@entry=1, opaque=opaque@entry=0x7f2dcc013ce0) at qemu/qemu_monitor.c:688 #6 0x00007f2de76a3247 in virEventPollDispatchHandles (fds=<optimized out>, nfds=<optimized out>) at util/vireventpoll.c:508 #7 virEventPollRunOnce () at util/vireventpoll.c:657 #8 0x00007f2de76a1912 in virEventRunDefaultImpl () at util/virevent.c:314 #9 0x00007f2de780ff6d in virNetDaemonRun (dmn=dmn@entry=0x7f2dea58d120) at rpc/virnetdaemon.c:818 #10 0x00007f2de83ffe0c in main (argc=<optimized out>, argv=<optimized out>) at libvirtd.c:1541 |
上面是destroy操作加的断点调试信息输出。qemuMonitorJSONHandleShutdown会调用注册好的关机事件回调,src\qemu\qemu_monitor_json.c:
|
|
static void qemuMonitorJSONHandleShutdown(qemuMonitorPtr mon, virJSONValuePtr data ATTRIBUTE_UNUSED) { qemuMonitorEmitShutdown(mon); } |
src\qemu\qemu_monitor.c(最终调用到mon->cb的domainShutdown回调函数):
|
|
int qemuMonitorEmitShutdown(qemuMonitorPtr mon) { int ret = -1; VIR_DEBUG("mon=%p", mon); QEMU_MONITOR_CALLBACK(mon, ret, domainShutdown, mon->vm); return ret; } |
注册qemu monitor回调过程是在创建vm时执行的,如domainShutdown的回调是qemuProcessHandleShutdown:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
Breakpoint 8, qemuMonitorOpenInternal (vm=vm@entry=0x7f440cbc0e60, fd=26, hasSendFD=true, json=json@entry=true, cb=cb@entry=0x7f43c5364fa0 <monitorCallbacks>, opaque=opaque@entry=0x7f440cb3eae0) at qemu/qemu_monitor.c:793 793 { (gdb) bt #0 qemuMonitorOpenInternal (vm=vm@entry=0x7f440cbc0e60, fd=26, hasSendFD=true, json=json@entry=true, cb=cb@entry=0x7f43c5364fa0 <monitorCallbacks>, opaque=opaque@entry=0x7f440cb3eae0) at qemu/qemu_monitor.c:793 #1 0x00007f43c50bd718 in qemuMonitorOpen (vm=vm@entry=0x7f440cbc0e60, config=<optimized out>, json=<optimized out>, timeout=<optimized out>, timeout@entry=0, cb=cb@entry=0x7f43c5364fa0 <monitorCallbacks>, opaque=opaque@entry=0x7f440cb3eae0) at qemu/qemu_monitor.c:929 #2 0x00007f43c5093194 in qemuConnectMonitor (driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, asyncJob=asyncJob@entry=6, logCtxt=logCtxt@entry=0x7f43e0015c40) at qemu/qemu_process.c:1743 #3 0x00007f43c50965ad in qemuProcessWaitForMonitor (driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, asyncJob=asyncJob@entry=6, qemuCaps=0x7f43e00155f0, logCtxt=logCtxt@entry=0x7f43e0015c40) at qemu/qemu_process.c:2125 #4 0x00007f43c509cd3a in qemuProcessLaunch (conn=conn@entry=0x7f43d8003340, driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, asyncJob=asyncJob@entry=QEMU_ASYNC_JOB_START, incoming=incoming@entry=0x0, snapshot=snapshot@entry=0x0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, flags=flags@entry=17) at qemu/qemu_process.c:5589 #5 0x00007f43c509e899 in qemuProcessStart (conn=conn@entry=0x7f43d8003340, driver=driver@entry=0x7f440cb3eae0, vm=vm@entry=0x7f440cbc0e60, updatedCPU=updatedCPU@entry=0x0, asyncJob=asyncJob@entry=QEMU_ASYNC_JOB_START, migrateFrom=migrateFrom@entry=0x0, migrateFd=migrateFd@entry=-1, migratePath=migratePath@entry=0x0, snapshot=snapshot@entry=0x0, vmop=vmop@entry=VIR_NETDEV_VPORT_PROFILE_OP_CREATE, flags=17, flags@entry=1) at qemu/qemu_process.c:5794 #6 0x00007f43c5101026 in qemuDomainObjStart (conn=0x7f43d8003340, driver=driver@entry=0x7f440cb3eae0, vm=0x7f440cbc0e60, flags=flags@entry=0, asyncJob=QEMU_ASYNC_JOB_START) at qemu/qemu_driver.c:7121 #7 0x00007f43c5101766 in qemuDomainCreateWithFlags (dom=0x7f43e0012090, flags=0) at qemu/qemu_driver.c:7175 #8 0x00007f440a9c189c in virDomainCreate (domain=domain@entry=0x7f43e0012090) at libvirt-domain.c:6532 #9 0x00007f440b64522e in remoteDispatchDomainCreate (server=0x7f440c9ce2e0, msg=0x7f440cc0e2e0, args=<optimized out>, rerr=0x7f43f9dcfc50, client=0x7f440cbc2b90) at remote_dispatch.h:4222 #10 remoteDispatchDomainCreateHelper (server=0x7f440c9ce2e0, client=0x7f440cbc2b90, msg=0x7f440cc0e2e0, rerr=0x7f43f9dcfc50, args=<optimized out>, ret=0x7f43e00155d0) at remote_dispatch.h:4198 #11 0x00007f440aa2fdc2 in virNetServerProgramDispatchCall (msg=0x7f440cc0e2e0, client=0x7f440cbc2b90, server=0x7f440c9ce2e0, prog=0x7f440c9e72e0) at rpc/virnetserverprogram.c:437 #12 virNetServerProgramDispatch (prog=0x7f440c9e72e0, server=server@entry=0x7f440c9ce2e0, client=0x7f440cbc2b90, msg=0x7f440cc0e2e0) at rpc/virnetserverprogram.c:307 #13 0x00007f440b655f0d in virNetServerProcessMsg (msg=<optimized out>, prog=<optimized out>, client=<optimized out>, srv=0x7f440c9ce2e0) at rpc/virnetserver.c:148 #14 virNetServerHandleJob (jobOpaque=<optimized out>, opaque=0x7f440c9ce2e0) at rpc/virnetserver.c:169 #15 0x00007f440a9139e1 in virThreadPoolWorker (opaque=opaque@entry=0x7f440c9c32b0) at util/virthreadpool.c:167 #16 0x00007f440a912d68 in virThreadHelper (data=<optimized out>) at util/virthread.c:206 #17 0x00007f4407d28e25 in start_thread (arg=0x7f43f9dd0700) at pthread_create.c:308 #18 0x00007f4407a5634d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:113 |
全部回调定义在src\qemu\qemu_process.c:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
static qemuMonitorCallbacks monitorCallbacks = { .eofNotify = qemuProcessHandleMonitorEOF, .errorNotify = qemuProcessHandleMonitorError, .diskSecretLookup = qemuProcessFindVolumeQcowPassphrase, .domainEvent = qemuProcessHandleEvent, .domainShutdown = qemuProcessHandleShutdown, .domainStop = qemuProcessHandleStop, .domainResume = qemuProcessHandleResume, .domainReset = qemuProcessHandleReset, .domainRTCChange = qemuProcessHandleRTCChange, .domainWatchdog = qemuProcessHandleWatchdog, .domainIOError = qemuProcessHandleIOError, .domainGraphics = qemuProcessHandleGraphics, .domainBlockJob = qemuProcessHandleBlockJob, .domainTrayChange = qemuProcessHandleTrayChange, .domainPMWakeup = qemuProcessHandlePMWakeup, .domainPMSuspend = qemuProcessHandlePMSuspend, .domainBalloonChange = qemuProcessHandleBalloonChange, .domainPMSuspendDisk = qemuProcessHandlePMSuspendDisk, .domainGuestPanic = qemuProcessHandleGuestPanic, .domainDeviceDeleted = qemuProcessHandleDeviceDeleted, .domainNicRxFilterChanged = qemuProcessHandleNicRxFilterChanged, .domainSerialChange = qemuProcessHandleSerialChanged, .domainSpiceMigrated = qemuProcessHandleSpiceMigrated, .domainMigrationStatus = qemuProcessHandleMigrationStatus, .domainMigrationPass = qemuProcessHandleMigrationPass, .domainAcpiOstInfo = qemuProcessHandleAcpiOstInfo, .domainBlockThreshold = qemuProcessHandleBlockThreshold, }; |
