1. 大数据存储技术架构演进趋势
1.1 趋势一:湖仓一体
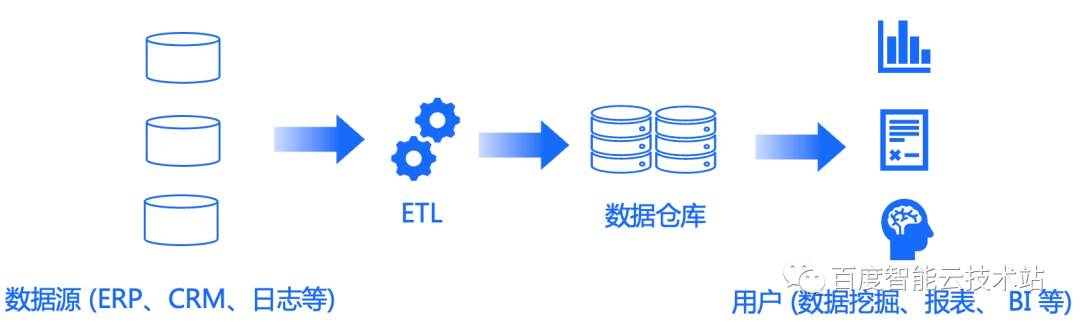
数据仓库
数据仓库 = 结构化数据存储系统 + 内置计算引擎 + SQL 接口
相关项目开源项目:
- Clickhouse(https://clickhouse.com/)
- Starrocks(https://www.starrocks.io/)
- Doris(https://doris.apache.org/)
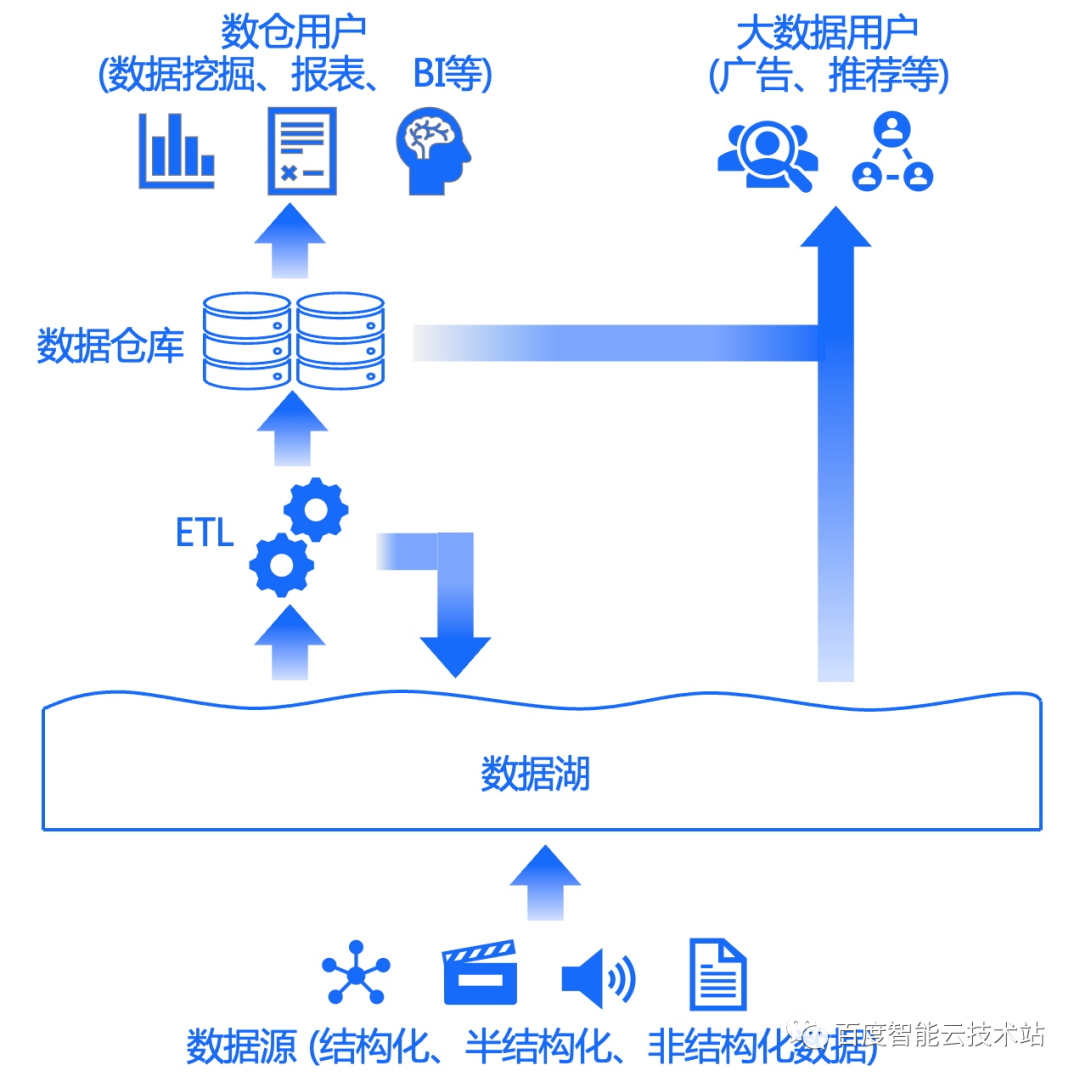
数据湖
数据湖 = 原始数据存储系统 + 多种计算引擎 + 包含 SQL 在内的多种接口
支持的存储系统多种多样,需要进行数据ETL处理。
存储类型:存算一体和存算分离两类数据湖。存算一体主要是Hadoop生态体系,存算分离主要基于对象存储+缓存加速层,或者HDFS的替代产品OZone。
湖仓一体
湖仓一体 = 配备元数据层和加速层的对象存储 + 数据仓库、大数据、AI、HPC 等各个领域的计算引擎 + 包含SQL 在内的多种接口
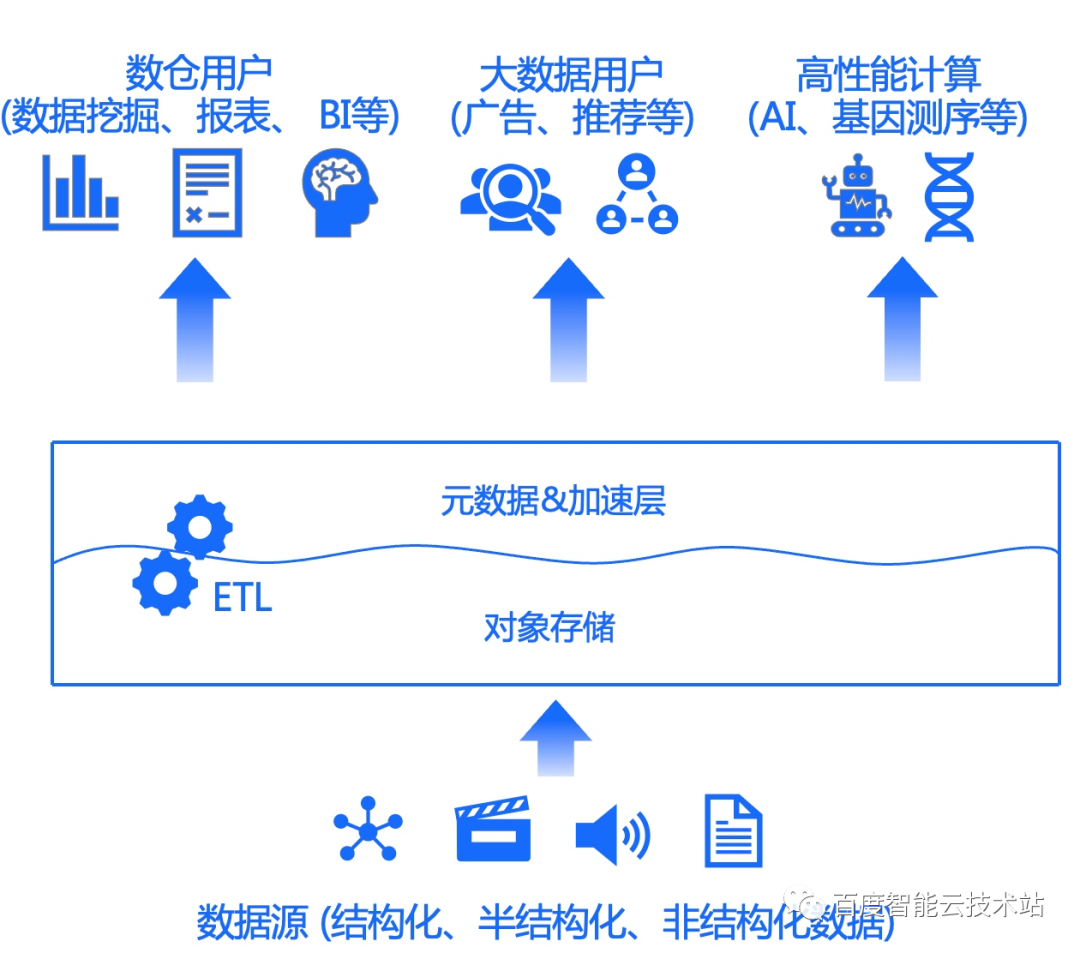
相关项目:
- 公有云大数据平台:各类EMR平台+加速层+对象存储
- 使用对象存储做为存储底座,提供HDFS接口适配
- 配备数据加速层,大部分配备元数据层
- Alluxio/JuiceFS/CurveFS:开源中立对象存储加速中间件
参考资料
1.2 趋势二:冷热分离
冷热一体
低版本的各类数据平台基本都是存算一体的。
如ES、CK、SR、Spark/Hive/Flink+HDFS等等。
冷热分离
基于成本优化考虑,以及热冷数据的28分布原则,基本所有的数仓产品都提供冷热分离存储方案,热数据在HDFS、冷数据存储到S3兼容的对象存储中。
冷热分离是存算分离的前奏,大部分项目是直接使用S3接口,没有缓存加速层。
- 数据库类:
- MySQL – 通过一些插件可以将冷数据存到S3,如 MyDumper、Spider、LiunxServer
