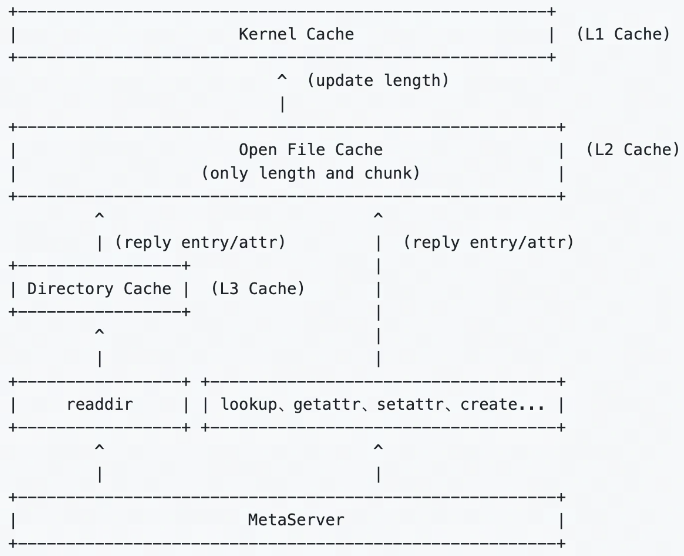
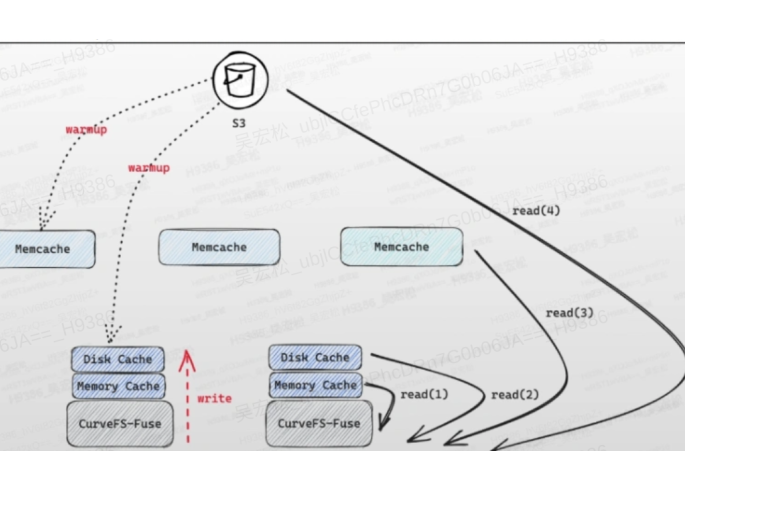
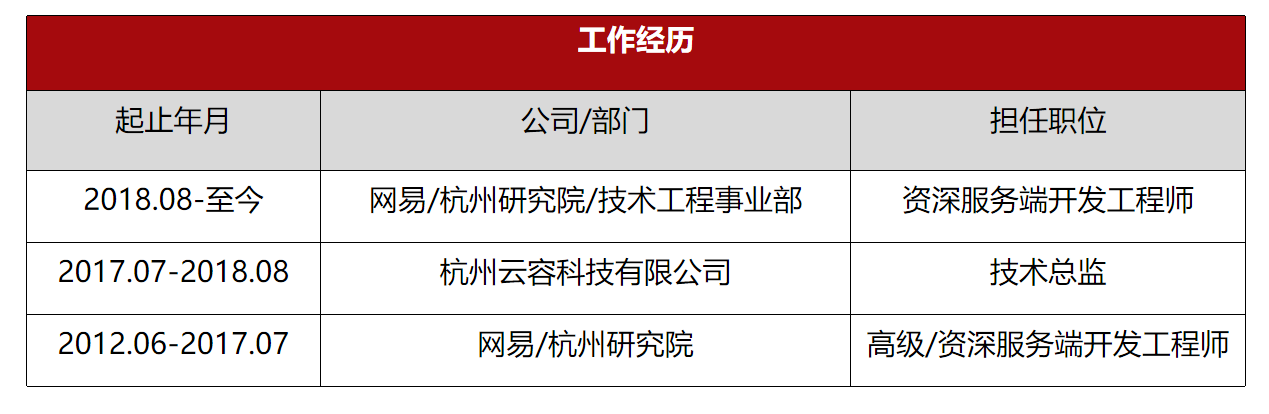
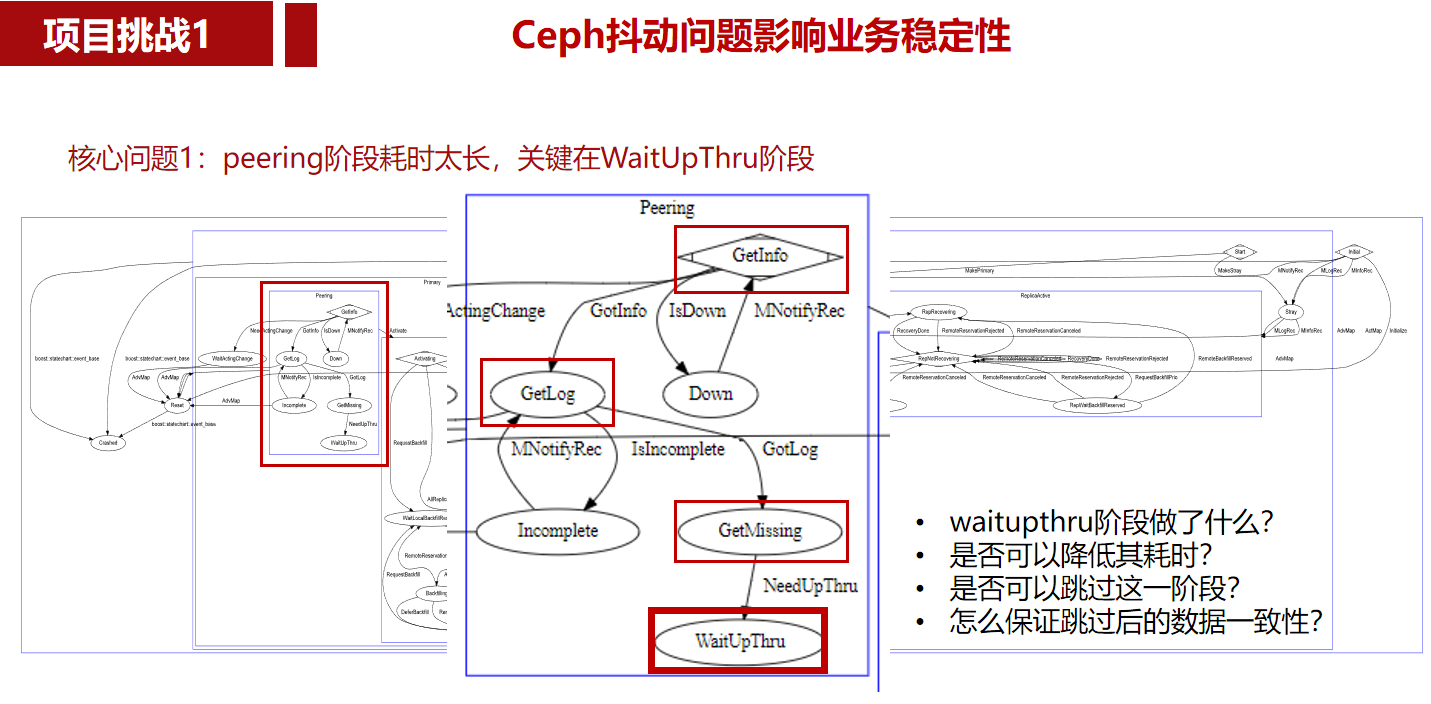
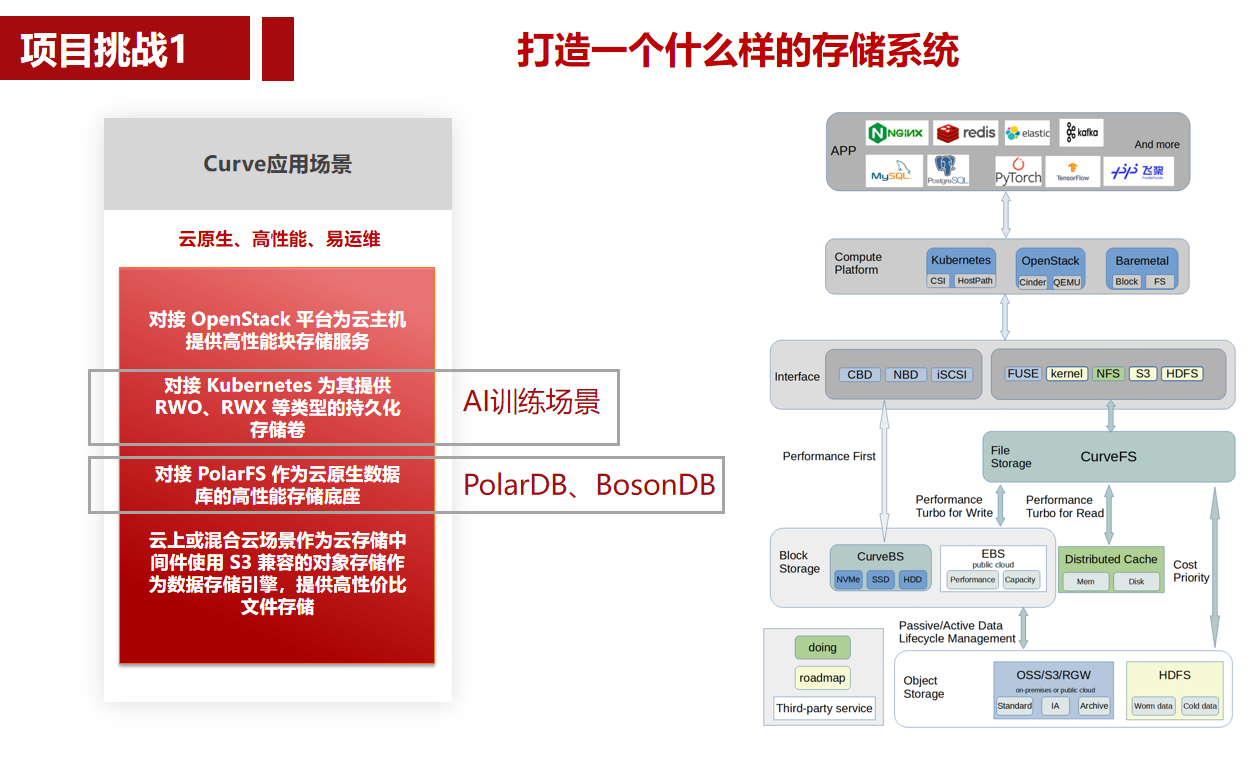
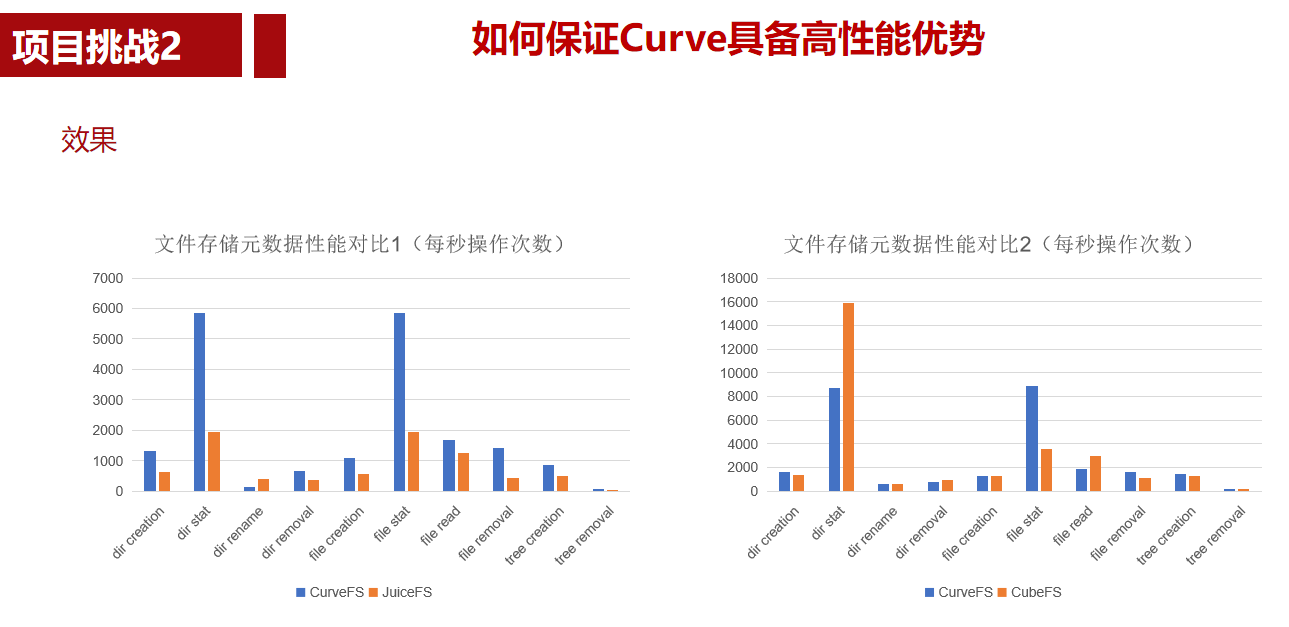
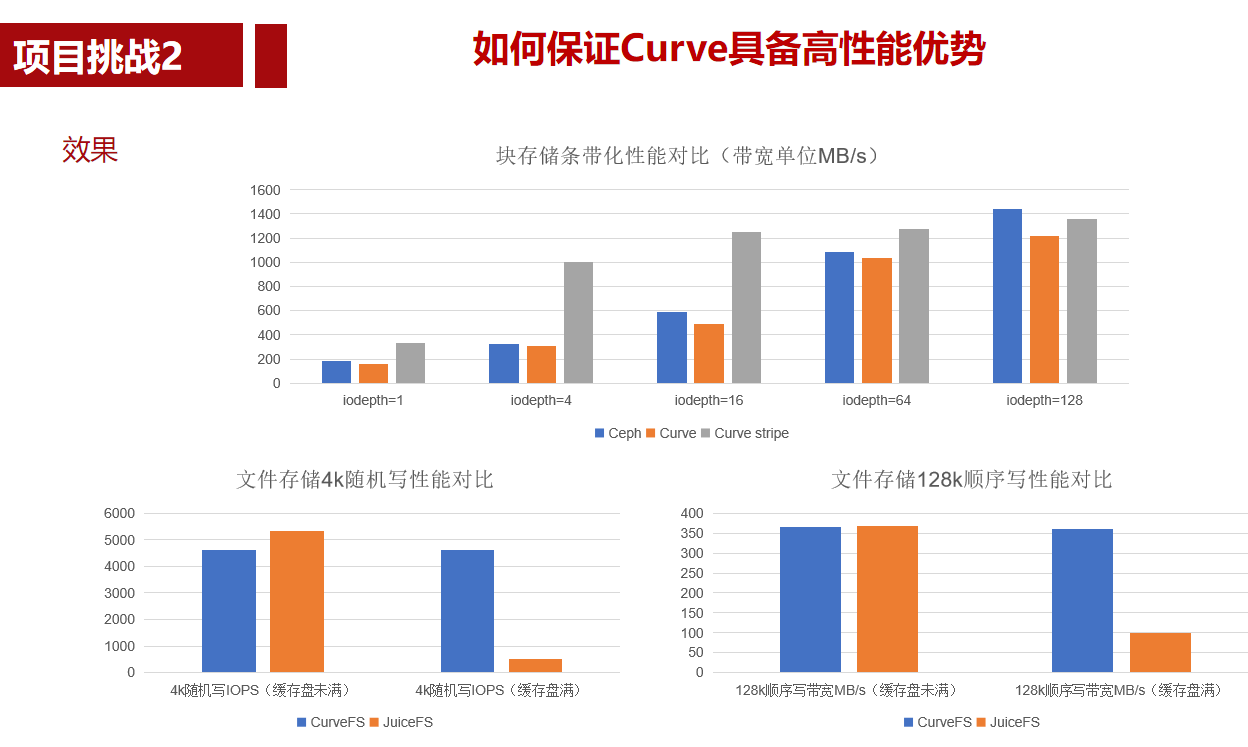
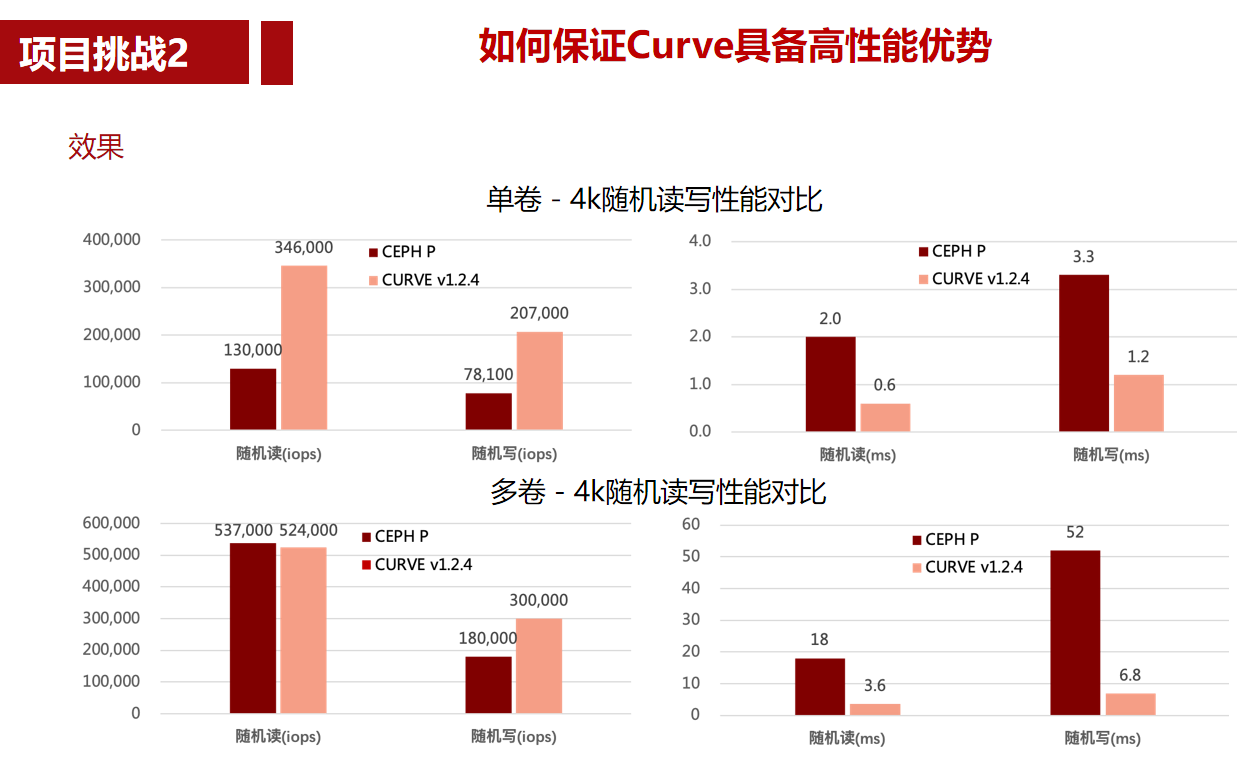
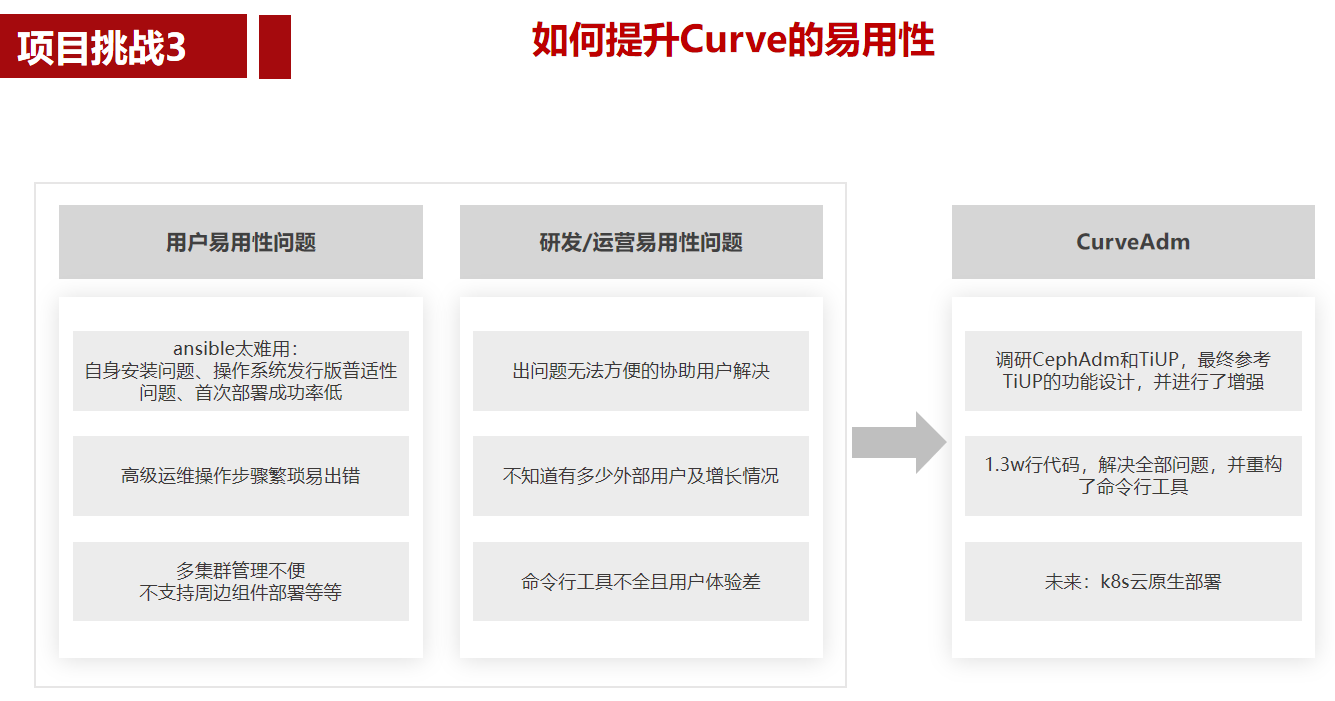
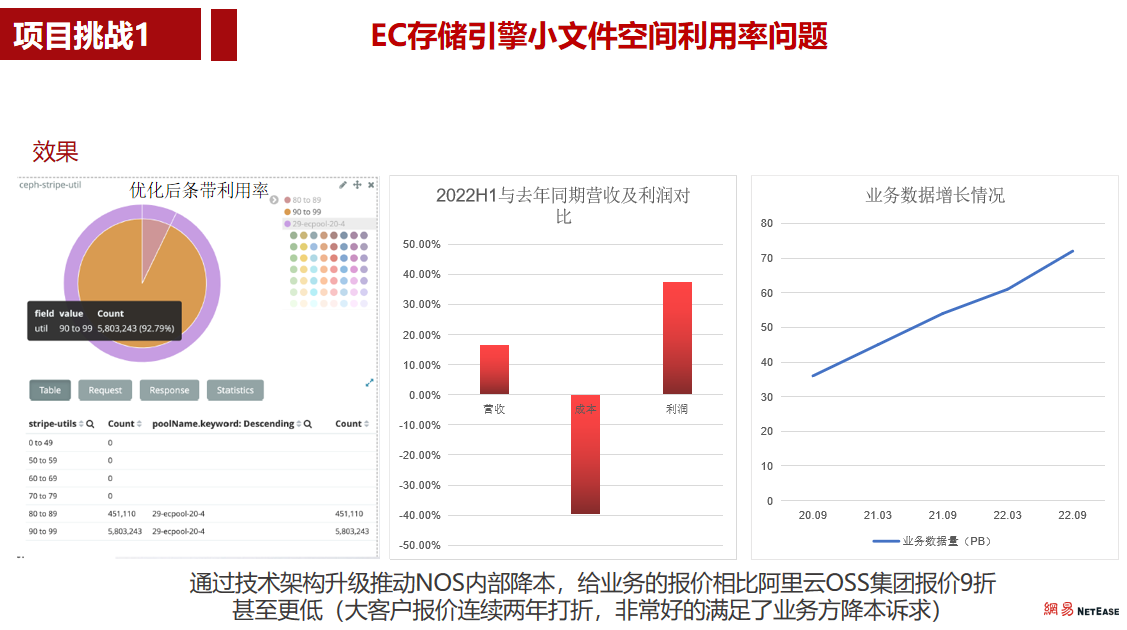
1. rocksdb库安装及命令行工具试用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# install rocksdb on ubuntu 22.04 sudo apt install librocksdb-dev librocksdb6.11 