qemu事件处理方法定义在src\qemu\qemu_monitor_json.c:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
static qemuEventHandler eventHandlers[] = { { "ACPI_DEVICE_OST", qemuMonitorJSONHandleAcpiOstInfo, }, { "BALLOON_CHANGE", qemuMonitorJSONHandleBalloonChange, }, { "BLOCK_IO_ERROR", qemuMonitorJSONHandleIOError, }, { "BLOCK_JOB_CANCELLED", qemuMonitorJSONHandleBlockJobCanceled, }, { "BLOCK_JOB_COMPLETED", qemuMonitorJSONHandleBlockJobCompleted, }, { "BLOCK_JOB_READY", qemuMonitorJSONHandleBlockJobReady, }, { "BLOCK_WRITE_THRESHOLD", qemuMonitorJSONHandleBlockThreshold, }, { "DEVICE_DELETED", qemuMonitorJSONHandleDeviceDeleted, }, { "DEVICE_TRAY_MOVED", qemuMonitorJSONHandleTrayChange, }, { "GUEST_PANICKED", qemuMonitorJSONHandleGuestPanic, }, { "MIGRATION", qemuMonitorJSONHandleMigrationStatus, }, { "MIGRATION_PASS", qemuMonitorJSONHandleMigrationPass, }, { "NIC_RX_FILTER_CHANGED", qemuMonitorJSONHandleNicRxFilterChanged, }, { "POWERDOWN", qemuMonitorJSONHandlePowerdown, }, { "RESET", qemuMonitorJSONHandleReset, }, { "RESUME", qemuMonitorJSONHandleResume, }, { "RTC_CHANGE", qemuMonitorJSONHandleRTCChange, }, { "SHUTDOWN", qemuMonitorJSONHandleShutdown, }, { "SPICE_CONNECTED", qemuMonitorJSONHandleSPICEConnect, }, { "SPICE_DISCONNECTED", qemuMonitorJSONHandleSPICEDisconnect, }, { "SPICE_INITIALIZED", qemuMonitorJSONHandleSPICEInitialize, }, { "SPICE_MIGRATE_COMPLETED", qemuMonitorJSONHandleSpiceMigrated, }, { "STOP", qemuMonitorJSONHandleStop, }, { "SUSPEND", qemuMonitorJSONHandlePMSuspend, }, { "SUSPEND_DISK", qemuMonitorJSONHandlePMSuspendDisk, }, { "VNC_CONNECTED", qemuMonitorJSONHandleVNCConnect, }, { "VNC_DISCONNECTED", qemuMonitorJSONHandleVNCDisconnect, }, { "VNC_INITIALIZED", qemuMonitorJSONHandleVNCInitialize, }, { "VSERPORT_CHANGE", qemuMonitorJSONHandleSerialChange, }, { "WAKEUP", qemuMonitorJSONHandlePMWakeup, }, { "WATCHDOG", qemuMonitorJSONHandleWatchdog, }, /* We use bsearch, so keep this list sorted. */ }; |
qemu事件定义,在qemu源码的qapi/run-state.json文件中,具体的事件发送流程还没分析,应该是封装好之后通过monitor socket传递的,类似qemu-guest-agent的命令结果传递流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# @SHUTDOWN: # # Emitted when the virtual machine has shut down, indicating that qemu is # about to exit. # # @guest: If true, the shutdown was triggered by a guest request (such as # a guest-initiated ACPI shutdown request or other hardware-specific action) # rather than a host request (such as sending qemu a SIGINT). (since 2.10) # # Note: If the command-line option "-no-shutdown" has been specified, qemu will # not exit, and a STOP event will eventually follow the SHUTDOWN event # # Since: 0.12.0 # # Example: # # <- { "event": "SHUTDOWN", "data": { "guest": true }, # "timestamp": { "seconds": 1267040730, "microseconds": 682951 } } # ## { 'event': 'SHUTDOWN', 'data': { 'guest': 'bool' } } ## # @POWERDOWN: # # Emitted when the virtual machine is powered down through the power control # system, such as via ACPI. # # Since: 0.12.0 # # Example: # # <- { "event": "POWERDOWN", # "timestamp": { "seconds": 1267040730, "microseconds": 682951 } } # ## { 'event': 'POWERDOWN' } |
Centos7 libvirtd gdb调试
简单描述下,有两种方法,一种是通过yum安装debuginfo包,好处是方便快捷,执行
yum install libvirt-debuginfo 即可,但是编译优化没关导致单步调试有些地方跟源码对应不起来,还有就是变量经常被优化掉看不到具体的值,我上面为了方便采用的这种方式。debuginfo的源一般没有镜像,直接使用官方的:
|
|
[debug] name=CentOS-$releasever - DebugInfo baseurl=http://debuginfo.centos.org/$releasever/$basearch/ gpgcheck=0 enabled=1 protect=1 priority=1 |
另外一种是自己从编译debug二进制,推荐第二种方式,但是编译依赖有点多,参考:https://libvirt.org/compiling.html
之前记录的debian7环境下老版本libvirt编译方法(应该是1.1.4版本的),可以参考依赖包和编译步骤:
apt-get install gcc make pkg-config libxml2-dev libgnutls-dev libdevmapper-dev python-dev libnl-dev libyajl-dev libpciaccess-dev build-essential libhal-dev libudev-dev libtool(–with-hal=yes –with-udev=yes用到)
后面这两个用来解决这个问题:sudo virsh nodedev-list
error: Failed to count node devices
error: this function is not supported by the connection driver: virNodeNumOfDevices
./configure –prefix=/usr –libdir=/usr/lib –localstatedir=/var –sysconfdir=/etc –with-hal=yes –with-udev=yes
./configure –prefix=/usr –libdir=/usr/lib –localstatedir=/var –sysconfdir=/etc –with-selinux
######error: failed to get the hypervisor version
######error: internal error Cannot find suitable emulator for x86_64
解决方法:安装libyajl-dev之后重新./configure,make,make install
libvirt-1.1.4编译:
make报错:aclocal-1.13: command not found
解决方法:执行./autogen.sh –system(autoreconf),然后make
neutron相关流程
基于neutron Mitaka版本源码,VLAN type driver+ovs mechanism driver,ovs安全组未开启(所以也没有相关流表的操作)。
主要分析tap设备插入、删除操作后,neutron-openvswitch-agent都做了哪些事情。
在不清楚代码流程的情况下,翻日志是最快的方式,云主机启动tap设备插入操作的neutron-openvswitch-agent debug日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
2018-01-09 15:08:02.208 11707 DEBUG neutron.agent.linux.async_process [-] Output received from [ovsdb-client monitor Interface name,ofport,external_ids --format=json]: {"data":[["20ee0a84-c9aa-49a5-83da-fa722ee415e5","insert","tap99a07591-94",["set",[]],["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} _read_stdout /opt/stack/neutron/neutron/agent/linux/async_process.py:233 2018-01-09 15:08:02.209 11707 DEBUG neutron.agent.linux.async_process [-] Output received from [ovsdb-client monitor Interface name,ofport,external_ids --format=json]: {"data":[["20ee0a84-c9aa-49a5-83da-fa722ee415e5","old",null,["set",[]],null],["","new","tap99a07591-94",21,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} _read_stdout /opt/stack/neutron/neutron/agent/linux/async_process.py:233 2018-01-09 15:08:03.426 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:43419 started rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1946 2018-01-09 15:08:03.426 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'dump-flows', 'br-int', 'table=23'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.445 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.446 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command: ['ps', '--ppid', '11795', '-o', 'pid='] create_process /opt/stack/neutron/neutron/agent/linux/utils.py:90 2018-01-09 15:08:03.470 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.470 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command: ['ps', '--ppid', '11797', '-o', 