- ClickHouse – 支持使用S3作为冷数据存储
- ElasticSearch – 支持使用S3作为snapshot备份存储
- Cassandra – 支持将S3用作外部存储
- MongoDB Atlas – 提供与S3的集成方案
- 数据处理类:
- Spark – 支持读取和写入S3数据
- Hive – 可以将对象存储服务作为外部表(External Table)来使用,实现对对象存储服务中数据的查询
- HBase – 以将对象存储服务作为后端存储(Backend Storage)来使用,实现对HBase表中数据的持久化
- Kafka – 支持将topic日志备份到S3
- Flink – 可以将checkpoint数据保存到S3
- Pulsar – 可以与S3集成作为tiered storage
- Hadoop – 支持在HDFS之外使用S3作为数据存储
- Presto – 支持使用S3作为存储层
- Apache Doris 2.0 – 支持冷数据存储到对象存储
1.3 趋势三:云原生
存算一体
传统部署方案下,计算引擎不需要弹性调度,固定运行在一组存算一体的节点上。与冷热一体类似,低版本的数据平台也都是存算一体的。
存算分离
云原生化部署的大数据平台驱动了大数据存储从冷热分离到彻底的存算分离。云原生大数据平台主要基于K8S算力平台进行计算引擎的弹性调度,存算分离是基础条件,要实现计算引擎的弹性云原生部署,天然需要做到存算分离。私有化的云原生大数据平台可以使用HDFS或是S3作为底层存储。
而基于公有云部署的大数据平台则只能依赖公有云提供的大数据存储服务,传统IDC部署HDFS方案不适合云上部署,公有云上的大数据存储基本都是基于对象存储提供的。
存算分离的驱动因素主要包括:
- 降本增效:计算、存储资源利用率,运维成本
- 硬件发展:高速网络、高密专用存储服务器
- 云原生化:云原生场景下的必然选择
- 对象存储:生态繁荣、低成本、免运维、灵活弹性
相关项目:
