20191219更新:
H版本合入async recovery功能,会引入多个bug,teuthology可以测试出来,主要是delete、snap/clone等操作和异步恢复功能的冲突(这部分依赖另外一个新版本合入的async delete功能)。因此不建议backport到H版本。可以参考xsky之前的异步恢复代码 https://github.com/ceph/ceph/pull/11918 (未merge但修改的版本跟H版本类似,不依赖async delete功能)。
最近在把ceph社区实现的异步恢复(async recovery)功能backport到H版本,目前已经合入完毕并且基本功能验证通过,这里是相关流程的分析文档。
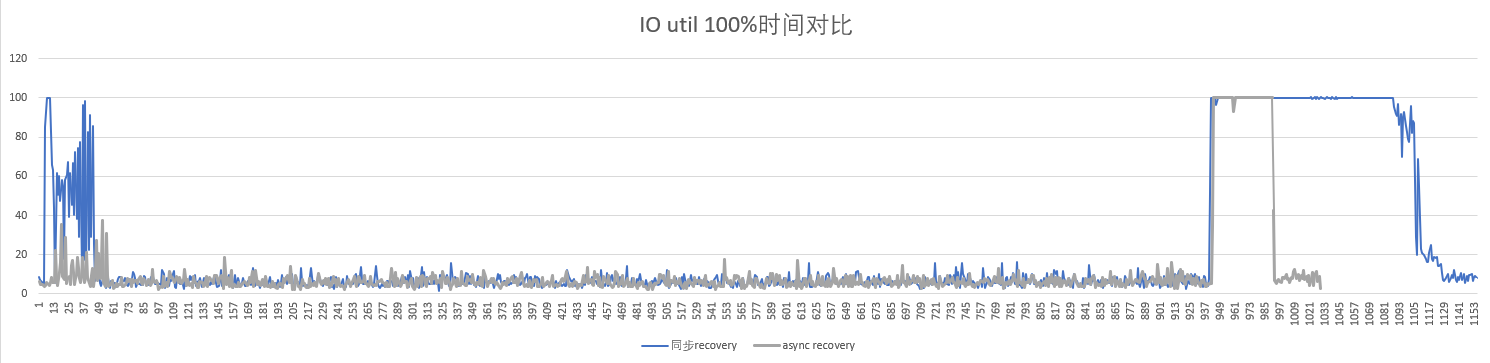
恢复期间对io影响比较
测试环境
- pubt2-ceph0.dg.163.org、pubt2-ceph1.dg.163.org、pubt2-ceph2.dg.163.org
- 3节点,各19个ssd osd,共57个osd
- Xeon(R) CPU E5-2660 v4 @ 2.00GHz,256G内存
- ssd有两个节点是三星960,一个是Intel 3520
测试场景
- 配置文件:完全相同
- 集群总能力:4k随机写iops为3.6W左右
- 背景压力:2W iops 4k随机写 (fio+librbd)
- 观察卷压力:100 iops 4k随机读写 (krbd挂载)
- iostat统计:每秒1个点,记录观察卷所在rbd设备的io util值
测试用例
- 停止一个副本域所有osd
- 等待15分钟
- 启动所有osd:启停命令:/etc/init.d/ceph stop/start osd
测试期间背景压力和观察卷压力持续进行。
影响对比
说明:X轴为时间,单位是s,间隔1s;Y轴是观察卷的io util值,每秒1个点。
整体实现思路
可参考官方说明文档:https://docs.ceph.com/docs/master/dev/osd_internals/async_recovery/
官方PR代码:https://github.com/ceph/ceph/pull/19811
总体思路是参考backfill的实现逻辑,backfill是在恢复过程中,生成副本是最新版本的可完全对外服务的acting列表,保证IO读写都完全不受影响,然后还会生成一个actingbackfill列表,其中包括了acting和需要backfill的osd,用来实现写入和恢复,backfill操作在后台执行,不会被客户端的写入操作触发。
异步恢复的操作也类似backfill,只是把actingbackfill列表改成了acting_recovery_backfill列表,IO写入时,主osd会用这个列表作为目标副本发送repop,但是对于需要recover的副本,则只发送log,不发送写入的数据(跟backfill一致)。peering结束后,根据peer_missing列表和missing_loc异步进行数据恢复,恢复也是根据pglog选择需要恢复的对象,不是整个pg无脑的全量恢复。之前同步恢复过程中,如果IO读写操作遇到副本(包括主)上该对象缺失,就要主动进行对象的恢复操作,然后把读写操作放入wait_for_unreadable_object或wait_for_degraded_object队列,等待对象恢复完毕之后重新enqueue,之后再进行正常的读写操作。
能否执行异步恢复也有一些附加条件:
1. 可用副本数大于min_size(注意是大于,不是大于等于)
2. 副本pglog与权威pglog差异条目数在100以内(可配置)
不满足条件则无法进行异步恢复,会执行同步恢复操作????