'pid='] create_process /opt/stack/neutron/neutron/agent/linux/utils.py:90 2018-01-09 15:08:03.486 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.487 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:43419 - starting polling. Elapsed:0.061 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1997 2018-01-09 15:08:03.487 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] retrying failed devices set([]) _update_port_info_failed_devices_stats /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1248 2018-01-09 15:08:03.488 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] retrying failed devices set([]) _update_port_info_failed_devices_stats /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1248 2018-01-09 15:08:03.495 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.509 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.509 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag', 'list', 'Port', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.522 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.522 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.529 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.529 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,external_ids,ofport', 'list', 'Interface', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.536 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.537 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:43419 - port information retrieved. Elapsed:0.111 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2020 2018-01-09 15:08:03.537 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Starting to process devices in:{'current': set([u'99a07591-9449-4969-b167-9b51dcc404b6', u'13193995-2b8a-450b-ac59-3184d2128bf6', u'e803e446-56ed-473e-9d57-63c598b6e315', u'c6cae3a6-7bf0-4587-9e07-8442d45a703c', u'01c11d8b-da68-48e5-8955-7c675261ab45']), 'removed': set([]), 'added': set([u'99a07591-9449-4969-b167-9b51dcc404b6'])} rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2027 2018-01-09 15:08:03.538 11707 DEBUG oslo_messaging._drivers.amqpdriver [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] CALL msg_id: ec1bf0c94f954227a023ec450b6c42d5 exchange 'neutron' topic 'q-plugin' _send /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:454 2018-01-09 15:08:03.711 11707 DEBUG oslo_messaging._drivers.amqpdriver [-] received reply msg_id: ec1bf0c94f954227a023ec450b6c42d5 __call__ /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:302 2018-01-09 15:08:03.712 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.738 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.738 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,external_ids,ofport', 'list', 'Interface', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.752 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.753 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Processing port: 99a07591-9449-4969-b167-9b51dcc404b6 treat_devices_added_or_updated /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1504 2018-01-09 15:08:03.753 11707 INFO neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Port 99a07591-9449-4969-b167-9b51dcc404b6 updated. Details: {u'profile': {}, u'network_qos_policy_id': None, u'qos_policy_id': None, u'allowed_address_pairs': [], u'admin_state_up': True, u'network_id': u'4aef4a59-f2e0-4aa7-9cf9-28f1a9bd62c6', u'segmentation_id': 3333, u'device_owner': u'compute:None', u'physical_network': u'physnet1', u'mac_address': u'fa:16:3e:21:96:bc', u'device': u'99a07591-9449-4969-b167-9b51dcc404b6', u'port_security_enabled': True, u'port_id': u'99a07591-9449-4969-b167-9b51dcc404b6', u'fixed_ips': [{u'subnet_id': u'0c8122ce-2b6c-4a33-84b5-fc4e1858f704', u'ip_address': u'10.0.0.3'}], u'network_type': u'vlan'} 2018-01-09 15:08:03.753 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--columns=other_config', 'list', 'Port', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.764 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.765 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'set', 'Port', 'tap99a07591-94', 'other_config:segmentation_id=3333', 'other_config:physical_network=physnet1', 'other_config:net_uuid=4aef4a59-f2e0-4aa7-9cf9-28f1a9bd62c6', 'other_config:network_type=vlan'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.803 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.804 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] process_network_ports - iteration:43419 - treat_devices_added_or_updated completed. Skipped 0 devices of 5 devices currently available. Time elapsed: 0.267 process_network_ports /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1632 2018-01-09 15:08:03.804 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag,other_config', 'list', 'Port', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.819 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.819 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'set', 'Port', 'tap99a07591-94', 'other_config:segmentation_id=3333', 'other_config:tag=1', 'other_config:physical_network=physnet1', 'other_config:net_uuid=4aef4a59-f2e0-4aa7-9cf9-28f1a9bd62c6', 'other_config:network_type=vlan'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.840 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.840 11707 DEBUG neutron.agent.securitygroups_rpc [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Preparing device filters for 1 new devices setup_port_filters /opt/stack/neutron/neutron/agent/securitygroups_rpc.py:291 2018-01-09 15:08:03.841 11707 INFO neutron.agent.securitygroups_rpc [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Skipping method prepare_devices_filter as firewall is disabled or configured as NoopFirewallDriver. 