- 2016 – The Snowflake Elastic Data Warehouse:首次实现存算分离,本地缓存+S3
- databricks、TiDB serverless等:本地缓存+S3
- fluid+alluxio/juicefs+hdfs/S3:数据+缓存调度系统
- 各类Remote Shuffle Service(RSS)项目
- Starrocks 3.0、Doris 3.0:支持HDFS、S3
- Ozone:兼容HDFS、S3
- 网易:内部基于HDFS,18、19年开始探索;数帆大数据项目已经有较多项目落地(Hadoop+对象存储)
为了适配云上部署,S3对象存储是必选项,但是S3直接转成HDFS接口不够完美存在兼容性问题,性能也不能与本地数据PK,因此搭配元数据层和缓存加速层效果更佳。
趋势总结:
- 存储底座高内聚(基本均支持S3存储或HDFS存储),计算引擎和存储底座之间低耦合(无状态服务由K8S平台调度)。
- 基于对象存储服务的HDFS兼容层加速中间件发展迅猛(公有云产品为主、开源项目为辅)
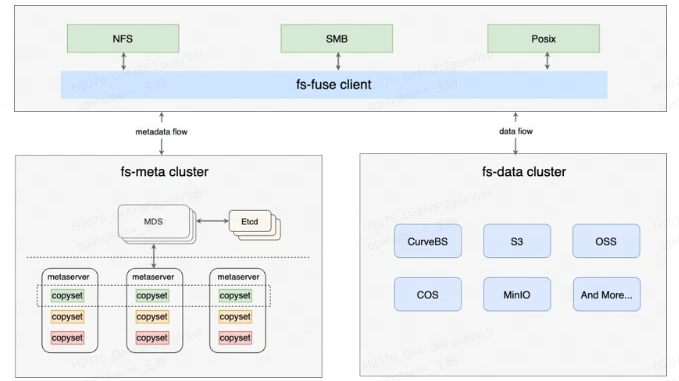
2. CurveFS+对象存储方案介绍
2.1 CurveFS介绍
CurveFS支持通用Posix以及HDFS等接口,故而可以支持如下业务:
- TensorFlow以及PyTorch等机器学习训练业务的数据集存储
- Spark,MapReduce等大数据计算业务的数据湖存储
- ElasticSearch,Clickouse等大数据查询分析业务的数据存储
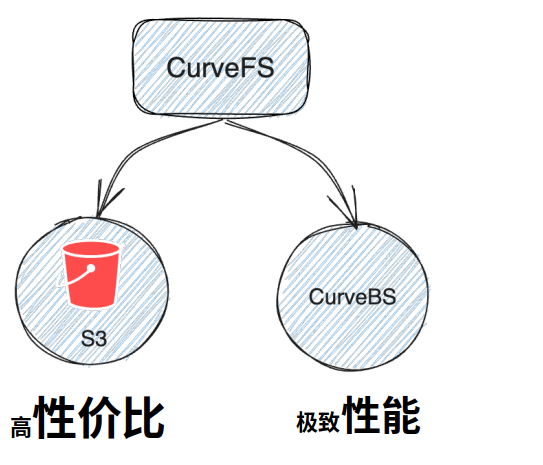
另外,CurveFS支持把数据存储在性价比高的对象存储上,同时还支持把数据存储在性能优先的Curve块存储上,用户可以按需选择。基本框架如下:
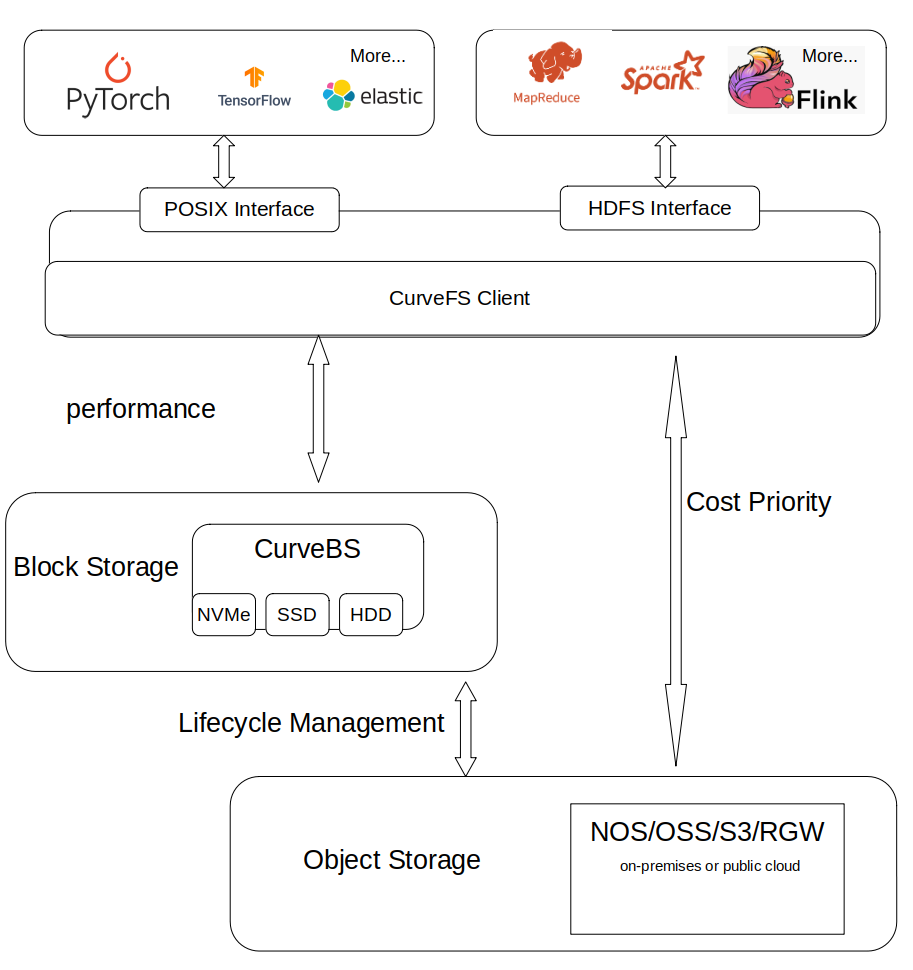
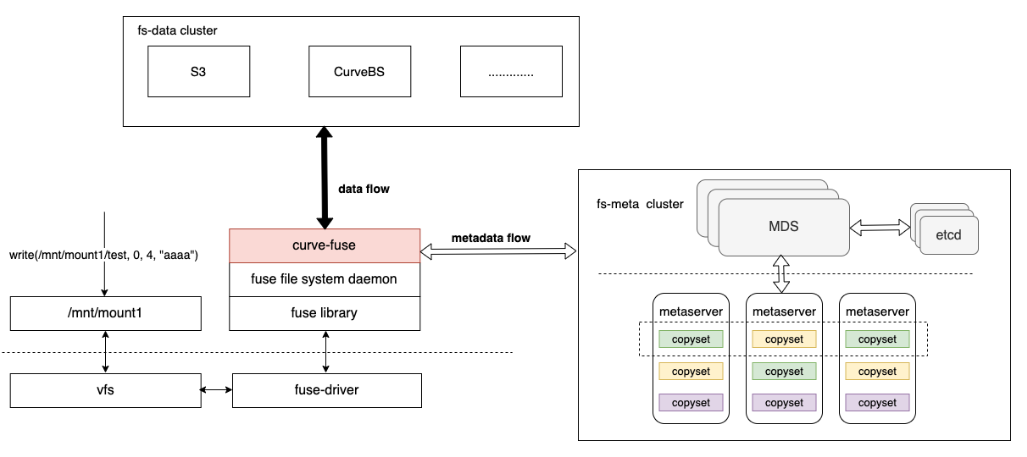