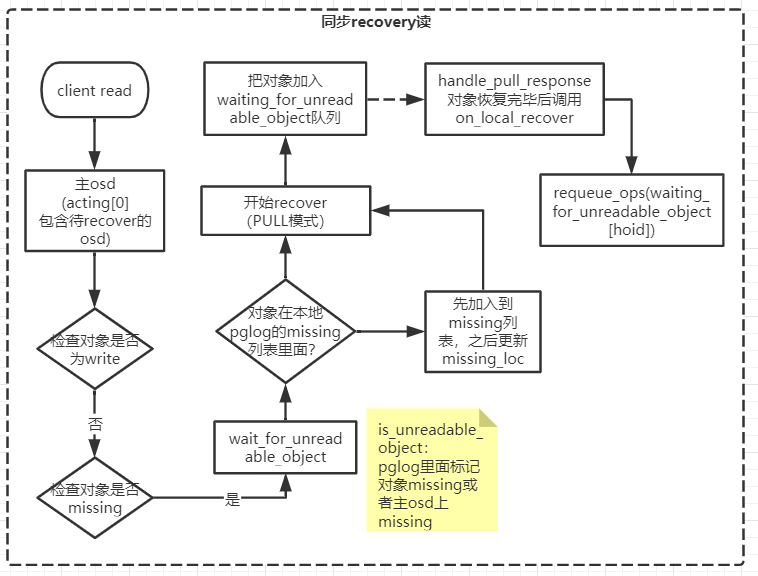
同步recover过程中IO流程示意
- 读
-
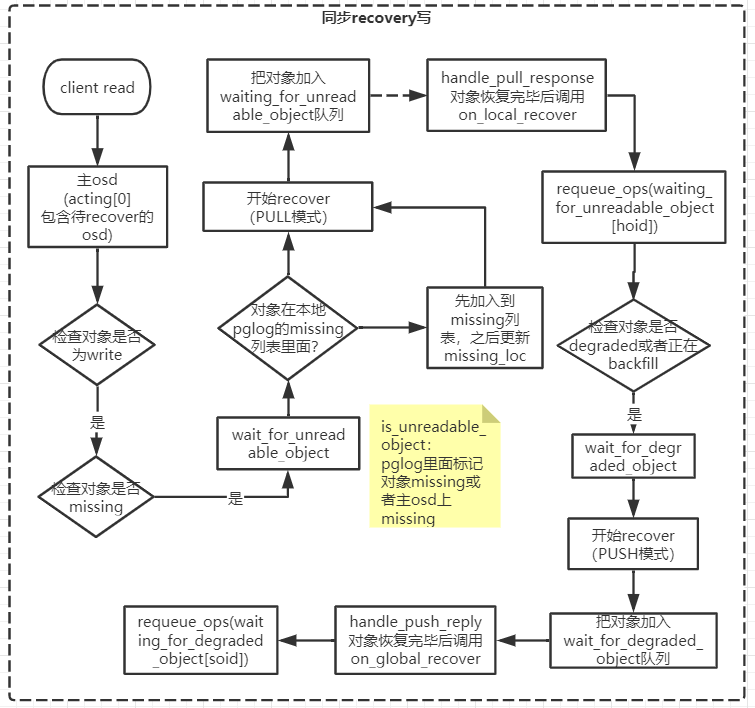
写
注:图里第一个框client read应该是client write
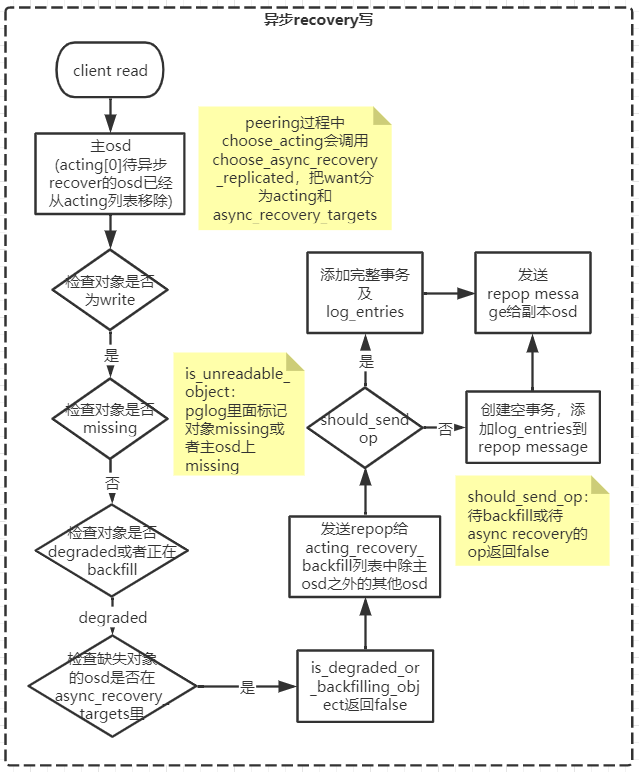
异步recover过程中IO流程示意(与backfill类似)
- 读
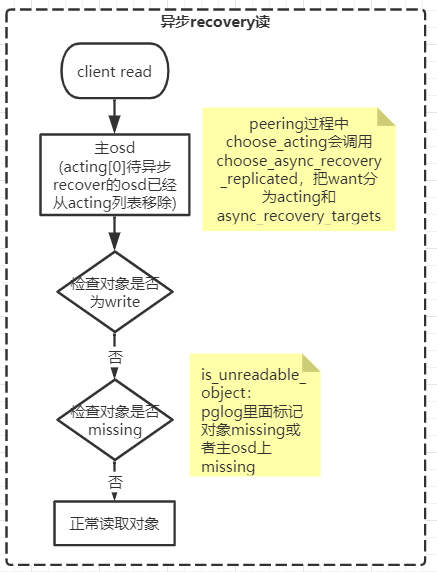
写
注:图里第一个框client read应该是client write
recover流程(含backfill)
关键数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
PG类: vector<int> up, acting, want_acting; // acting_recovery_backfill contains shards that are acting, // async recovery targets, or backfill targets. set<pg_shard_t> acting_recovery_backfill, actingset; set<pg_shard_t> backfill_targets, async_recovery_targets; map<pg_shard_t, pg_missing_t> peer_missing; MissingLoc missing_loc; PGLog类: pg_missing_t missing; |
主要流程
- Peering
GetLog
首先choose_acting:构造acting,acting_recovery_backfill,async_recovery_targets,并选出拥有权威日志auth_log_shard的osd,如果osd是自己,则发送GotLog事件。如果不是则发生pg_query_t::LOG消息给权威日志osd获取pglog,等权威osd返回log后,发送GotLog事件,之后调用proc_master_log处理接收到的权威日志。
proc_master_log:merge_log,保存peer_info、peer_missing、might_have_unfound(意思是这个osd对象比较全,可以从它这里获取unfound对象)。
处理完权威日志后,转到GetMissing状态。
GetMissing
遍历acting_recovery_backfill,根据peer_info和权威日志构建peer_missing(我理解这些都是日志差异太大,根据pg info就能断定副本osd需要backfill),如果这两个信息不足以确定peer_missing(我理解这里就是要根据pg日志来对比,找出需要recovery的osd),则需要发送pg_query_t::LOG或pg_query_t::FULLLOG给osd。
接收到副本osd返回的pg log之后,调用PG::proc_replica_log进行处理,并保存peer_info、peer_missing、might_have_unfound。
最后发送NeedUpThru或Activate事件,NeedUpThru是进入WaitUpThru状态,等待新的map更新up_thru值之后,再发送Activate事件进入Active状态。
- Active