2018-01-09 15:08:03.841 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag', 'list', 'Port', 'tap99a07591-94'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.853 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.854 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.869 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.870 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.880 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.881 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'dump-flows', 'br-int', 'table=25,in_port=21'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.890 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.891 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.903 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.904 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.919 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.919 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.927 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.927 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.940 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.941 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.963 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.964 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'set', 'Port', 'tap99a07591-94', 'tag=1'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 15:08:03.973 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 15:08:03.973 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Setting status for 99a07591-9449-4969-b167-9b51dcc404b6 to UP _bind_devices /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:876 2018-01-09 15:08:03.974 11707 DEBUG oslo_messaging._drivers.amqpdriver [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] CALL msg_id: 8f0987d53043404eaf38d0ed403e8202 exchange 'neutron' topic 'q-plugin' _send /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:454 2018-01-09 15:08:04.104 11707 DEBUG oslo_messaging._drivers.amqpdriver [-] received reply msg_id: 8f0987d53043404eaf38d0ed403e8202 __call__ /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:302 2018-01-09 15:08:04.105 11707 INFO neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Configuration for devices up [u'99a07591-9449-4969-b167-9b51dcc404b6'] and devices down [] completed. 2018-01-09 15:08:04.105 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:43419 - ports processed. Elapsed:0.679 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2036 2018-01-09 15:08:04.105 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:43419 completed. Processed ports statistics: {'regular': {'updated': 0, 'added': 1, 'removed': 0}}. Elapsed:0.679 loop_count_and_wait /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1772 |
从日志可以简单分析出,ovs agent是通过注册ovsdb的回调发现ofport的insert操作的,也就是add-port。之后的流程就是该怎么做怎么做了。
云主机关机tap设备删除操作的neutron-openvswitch-agent debug日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
2018-01-09 14:48:52.043 11707 DEBUG neutron.agent.linux.async_process [-] Output received from [ovsdb-client monitor Interface name,ofport,external_ids --format=json]: {"data":[["ddb9d7f9-cd8d-4fc7-8f03-8886e144095c","old",null,20,null],["","new","tap99a07591-94",-1,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} _read_stdout /opt/stack/neutron/neutron/agent/linux/async_process.py:233 2018-01-09 14:48:52.280 11707 DEBUG neutron.agent.linux.async_process [-] Output received from [ovsdb-client monitor Interface name,ofport,external_ids --format=json]: {"data":[["ddb9d7f9-cd8d-4fc7-8f03-8886e144095c","delete","tap99a07591-94",-1,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} _read_stdout /opt/stack/neutron/neutron/agent/linux/async_process.py:233 2018-01-09 14:48:52.606 11707 DEBUG oslo_messaging._drivers.amqpdriver [-] CALL msg_id: 9bb3690fc2e74ac9b83ae7f069132ab8 exchange 'neutron' topic 'q-reports-plugin' _send /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:454 2018-01-09 14:48:52.633 11707 DEBUG oslo_messaging._drivers.amqpdriver [-] received reply msg_id: 9bb3690fc2e74ac9b83ae7f069132ab8 __call__ /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:302 2018-01-09 14:48:53.201 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:42844 - starting polling. Elapsed:0.050 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1997 2018-01-09 14:48:53.202 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] retrying failed devices set([]) _update_port_info_failed_devices_stats /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1248 2018-01-09 14:48:53.202 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] retrying failed devices set([]) _update_port_info_failed_devices_stats /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1248 2018-01-09 14:48:53.203 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.213 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.213 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag', 'list', 'Port', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.221 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.222 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.233 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.233 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,external_ids,ofport', 'list', 'Interface', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.242 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.243 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.251 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.252 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.261 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.262 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.271 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.271 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.279 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.279 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-ofctl', 'del-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.286 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.287 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:42844 - port information retrieved. Elapsed:0.136 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2020 2018-01-09 14:48:53.287 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Starting to process devices in:{'current': set([u'e803e446-56ed-473e-9d57-63c598b6e315', u'c6cae3a6-7bf0-4587-9e07-8442d45a703c', u'01c11d8b-da68-48e5-8955-7c675261ab45', u'13193995-2b8a-450b-ac59-3184d2128bf6']), 'removed': set([u'99a07591-9449-4969-b167-9b51dcc404b6']), 'added': set([])} rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2027 2018-01-09 14:48:53.288 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.298 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.299 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag,other_config', 'list', 'Port', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.308 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.309 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'list-ports', 'br-int'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.319 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.320 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', '--if-exists', '--columns=name,tag', 'list', 'Port', 'int-br-ex', 'patch-tun', 'qg-e803e446-56', 'qr-01c11d8b-da', 'qr-c6cae3a6-7b', 'tap13193995-2b'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 14:48:53.329 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 14:48:53.329 11707 INFO neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Configuration for devices up [] and devices down [] completed. 