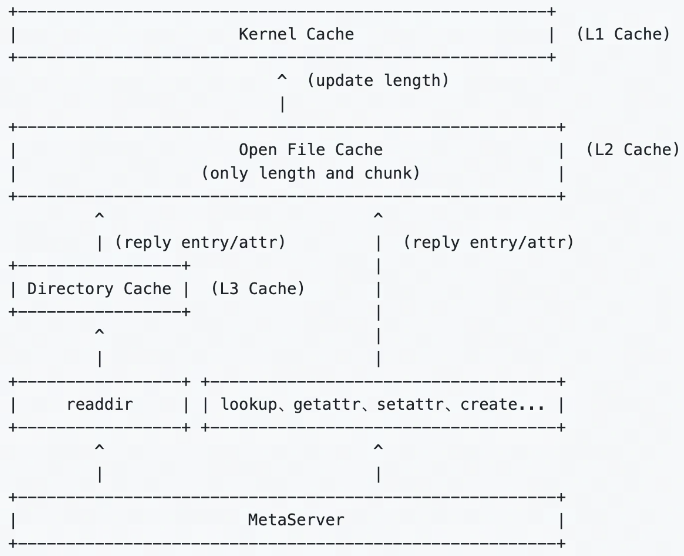
CurveFS架构如下,其由三个部分组成:
- 客户端 curve-fuse,和元数据集群交互处理文件元数据增删改查请求,和数据集群交互处理文件数据的增删改查请求。
- 元数据集群
-
- metaserver cluster:用于接收和处理元数据(inode 和 dentry)的增删改查请求。metaserver cluster 基于 raft实现3副本存储,具有高可靠、高可用、高可扩的特点:
- MDS: 用于管理集群拓扑结构,资源调度。
- 数据集群 data cluster,用于接收和处理文件数据的增删改查。data cluster 目前支持两存储类型:支持 S3 接口的对象存储以及 CurveBS(开发中)等存储后端。
接下来简单介绍下CurveFS的一些亮点:
- CurveFS支持S3和Curve块存储两种数据后端
- 文件系统的元数据独立存存储
解决元数据增长带来的扩展性和性能要求。文件系统的元数据存储在独立的集群中,随着文件数量的增加,元数据集群可以不断扩容,保证元数据可线性扩展。
- 文件系统数据和元数据都支持多级缓存
![]()
![]()
![]()
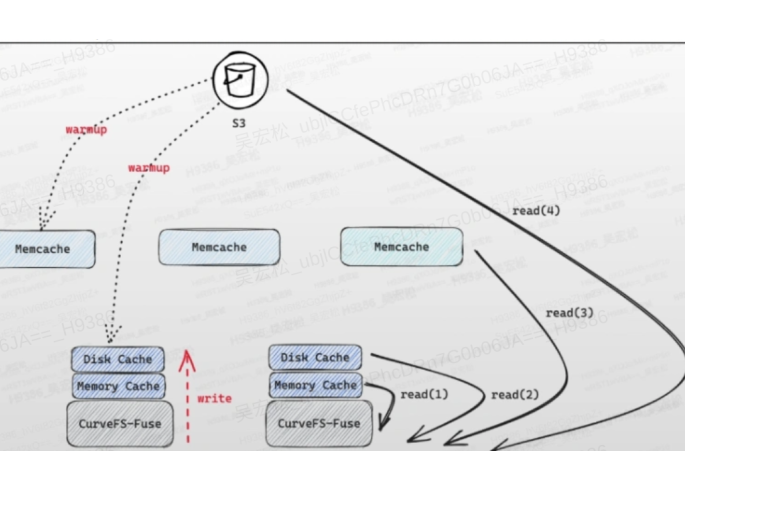
在工程实践过程中,由于S3、元数据集群都需要通过网络进行访问,每次读写都走网络对于业务性能是不可用的。在分析了业务特点后,Curve共享文件系统在保证多挂载点一致性的情况下进行了数据和元数据的性能优化,主要的思路是增加缓存。
- 数据支持多级缓存。包括内存缓存(用于加速当前节点上的读写速度),本地缓存(用于加速当前节点上的读写速度),全局缓存集群(用于加速当前节点以及多节点数据共享时的速度)。
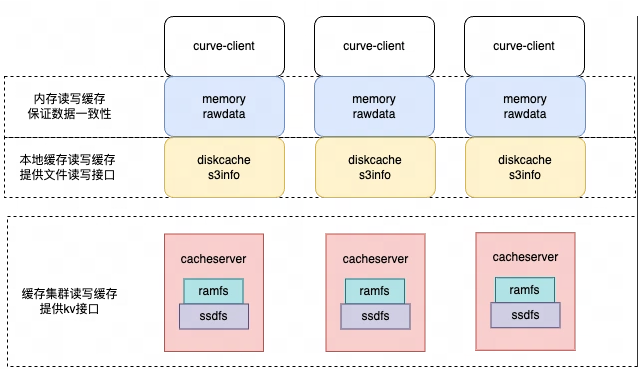
- 元数据支持kernel缓存、本地缓存。缓存何时加载或者失效,是元数据缓存的难点。我们没有采用分布式锁来做这样的保证,一方面是实现很复杂,另一方面从业务的分析不需要完全强一致。Curve共享文件系统为每种类型的缓存数据制定了一些规则,在满足业务一致性的前提下,提供了比较好的性能。