调用pg->activate,根据peer_missing构造missing_loc(这部分没看懂),如果是主,要发送MOSDPGLog给副本osd,副本osd发送Activate事件后,从Stray状态进入ReplicaActive状态,处理Activate事件时同样调用pg->activate函数,在回调C_PG_ActivateCommitted里调用pg->_activate_committed,回复MOSDPGInfo消息给主osd,表示activate完毕。pg进入Activating状态,主osd等待所有副本activate完毕,调用pg->all_activated_and_committed,发送AllReplicasActivated事件,处理该事件时设置pg状态为PG_STATE_ACTIVE,重新入队等待peering结束的op(pg->requeue_ops(pg->waiting_for_peered)),最后调用pg->on_activate(),发送事件DoRecovery,pg进入WaitLocalRecoveryReserved状态。
- WaitLocalRecoveryReserved
事件:LocalRecoveryReserved
- WaitRemoteRecoveryReserved
给所有副本osd发送MRecoveryReserve::REQUEST消息,之后等待接收事件RemoteRecoveryReserved,
等待所有副本osd返回reserve成功消息后,发送事件:AllRemotesReserved,主osd进入Recovering状态,
- Recovering
|
1 2 3 4 |
pg->state_clear(PG_STATE_RECOVERY_WAIT); pg->state_set(PG_STATE_RECOVERING); pg->osd->queue_for_recovery(pg); |
切换到recovery线程,OSD::do_recovery->ReplicatedPG::start_recovery_ops恢复所有对象,每次恢复一个之后检查是否还在恢复,如果结束了,则继续检查是否需要backfill,如需要则发送事件RequestBackfill,调用PG::RecoveryState::Recovering::release_reservations(),释放reservations,replica osd进入RepNotRecovering状态,主osd跳转到WaitRemoteBackfillReserved状态。
否则直接发送AllReplicasRecovered,收到后调用PG::RecoveryState::Recovering::release_reservations(),释放reservations,跳转到Recovered状态。
- Recovered
再次choose_acting构造acting,acting_recovery_backfill,async_recovery_targets,此时acting,acting_recovery_backfill以及up,应该一致,async_recovery_targets会被清空。
之后发送事件:GoClean,转到Clean状态。
- WaitRemoteBackfillReserved
给所有副本osd发送MBackfillReserve::REQUEST消息,之后等待接收事件RemoteBackfillReserved,所有副本收到消息后进入RepWaitBackfillReserved状态,之后返回reserve成功消息后,主osd等待所有副本reserve完毕后,发送AllBackfillsReserved事件,主osd进入Backfilling状态.