2018-01-09 14:48:53.330 11707 INFO neutron.agent.securitygroups_rpc [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Remove device filter for set([u'99a07591-9449-4969-b167-9b51dcc404b6']) 2018-01-09 14:48:53.330 11707 INFO neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Ports set([u'99a07591-9449-4969-b167-9b51dcc404b6']) removed 2018-01-09 14:48:53.331 11707 DEBUG oslo_messaging._drivers.amqpdriver [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] CALL msg_id: 27a43b761b504a6f99272aedf4edde42 exchange 'neutron' topic 'q-plugin' _send /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:454 2018-01-09 14:48:53.456 11707 DEBUG oslo_messaging._drivers.amqpdriver [-] received reply msg_id: 27a43b761b504a6f99272aedf4edde42 __call__ /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:302 2018-01-09 14:48:53.457 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Port removal failed for set([]) treat_devices_removed /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1577 2018-01-09 14:48:53.458 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] process_network_ports - iteration:42844 - treat_devices_removed completed in 0.128 process_network_ports /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1653 2018-01-09 14:48:53.458 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:42844 - ports processed. Elapsed:0.307 rpc_loop /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:2036 2018-01-09 14:48:53.459 11707 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Agent rpc_loop - iteration:42844 completed. Processed ports statistics: {'regular': {'updated': 0, 'added': 0, 'removed': 1}}. Elapsed:0.308 loop_count_and_wait /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:1772 |
代码流程分析(neutron-openvswitch-agent启动流程可参考之前写的这篇文章):
|
|
def daemon_loop(self): # Start everything. LOG.info(_LI("Agent initialized successfully, now running... ")) signal.signal(signal.SIGTERM, self._handle_sigterm) if hasattr(signal, 'SIGHUP'): signal.signal(signal.SIGHUP, self._handle_sighup) with polling.get_polling_manager( ### ovsdb monitor poll manager初始化 self.minimize_polling, self.ovsdb_monitor_respawn_interval) as pm: self.rpc_loop(polling_manager=pm) |
|
|
@contextlib.contextmanager def get_polling_manager(minimize_polling=False, ovsdb_monitor_respawn_interval=( constants.DEFAULT_OVSDBMON_RESPAWN)): if minimize_polling: pm = InterfacePollingMinimizer( ovsdb_monitor_respawn_interval=ovsdb_monitor_respawn_interval) pm.start() ### 开始轮询 else: pm = base_polling.AlwaysPoll() try: yield pm finally: if minimize_polling: pm.stop() |
|
|
class InterfacePollingMinimizer(base_polling.BasePollingManager): """Monitors ovsdb to determine when polling is required.""" def __init__( self, ovsdb_monitor_respawn_interval=constants.DEFAULT_OVSDBMON_RESPAWN): super(InterfacePollingMinimizer, self).__init__() self._monitor = ovsdb_monitor.SimpleInterfaceMonitor( respawn_interval=ovsdb_monitor_respawn_interval) def start(self): self._monitor.start() |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
class OvsdbMonitor(async_process.AsyncProcess): """Manages an invocation of 'ovsdb-client monitor'.""" def __init__(self, table_name, columns=None, format=None, respawn_interval=None): cmd = ['ovsdb-client', 'monitor', table_name] ### ovsdb-client monitor命令 if columns: cmd.append(','.join(columns)) if format: cmd.append('--format=%s' % format) ### 返回json格式数据 super(OvsdbMonitor, self).__init__(cmd, run_as_root=True, respawn_interval=respawn_interval, log_output=True, die_on_error=True) class SimpleInterfaceMonitor(OvsdbMonitor): """Monitors the Interface table of the local host's ovsdb for changes. The has_updates() method indicates whether changes to the ovsdb Interface table have been detected since the monitor started or since the previous access. """ def __init__(self, respawn_interval=None): super(SimpleInterfaceMonitor, self).__init__( 'Interface', ### 监听ovsdb的Interface表 columns=['name', 'ofport', 'external_ids'], ### 具体到字段 format='json', respawn_interval=respawn_interval, ) self.new_events = {'added': [], 'removed': []} |
start:
|
|
def start(self, block=False, timeout=5): super(SimpleInterfaceMonitor, self).start() if block: with eventlet.timeout.Timeout(timeout): while not self.is_active(): eventlet.sleep() |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
class AsyncProcess(object): """Manages an asynchronous process. This class spawns a new process via subprocess and uses greenthreads to read stderr and stdout asynchronously into queues that can be read via repeatedly calling iter_stdout() and iter_stderr(). If respawn_interval is non-zero, any error in communicating with the managed process will result in the process and greenthreads being cleaned up and the process restarted after the specified interval. Example usage: >>> import time >>> proc = AsyncProcess(['ping']) >>> proc.start() >>> time.sleep(5) >>> proc.stop() >>> for line in proc.iter_stdout(): ... print(line) """ def __init__(self, cmd, run_as_root=False, respawn_interval=None, namespace=None, log_output=False, die_on_error=False): """Constructor. :param cmd: The list of command arguments to invoke. :param run_as_root: The process should run with elevated privileges. :param respawn_interval: Optional, the interval in seconds to