- 文件系统支持数据预读 & 预热
- 支持预读,即当数据访问的时候,可以把文件超过访问长度外的数据提前读到缓存中;
- 支持预热,用户可以提前把云端的数据按需拷贝到指定的任一缓存层,这样当后续需要访问时,可以提供更好的性能。
2.2 与 JuiceFS / Alluxio 对比
|
Alluxio
|
JuiceFS
|
CurveFS
|
|
|
定位
|
缓存系统
|
存储中间件
|
通用文件系统
|
|
主要优势
|
强大的聚合层,来为不同的存储系统(比如 HDFS、NFS)提供统一接入和缓存服务
|
不错的性能和易用性,元数据以插件形式接入,可完全上云,商业化很成熟
|
通用文件系统,拥有双存储引擎(S3 + CurveBS),性能优势明显,并且拥有很强的易用性和极低的维护成本,开源版本拥有全部特性
|
|
主要场景
|
作为后端存储的缓存层,加速访问
|
ES、大数据、AI 训练等
|
ES、大数据、AI 训练、热数据、高性能存储场景等
|
|
元数据引擎
|
无
|
开源版本无元数据引擎,需要使用第三方组件,Redis(扩展性差)、TiKV(性能差)
|
自研的 raft+rocksdb 元数据引擎,兼具性能和扩展性
|
|
存储后端
|
无(只做缓存)
|
S3 后端、ceph rados 后端
|
拥有双存储引擎:
1. 高性价比存储引擎(S3)
2. 高性能存储引擎(CurveBS)
可根据实际业务进行选择
|
|
使用方式对比
|
|||
|
完全兼容 POSIX
|
不支持
|
支持
|
支持
|
|
Hadoop 兼容
|
支持
|
支持
|
支持
|
|
S3 兼容
|
支持
|
支持
|
支持
|
|
Kubernetes CSI 驱动
|
支持
|
支持
|
支持
|
|
特性对比
|
|||
|
元数据缓存
|
单节点加载全部元数据
|
缓存在客户端
|
缓存在客户端(多类缓存,性能较好)
|
|
数据缓存
|