rocksdb-tools # list cli tools $ dpkg -L rocksdb-tools /usr/bin/cache_bench /usr/bin/db_bench /usr/bin/ldb /usr/bin/persistent_cache_bench /usr/bin/sst_dump # try cli tools 2023 ldb --db=/tmp/testdb dump 2024 ldb --db=/tmp/testdb idump 2036 ldb --db=/tmp/testdb checkpoint --checkpoint_dir=/tmp/checkpoint 2040 ldb --db=/tmp/checkpoint dump 2041 ldb --db=/tmp/testdb put a b 2042 ldb --db=/tmp/checkpoint get a 2044 ldb --db=/tmp/checkpoint get 1 2045 ldb --db=/tmp/testdb get 1 2046 ldb --db=/tmp/testdb get a 2047 ldb --db=/tmp/testdb delete a 2048 ldb --db=/tmp/testdb get a 2049 ldb --db=/tmp/testdb scan 2050 ldb --db=/tmp/checkpoint put a bbbbbb 2051 ldb --db=/tmp/checkpoint get a |
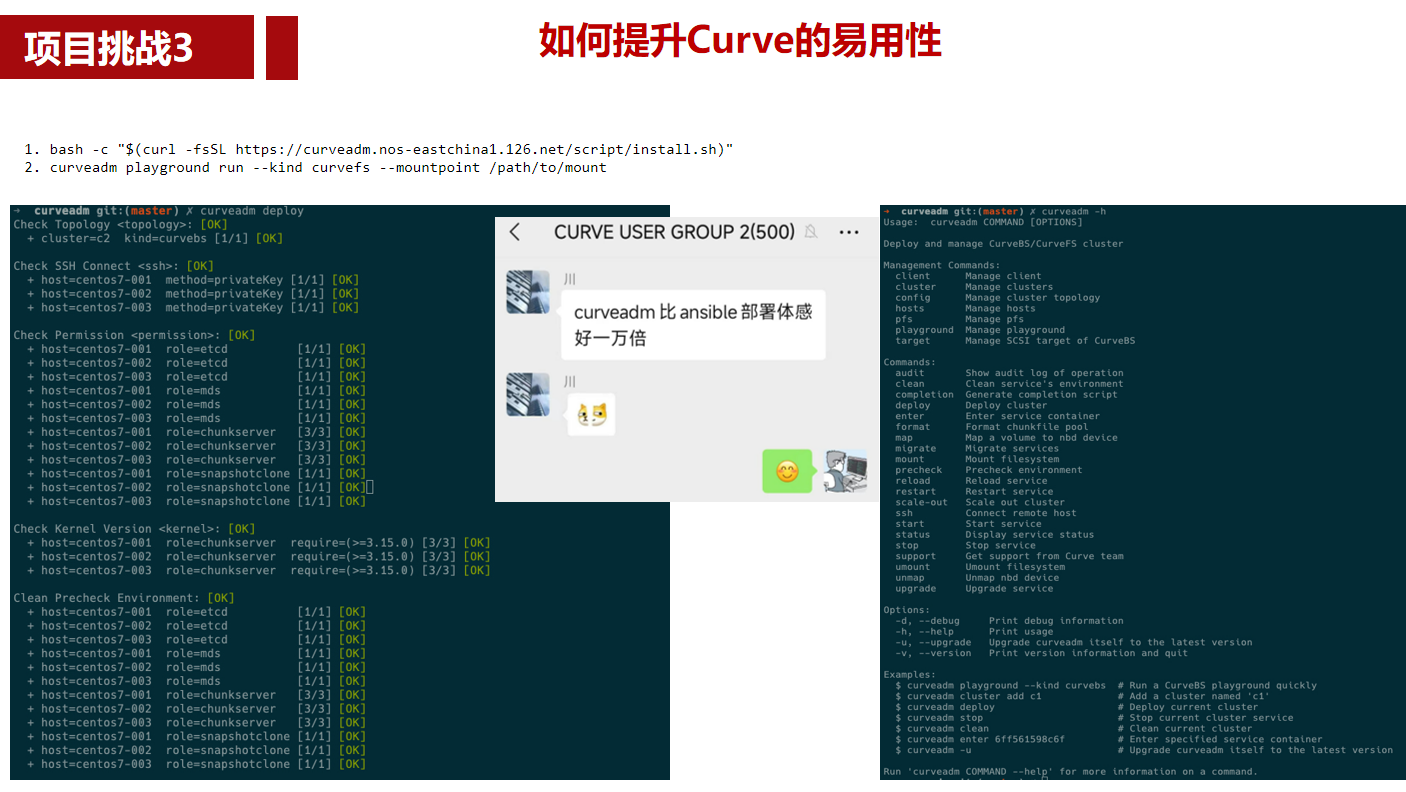
2. CRUD示例代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
#include <cassert> #include <iostream> #include <string> #include <rocksdb/db.h> #include <rocksdb/iterator.h> #include <rocksdb/options.h> #include <rocksdb/slice.h> #include <rocksdb/status.h> #include <rocksdb/write_batch.h> int main() { rocksdb::DB* db; rocksdb::Options options; options.create_if_missing = true; // 打开数据库 