wait to respawn after unexpected process death. Respawn will only be attempted if a value of 0 or greater is provided. :param namespace: Optional, start the command in the specified namespace. :param log_output: Optional, also log received output. :param die_on_error: Optional, kills the process on stderr output. """ self.cmd_without_namespace = cmd self._cmd = ip_lib.add_namespace_to_cmd(cmd, namespace) self.run_as_root = run_as_root if respawn_interval is not None and respawn_interval < 0: raise ValueError(_('respawn_interval must be >= 0 if provided.')) self.respawn_interval = respawn_interval self._process = None self._is_running = False self._kill_event = None self._reset_queues() self._watchers = [] self.log_output = log_output self.die_on_error = die_on_error ...... def start(self, block=False): """Launch a process and monitor it asynchronously. :param block: Block until the process has started. :raises eventlet.timeout.Timeout if blocking is True and the process did not start in time. """ LOG.debug('Launching async process [%s].', self.cmd) if self._is_running: raise AsyncProcessException(_('Process is already started')) else: self._spawn() if block: utils.wait_until_true(self.is_active) |
使用subprocess.Popen创建进程,通过neutron-rootwrap执行ovsdb monitor命令,然后用eventlet协程执行进程标准输出和标准错误的监听任务:
|
|
def _spawn(self): """Spawn a process and its watchers.""" self._is_running = True self._kill_event = eventlet.event.Event() self._process, cmd = utils.create_process(self._cmd, run_as_root=self.run_as_root) self._watchers = [] for reader in (self._read_stdout, self._read_stderr): # Pass the stop event directly to the greenthread to # ensure that assignment of a new event to the instance # attribute does not prevent the greenthread from using # the original event. watcher = eventlet.spawn(self._watch_process, reader, self._kill_event) self._watchers.append(watcher) |
|
|
def create_process(cmd, run_as_root=False, addl_env=None): """Create a process object for the given command. The return value will be a tuple of the process object and the list of command arguments used to create it. """ cmd = list(map(str, addl_env_args(addl_env) + cmd)) if run_as_root: cmd = shlex.split(config.get_root_helper(cfg.CONF)) + cmd LOG.debug("Running command: %s", cmd) obj = utils.subprocess_popen(cmd, shell=False, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) return obj, cmd |
|
|
def subprocess_popen(args, stdin=None, stdout=None, stderr=None, shell=False, env=None, preexec_fn=_subprocess_setup, close_fds=True): return subprocess.Popen(args, shell=shell, stdin=stdin, stdout=stdout, stderr=stderr, preexec_fn=preexec_fn, close_fds=close_fds, env=env) |
|
|
2018-01-08 15:00:21.704 11707 DEBUG neutron.agent.linux.async_process [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Launching async process [ovsdb-client monitor Interface name,ofport,external_ids --format=json]. start /opt/stack/neutron/neutron/agent/linux/async_process.py:109 2018-01-08 15:00:21.705 11707 DEBUG neutron.agent.linux.utils [req-6166e22e-9cb7-4a6f-80e7-52d90f318dee - -] Running command: ['sudo', '/usr/bin/neutron-rootwrap', '/etc/neutron/rootwrap.conf', 'ovsdb-client', 'monitor', 'Interface', 'name,ofport,external_ids', '--format=json'] create_process /opt/stack/neutron/neutron/agent/linux/utils.py:90 |
ovsdb-client monitor功能验证:
|
|
[root@host-10-0-80-25 neutron]# ovsdb-client monitor Interface name,ofport,external_ids --format=json ### 首次启动后返回信息: {"data":[["d3712334-36a5-4d57-b22f-2be8799154b2","initial","qg-e803e446-56",5,["map",[["attached-mac","fa:16:3e:18:8e:14"],["iface-id","e803e446-56ed-473e-9d57-63c598b6e315"],["iface-status","active"]]]],["c710bde6-1a5f-4d5f-8dc1-d44d0be4c07a","initial","int-br-ex",1,["map",[]]],["ddca3b71-0516-4b8b-814c-ade92d0dcce7","initial","br-int",65534,["map",[]]],["eef89ed1-2541-4ac8-a080-512b0776546b","initial","patch-int",1,["map",[]]],["7e01a355-0cb7-4651-82b2-9cc8540e748a","initial","qr-c6cae3a6-7b",6,["map",[["attached-mac","fa:16:3e:e3:73:ae"],["iface-id","c6cae3a6-7bf0-4587-9e07-8442d45a703c"],["iface-status","active"]]]],["c07bb0ca-25fe-40c1-b558-069ee659cb83","initial","patch-tun",2,["map",[]]],["89d9b5cc-311d-41bd-8199-980f1044e639","initial","tap13193995-2b",7,["map",[["attached-mac","fa:16:3e:95:6c:32"],["iface-id","13193995-2b8a-450b-ac59-3184d2128bf6"],["iface-status","active"]]]],["7f9d1b6d-7271-493b-a677-696b37182b61","initial","br-ex",65534,["map",[]]],["6cb438ef-d95e-4743-b0db-6055f7677796","initial","br-tun",65534,["map",[]]],["20ee0a84-c9aa-49a5-83da-fa722ee415e5","initial","tap99a07591-94",21,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]],["70a434af-22ef-404b-8dd5-fc5402ec1b81","initial","phy-br-ex",2,["map",[]]],["bc60c764-76aa-44cc-b946-248b43819b85","initial","eth1",1,["map",[]]],["2919bece-e740-453b-9709-770dccfc42b8","initial","qr-01c11d8b-da",4,["map",[["attached-mac","fa:16:3e:c4:75:eb"],["iface-id","01c11d8b-da68-48e5-8955-7c675261ab45"],["iface-status","active"]]]]],"headings":["row","action","name","ofport","external_ids"]} ### nova stop命令执行后返回信息: {"data":[["20ee0a84-c9aa-49a5-83da-fa722ee415e5","old",null,21,null],["","new","tap99a07591-94",-1,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} {"data":[["20ee0a84-c9aa-49a5-83da-fa722ee415e5","delete","tap99a07591-94",-1,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} ### nova start命令执行后返回信息: {"data":[["1cdd4d00-470f-42c5-8f29-24f10bdd31a6","insert","tap99a07591-94",["set",[]],["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} {"data":[["1cdd4d00-470f-42c5-8f29-24f10bdd31a6","old",null,["set",[]],null],["","new","tap99a07591-94",22,["map",[["attached-mac","fa:16:3e:21:96:bc"],["iface-id","99a07591-9449-4969-b167-9b51dcc404b6"],["iface-status","active"],["vm-id","cd871a8b-2d7a-4a43-ba63-ef64fbbfe0b7"]]]]],"headings":["row","action","name","ofport","external_ids"]} |
参考资料:
ovsdb monitor的流程已经分析完了,下面要看下监听到有port变更之后的处理流程,主要是在rpc_loop方法里面进行的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