多级缓存:内存、HDD、SSD
|
多级缓存: 内存、SSD、分布式缓存(企业版)
|
多级缓存:内存、SSD、分布式缓存
|
|
元数据一致性
|
不一定
|
强一致
|
强一致
|
|
数据一致性
|
取决于用户配置(性能较差)
|
close-to-open(依赖缓存时长)
|
完善的 close-to-open
|
|
易用性、运维成本对比
|
|||
|
客户端
|
一键挂载
|
一键挂载
|
一键挂载
|
|
服务端
|
运维复杂
|
取决于所使用的组件(一般较复杂)
|
CurveAdm 一键部署,所有运维都一键完成
|
|
运维成本
|
有一定的学习、运维成本
|
需要引入新组件(如 Redis、TiKV)增加运维成本和组件学习门槛
|
极其简单上手,所有运维操作都傻瓜化
|
|
改造成本
|
开源版本存在一些性能问题和特性的缺失,往往需要用户进行一些改造优化才能较好在生产环境上运行,增加了用户的开发成本
|
由于JuiceFS 开源版本的限制,很多用户需要进行改造适配才能接入业务,改造工作量较大,周期长
|
开源版本特性完善,性能较好,用户往往只要接入即可使用
|
|
其他对比
|
|||
|
开发语言
|
Java
|
Go
|
C++
|
|
开源时间
|
2014
|
2021.1
|
2021.6(开发 FS)
|
CurveFS VS JuiceFS
优势:
- 开源包含所有特性:CurveFS对标的是JuiceFS商业版,其社区开源版本由于各种功能缺失导致用户需要进行改造优化才能较好在生产环境上运行,这无疑增加了用户的成本
- 性能优势明显:在AI训练、通用存储等场景下元数据等标测性能比 JuiceFS 开源版(TiKV)要好出不少,另外CurveFS还有 BS 后端,可作为高性能存储后端支持热数据存储,这是 JuiceFS 不具备的
- 运维成本和学习成本极低:CurveAdm 部署运维所有操作都是一键完成、傻瓜化操作,而 JuiceFS 需要额外引入第三方组件作为元数据存储引擎,第三方组件也有一定的学习门槛和维护成本