- Backfilling
|
1 2 3 4 |
PG *pg = context< RecoveryMachine >().pg; pg->backfill_reserved = true; pg->osd->queue_for_recovery(pg); |
仍然切换到recovery线程,之后的流程与上面的Recovering类似,recovery和backfill都结束后进入Clean状态。
- Clean
修改pg状态为clean
recover过程调用的主要函数
- choose_acting
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard = find_best_info(all_info); // 查找权威日志osd,如果找不到就返回false,之后GetLog那边直接return,也就意味着peering流程无法正常执行(进入incomplete状态?),直到osdmap发生新的变化再进行重试 if ((up.size() && !all_info.find(up_primary)->second.is_incomplete() && all_info.find(up_primary)->second.last_update >= auth_log_shard->second.log_tail) && auth_log_shard->second.is_incomplete()) { // 如果权威osd为incomplete(没有backfill完?),就尝试再选一个(从complete的osd里面选) calc_replicated_acting // 计算期望的acting列表(want)、acting_recovery_backfill、backfill_targets,首先选出primary(首选up_primary,如果是incomplete或者日志不全,就选权威osd),之后依次遍历所有的up、acting、以及所有返回pg info的osd,根据pg info信息判断osd应该加入哪个列表(需要backfill的加入acting_recovery_backfill和backfill_targets,否则加入want_acting和acting_recovery_backfill) recoverable_and_ge_min_size // 根据want计算pg是否可以恢复,want_acting不为空即表示可以恢复(osd_allow_recovery_below_min_size默认值为true,所以非EC pool场景下,want的大小不需要大于等于min_size) choose_async_recovery_replicated // 挑出want_acting中可以执行异步恢复的osd(可以异步恢复的osd会从want中移除),保存到async_recovery_targets中。挑选条件是目标osd的last_update.version与权威osd的last_update.version差异大于100(osd_async_recovery_min_pg_log_entries配置项可以配置),差异越少的排的越靠前(set的自动排序特性),cost就是差异的值 queue_want_pg_temp // 如果上面的流程选出来的want与之前的acting不一致,则需要通知monitor生成pg_temp,注册临时的acting,并返回false 如果want等于acting,表示不需要变更acting列表,want_acting就可以清空了。这个时候就把calc_replicated_acting计算出来的几个列表赋给PG对象里对应的成员,保存起来以备后用。 |
- do_recovery
OSDService的recovery_wq是处理recovery的队列,并关联了线程池recovery_tp(线程数量由配置项osd_recovery_threads控制,默认值为1),pg->osd->queue_for_recovery(pg)就是把pg放到这个队列里了。
do_recovery就是recovery_tp线程池的处理函数(ThreadPool::worker->_void_process->RecoveryWQ::_process->do_recovery),ThreadPool::worker会首先dequeue一个pg,然后交给do_recovery去处理。
do_recovery先检查还有没有recovery的配额(并发数有没有到限制),然后再看是否需要sleep一定时间(进一步降低恢复占用的带宽),如果需要则注册timer event,回调里把pg重新放入recovery_wq,等待下一次被取出来处理。
如果不需要sleep等待,则调用pg->start_recovery_ops开始恢复,优先恢复主osd(recover_primary),之后恢复从osd(recover_replicas),recovery完成之后进行backfill(recover_backfill)。
recover_primary // 根据pg log找出需要恢复的对象及版本(根据log类型分为CLONE、LOST_REVERT场景,revert又分为本地有目标对象版本和没有两种情况,本地没有就要找到对象所在的osd,并加入到missing_loc,以便后面进行恢复)。最后调用recover_missing进行恢复,这里都是准备工作,只是把要push(恢复从)或者pull(恢复主)的op放到相应的队列中。真正执行recover操作的是run_recovery_op函数里的send_pushs(发送MOSDPGPush消息给目标osd)和send_pulls(发送MOSDPGPull给目标osd)。发送之后就是handle和reply流程了,这里就不细讲了。
recover_replicas跟recover_primary流程类似,也不细讲了。