if (self._agent_has_updates(polling_manager) or sync or devices_need_retry): try: LOG.debug("Agent rpc_loop - iteration:%(iter_num)d - " "starting polling. Elapsed:%(elapsed).3f", {'iter_num': self.iter_num, 'elapsed': time.time() - start}) # Save updated ports dict to perform rollback in # case resync would be needed, and then clear # self.updated_ports. As the greenthread should not yield # between these two statements, this will be thread-safe updated_ports_copy = self.updated_ports self.updated_ports = set() (port_info, ancillary_port_info, consecutive_resyncs, ports_not_ready_yet) = (self.process_port_info( start, polling_manager, sync, ovs_restarted, ports, ancillary_ports, updated_ports_copy, consecutive_resyncs, ports_not_ready_yet, failed_devices, failed_ancillary_devices)) sync = False self.process_deleted_ports(port_info) |
|
|
def _agent_has_updates(self, polling_manager): return (polling_manager.is_polling_required or self.updated_ports or self.deleted_ports or self.sg_agent.firewall_refresh_needed()) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
@property def is_polling_required(self): # Always consume the updates to minimize polling. polling_required = self._is_polling_required() # Polling is required regardless of whether updates have been # detected. if self._force_polling: self._force_polling = False polling_required = True # Polling is required if not yet done for previously detected # updates. if not self._polling_completed: polling_required = True if polling_required: # Track whether polling has been completed to ensure that # polling can be required until the caller indicates via a # call to polling_completed() that polling has been # successfully performed. self._polling_completed = False return polling_required |
|
|
def _is_polling_required(self): # Maximize the chances of update detection having a chance to # collect output. eventlet.sleep() return self._monitor.has_updates |
|
|
@property def has_updates(self): """Indicate whether the ovsdb Interface table has been updated. If the monitor process is not active an error will be logged since it won't be able to communicate any update. This situation should be temporary if respawn_interval is set. """ if not self.is_active(): LOG.error(_LE("Interface monitor is not active")) else: self.process_events() return bool(self.new_events['added'] or self.new_events['removed']) |
检查到ovsdb有新增或者删除的port就继续处理,当然条件有好几个,看日志输出可以发现每秒都会执行一次
LOG.debug("Agent rpc_loop - iteration:%d started", self.iter_num) ,但并不是每次都执行
LOG.debug("Agent rpc_loop - iteration:%(iter_num)d - starting polling. Elapsed:%(elapsed).3f", {'iter_num': self.iter_num, 'elapsed': time.time() - start}) ,只有端口变更才会执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
def get_events(self): ### 注意,get events过程会清空之前缓存的ovsdb monitor events self.process_events() events = self.new_events self.new_events = {'added': [], 'removed': []} return events def process_events(self): ### 解析ovsdb monitor命令行输出的json数据 devices_added = [] devices_removed = [] dev_to_ofport = {} for row in self.iter_stdout(): json = jsonutils.loads(row).get('data') for ovs_id, action, name, ofport, external_ids in json: if external_ids: external_ids = ovsdb.val_to_py(external_ids) if ofport: ofport = ovsdb.val_to_py(ofport) device = {'name': name, 'ofport': ofport, 'external_ids': external_ids} if action in (OVSDB_ACTION_INITIAL, OVSDB_ACTION_INSERT): devices_added.append(device) elif action == OVSDB_ACTION_DELETE: devices_removed.append(device) elif action == OVSDB_ACTION_NEW: dev_to_ofport[name] = ofport self.new_events['added'].extend(devices_added) self.new_events['removed'].extend(devices_removed) # update any events with ofports received from 'new' action for event in self.new_events['added']: event['ofport'] = dev_to_ofport.get(event['name'], event['ofport']) |
|
|
OVSDB_ACTION_INITIAL = 'initial' OVSDB_ACTION_INSERT = 'insert' OVSDB_ACTION_DELETE = 'delete' OVSDB_ACTION_NEW = 'new' |
process_port_info先获取所有port插入、删除事件,然后调用process_ports_events进行处理:
|
|
else: consecutive_resyncs = 0 events = polling_manager.get_events() port_info, ancillary_port_info, ports_not_ready_yet = ( self.process_ports_events(events, ports, ancillary_ports, ports_not_ready_yet, failed_devices, failed_ancillary_devices, updated_ports_copy)) return (port_info, ancillary_port_info, consecutive_resyncs, ports_not_ready_yet) |
process_ports_events只是分析下哪些port被添加了、哪些port被删除了,然后返回给port_info,并没有执行实际的流表操作,经过调试流表操作是在下面的几个方法里面执行的。
nova start开机流程(neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent.OVSNeutronAgent#_bind_devices执行流表添加操作):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[root@host-10-0-80-25 ~]# ovs-ofctl dump-flows br-int ### after _add_port_tag_info NXST_FLOW reply (xid=0x4): cookie=0xa78ae53178456044, duration=2030.478s, table=0, n_packets=0, n_bytes=0, idle_age=65534, priority=3,in_port=1,dl_vlan=3333 actions=mod_vlan_vid:1,NORMAL cookie=0xa78ae53178456044, duration=2035.210s, table=0, n_packets=2039, n_bytes=122340, idle_age=0, priority=2,in_port=1 actions=drop cookie=0xa78ae53178456044, duration=2035.305s, table=0, n_packets=26, n_bytes=4082, idle_age=164, priority=0 actions=NORMAL cookie=0xa78ae53178456044, duration=2035.300s, table=23, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=2035.295s, table=24, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop [root@host-10-0-80-25 ~]# [root@host-10-0-80-25 ~]# ovs-ofctl dump-flows br-int ### after _bind_devices NXST_FLOW reply (xid=0x4): cookie=0xa78ae53178456044, duration=12.588s, table=0, n_packets=0, n_bytes=0, idle_age=12, priority=10,icmp6,in_port=25,icmp_type=136 actions=resubmit(,24) cookie=0xa78ae53178456044, duration=12.571s, table=0, n_packets=0, n_bytes=0, idle_age=12, priority=10,arp,in_port=25 actions=resubmit(,24) cookie=0xa78ae53178456044, duration=2051.753s, table=0, n_packets=2056, n_bytes=123360, idle_age=0, priority=2,in_port=1 actions=drop cookie=0xa78ae53178456044, duration=12.610s, table=0, n_packets=0, n_bytes=0, idle_age=12, priority=9,in_port=25 actions=resubmit(,25) cookie=0xa78ae53178456044, duration=2047.021s, table=0, n_packets=0, n_bytes=0, idle_age=65534, priority=3,in_port=1,dl_vlan=3333 actions=mod_vlan_vid:1,NORMAL cookie=0xa78ae53178456044, duration=2051.848s, table=0, n_packets=26, n_bytes=4082, idle_age=181, priority=0 actions=NORMAL cookie=0xa78ae53178456044, duration=2051.843s, table=23, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=12.597s, table=24, n_packets=0, n_bytes=0, idle_age=12, priority=2,icmp6,in_port=25,icmp_type=136,nd_target=fe80::f816:3eff:fe21:96bc actions=NORMAL cookie=0xa78ae53178456044, duration=12.579s, table=24, n_packets=0, n_bytes=0, idle_age=12, priority=2,arp,in_port=25,arp_spa=10.0.0.3 actions=resubmit(,25) cookie=0xa78ae53178456044, duration=2051.838s, table=24, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=12.632s, table=25, n_packets=0, n_bytes=0, idle_age=12, priority=2,in_port=25,dl_src=fa:16:3e:21:96:bc actions=NORMAL |