CurveFS VS Alluxio
优势:
- 完善的 POSIX 接口,可对接更多场景
- 拥有更强的数据和元数据一致性
- 易用性方面,特别是服务端运维,CurveFS 拥有更好的易用性
- 开源版本存在一些性能问题和特性的缺失,往往需要用户进行一些改造优化才能较好在生产环境上运行,增加了用户的开发成本
2.3 与公有云产品对比
JindoFS(适配阿里oss)/ RapidFS(适配百度bos)/ GooseFS(适配腾讯cos)/ EMRFS(适配aws s3)等公有云产品一般提供2种模式:block、cache,而CurveFS/JuiceFS只支持block模式。
cache模式只缓存对象存储的对象,不提供单独元数据服务,提供的是HDFS或对象存储接口,通常为只读缓存不支持数据写入,无法对元数据加速。优点是可以做到HDFS和S3接口的统一命名空间(同一个对象可以被两种接口协议访问)。
block模式,将数据切片存储到对象存储上,并提供元数据管理服务(相比S3的元数据性能有巨大提升),兼容HDFS接口并且接口性能优异,可以做到Hadoop体系计算引擎的无缝切换。不足在于无法做到HDFS和S3接口统一访问(业务文件数据会切片存储到对象存储里,对象存储中保存的不是完整的业务文件)。
JindoFS的block模式只提供云服务,JindoFSx(cache模式)可以私有部署,也兼容第三方云存储,但性能不如block模式。JindoFS可下载二进制和SDK,但源码不开源。
RapidFS不开源,且不提供下载,只随BMR产品提供。
GooseFS可下载SDK,不提供二进制下载,源码不开源。
AWS的EMRFS则是基于DynamoDB来增强S3的一致性视图,从而避免将S3接口直接转换为HDFS接口带来的不一致性问题。
公有云通常还提供EMR平台来方便用户,做到大数据平台的开箱即用,EMR通过上述fs加速组件来实现高性价比。
最大的区别有2点:
- 中立性:CurveFS/JuiceFS是中立开源的存储中间件,通常支持所有S3兼容的对象存储(包括公有云、私有化部署等),而公有云的相关加速中间件通常都是为自家的公有云对象存储和EMR服务提供支持,不开源且一般存在定制化和厂商锁定问题。