rocksdb::Status status = rocksdb::DB::Open(options, "/tmp/testdb", &db); assert(status.ok()); // 插入key-value std::string key = "key"; std::string value = "value"; status = db->Put(rocksdb::WriteOptions(), key, value); assert(status.ok()); // 获取value std::string result; status = db->Get(rocksdb::ReadOptions(), key, &result); assert(status.ok()); assert(result == value); // 更新value std::string new_value = "new_value"; status = db->Put(rocksdb::WriteOptions(), key, new_value); assert(status.ok()); // 再次获取value status = db->Get(rocksdb::ReadOptions(), key, &result); assert(status.ok()); assert(result == new_value); // 删除key-value status = db->Delete(rocksdb::WriteOptions(), key); assert(status.ok()); // 再次获取value,应该失败 status = db->Get(rocksdb::ReadOptions(), key, &result); assert(status.IsNotFound()); // 插入一些key-value for (int i = 0; i < 10; ++i) { status = db->Put(rocksdb::WriteOptions(), std::to_string(i), "value" + std::to_string(i)); assert(status.ok()); } // 创建迭代器 rocksdb::Iterator* it = db->NewIterator(rocksdb::ReadOptions()); // 遍历数据库 for (it->SeekToFirst(); it->Valid(); it->Next()) { std::cout << it->key().ToString() << ": " << it->value().ToString() << std::endl; } assert(it->status().ok()); // 检查迭代器是否出错 // 遍历数据库,只遍历key为"3"到"7"的键值对 std::string start_key = "3"; std::string end_key = "7"; // 从start_key开始遍历到end_key for (it->Seek(start_key); it->Valid() && it->key().ToString() <= end_key; it->Next()) { std::cout << it->key().ToString() << ": " << it->value().ToString() << std::endl; } assert(it->status().ok()); // 检查迭代器是否出错 // 插入一些key-value for (int i = 0; i < 10; ++i) { status = db->Put(rocksdb::WriteOptions(), "prefix" + std::to_string(i), "value" + std::to_string(i)); assert(status.ok()); } delete it; // 创建迭代器 rocksdb::ReadOptions read_options; read_options.prefix_same_as_start = true; it = db->NewIterator(read_options); // 遍历具有特定前缀的键值对 for (it->Seek("prefix"); it->Valid() && it->key().starts_with("prefix"); it->Next()) { std::cout << it->key().ToString() << ": " << it->value().ToString() << std::endl; } assert(it->status().ok()); // 检查迭代器是否出错 delete it; // 关闭数据库 delete db; return 0; } |
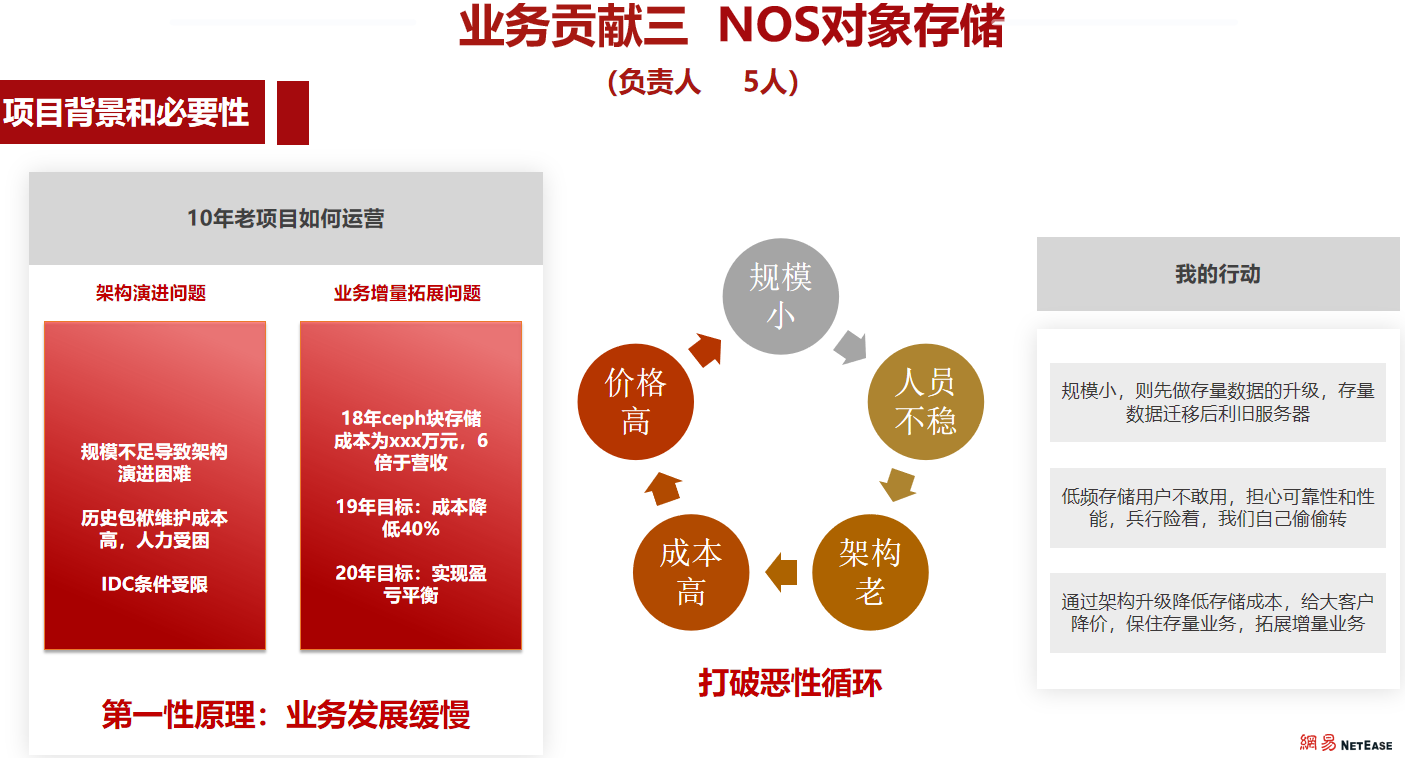
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
netease@hih-l-9493:~/playground/cpp$ g++ main.cpp -lrocksdb netease@hih-l-9493:~/playground/cpp$ ./a.out 0: value0 1: value1 2: value2 3: value3 4: value4 5: value5 6: value6 7: value7 8: value8 9: value9 a: b prefix0: value0 prefix1: value1 prefix2: value2 prefix3: value3 prefix4: value4 prefix5: value5 prefix6: value6 prefix7: value7 prefix8: value8 prefix9: value9 3: value3 4: value4 5: value5 6: value6 7: value7 prefix0: value0 prefix1: value1 prefix2: value2 prefix3: value3 prefix4: value4 prefix5: value5 prefix6: value6 prefix7: value7 prefix8: value8 prefix9: value9 |