neutron-openvswitch-agent流表操作相关命令行日志:
|
|
2018-01-09 18:31:05.617 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.627 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.629 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.637 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.639 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.646 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.647 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.655 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.657 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-ofctl', 'add-flows', 'br-int', '-'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.664 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.665 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Running command (rootwrap daemon): ['ovs-vsctl', '--timeout=10', '--oneline', '--format=json', '--', 'set', 'Port', 'tap99a07591-94', 'tag=1'] execute_rootwrap_daemon /opt/stack/neutron/neutron/agent/linux/utils.py:106 2018-01-09 18:31:05.675 3620 DEBUG neutron.agent.linux.utils [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Exit code: 0 execute /opt/stack/neutron/neutron/agent/linux/utils.py:148 2018-01-09 18:31:05.680 3620 DEBUG neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Setting status for 99a07591-9449-4969-b167-9b51dcc404b6 to UP _bind_devices /opt/stack/neutron/neutron/plugins/ml2/drivers/openvswitch/agent/ovs_neutron_agent.py:876 2018-01-09 18:31:05.682 3620 DEBUG oslo_messaging._drivers.amqpdriver [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] CALL msg_id: 4ac24edbb5034dcf89cd22eb8e4d848e exchange 'neutron' topic 'q-plugin' _send /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:454 2018-01-09 18:31:05.808 3620 DEBUG oslo_messaging._drivers.amqpdriver [-] received reply msg_id: 4ac24edbb5034dcf89cd22eb8e4d848e __call__ /usr/lib/python2.7/site-packages/oslo_messaging/_drivers/amqpdriver.py:302 2018-01-09 18:31:05.811 3620 INFO neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent [req-f6d7b7af-1d0d-47fb-8f1c-5bedf23b2bfa - -] Configuration for devices up [u'99a07591-9449-4969-b167-9b51dcc404b6'] and devices down [] completed. |
nova stop关机流程(neutron.plugins.ml2.drivers.openvswitch.agent.ovs_neutron_agent.OVSNeutronAgent#update_stale_ofport_rules方法里面执行流表删除操作):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
[root@host-10-0-80-25 ~]# ovs-ofctl dump-flows br-int ### before delete_arp_spoofing_protection NXST_FLOW reply (xid=0x4): cookie=0xa78ae53178456044, duration=130.059s, table=0, n_packets=0, n_bytes=0, idle_age=151, priority=10,icmp6,in_port=23,icmp_type=136 actions=resubmit(,24) cookie=0xa78ae53178456044, duration=130.047s, table=0, n_packets=1, n_bytes=42, idle_age=129, priority=10,arp,in_port=23 actions=resubmit(,24) cookie=0xa78ae53178456044, duration=1549.417s, table=0, n_packets=1551, n_bytes=93060, idle_age=0, priority=2,in_port=1 actions=drop cookie=0xa78ae53178456044, duration=130.072s, table=0, n_packets=1, n_bytes=301, idle_age=129, priority=9,in_port=23 actions=resubmit(,25) cookie=0xa78ae53178456044, duration=1544.685s, table=0, n_packets=0, n_bytes=0, idle_age=65534, priority=3,in_port=1,dl_vlan=3333 actions=mod_vlan_vid:1,NORMAL cookie=0xa78ae53178456044, duration=1549.512s, table=0, n_packets=4, n_bytes=783, idle_age=129, priority=0 actions=NORMAL cookie=0xa78ae53178456044, duration=1549.507s, table=23, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=130.066s, table=24, n_packets=0, n_bytes=0, idle_age=130, priority=2,icmp6,in_port=23,icmp_type=136,nd_target=fe80::f816:3eff:fe21:96bc actions=NORMAL cookie=0xa78ae53178456044, duration=130.053s, table=24, n_packets=1, n_bytes=42, idle_age=129, priority=2,arp,in_port=23,arp_spa=10.0.0.3 actions=resubmit(,25) cookie=0xa78ae53178456044, duration=1549.502s, table=24, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=130.082s, table=25, n_packets=2, n_bytes=343, idle_age=129, priority=2,in_port=23,dl_src=fa:16:3e:21:96:bc actions=NORMAL [root@host-10-0-80-25 ~]# [root@host-10-0-80-25 ~]# ovs-ofctl dump-flows br-int ### after delete_arp_spoofing_protection NXST_FLOW reply (xid=0x4): cookie=0xa78ae53178456044, duration=1553.617s, table=0, n_packets=0, n_bytes=0, idle_age=65534, priority=3,in_port=1,dl_vlan=3333 actions=mod_vlan_vid:1,NORMAL cookie=0xa78ae53178456044, duration=1558.349s, table=0, n_packets=1560, n_bytes=93600, idle_age=0, priority=2,in_port=1 actions=drop cookie=0xa78ae53178456044, duration=1558.444s, table=0, n_packets=4, n_bytes=783, idle_age=138, priority=0 actions=NORMAL cookie=0xa78ae53178456044, duration=1558.439s, table=23, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=1558.434s, table=24, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=139.014s, table=25, n_packets=2, n_bytes=343, idle_age=138, priority=2,in_port=23,dl_src=fa:16:3e:21:96:bc actions=NORMAL [root@host-10-0-80-25 ~]# [root@host-10-0-80-25 ~]# ovs-ofctl dump-flows br-int ### after set_allowed_macs_for_port NXST_FLOW reply (xid=0x4): cookie=0xa78ae53178456044, duration=1564.409s, table=0, n_packets=0, n_bytes=0, idle_age=65534, priority=3,in_port=1,dl_vlan=3333 actions=mod_vlan_vid:1,NORMAL cookie=0xa78ae53178456044, duration=1569.141s, table=0, n_packets=1570, n_bytes=94200, idle_age=1, priority=2,in_port=1 actions=drop cookie=0xa78ae53178456044, duration=1569.236s, table=0, n_packets=4, n_bytes=783, idle_age=149, priority=0 actions=NORMAL cookie=0xa78ae53178456044, duration=1569.231s, table=23, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop cookie=0xa78ae53178456044, duration=1569.226s, table=24, n_packets=0, n_bytes=0, idle_age=65534, priority=0 actions=drop |
关机流程的日志就不贴了。
另外上面流表内容我现在也只有个模糊的概念,后面会把每条表项的意义搞清楚,这个会专门写一篇文章。