- 兼容性:CurveFS/JuicFS通常提供POSIX、HDFS、S3接口,并且可以扩展到NFS、SMB等协议,厂商加速中间件通常提供的是HDFS接口。
参考资料:
3. CurveFS+NOS方案落地挑战
3.1 CurveFS面临的挑战
基于CurveFS+HDFS SDK+对象存储(不限于NOS)替换HDFS集群主要有以下几个方面的挑战。
技术相关:
- 对Hadoop体系各类计算引擎的理解程度不够深入细致,对大数据存储的需求理解比较肤浅,目前是完成了HDFS兼容性接口适配
- 对热数据场景的支持还没有补齐(roadmap)
- 对rename等操作的性能优化还没有完成(doing)
- 多级缓存的架构改进(如写缓存的高可用及持久化、读缓存的命中率等)和性能优化(doing)
- 在公有云上的部署还没有进一步优化
竞品相关:
- JuiceFS/Alluxio占据先发优势,周边生态、落地场景和案例的丰富度,以及功能的完善度比CurveFS高出不少
- Alluxio主打大数据场景,对用户需求的理解程度更深入
- JuiceFS/Alluxio有商业版本,在付费用户群体中的认可度更高
- 人力投入与其他竞品有一定差距
3.2 NOS面临的挑战
- 性能成本均衡问题:NOS当前的软件架构和存储硬件选型都是面向成本优先规划设计的,大数据场景尤其是热数据场景下的性能需求比普通的对象存储要高很多,而公有云会综合考虑性能和成本,并且实测公有云性能比NOS优秀很多。在现有的架构和成本下,NOS性能提升空间不大。
- 收费模式:目前NOS的收费模式仍然是参照公有云模式,与大数据的收费模式可能有比较大的差异,存在是否能真正为业务降本的风险。
- 冷热分层:当前NOS的冷热分层主要是以NOS自身数据的上传时间为参照,大数据存储场景下的冷热分离更多的是业务层的指标为主(如数据生成时间、数据库表转冷等方面),存在上下层割裂问题,后续要考虑如何做到更好的协调适配。