问题背景
云平台为OpenStack+kvm,客户为某电商平台,业务开发接近尾声,准备进行验收,验收前需要进行压力测试,测试会模拟大量用户访问电商平台,也就是网络高并发连接和大带宽测试。简化版的业务架构为:
用户 –> Web页面 –> Nginx –> Tomcat –> DB。
其中Nginx使用keepalived实现高可用,Tomcat有多个节点,Nginx和Tomcat都部署在虚拟机中,Nginx所在虚拟机规格16核16G,Tomcat规格基本都是8核16G。
虚拟机业务网络接入的是万兆交换机(10G),neutron使用VLAN type driver+ovs mechanism driver模式,所有流量通过虚拟机virtio网卡和物理机ovs后进入物理网卡,然后通过物理交换机转发,没有L3 agent。
问题症状
使用wrk、ab等压测工具对nginx+静态文件、nginx+tomcat进行测试过程中,发现并发数和带宽上不去(555为nginx节点本地静态文件,大小为200K):
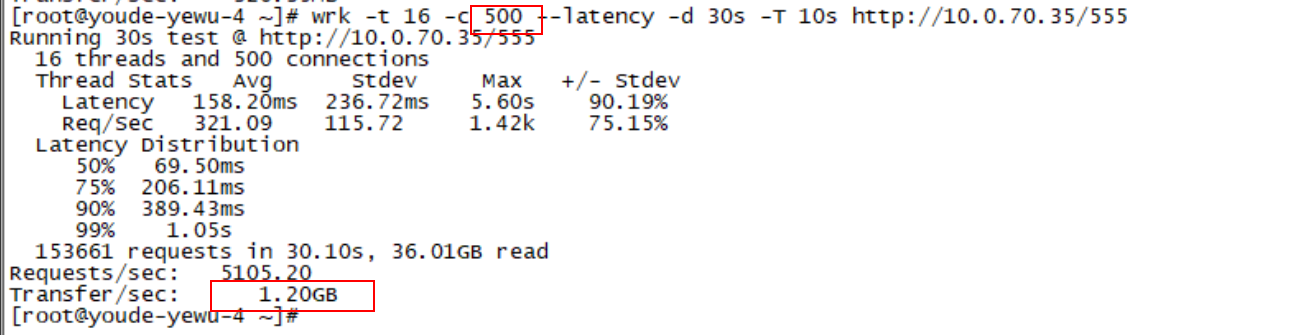
同Vlan低并发情况下,可以压满物理带宽,高并发下就下降严重:

定位过程
先在公司内部测试环境进行复现,公司内部测试环境CPU复用比例设置的很高(16倍),测试过程中发现使用iperf测两台物理机上的虚拟机之间的带宽都只有300MB,同一物理机上的两台虚拟机带宽有8GB(25Gbits)(因为只走本地ovs,不受物理网络带宽限制),又专门测试了两台物理机之间的带宽没有问题,可以跑满1GB多一点(其间还怀疑虚拟机业务出口物理网卡问题,专门测了这个网卡的带宽,都正常)。
继续查看虚拟机内部CPU使用情况,怀疑是软中断跑满单核导致带宽上不去,看完发现并没有跑满,cpu还比较空,但perf stat -e ‘kvm:*’ -a看虚拟机性能,发现cpu时间片都花费在vm_entry、vm_exit上了,也就是vm频繁的进入退出ring 0特权模式,众所周知这个切换操作是虚拟机性能的一大杀手,于是考虑绑定vcpu到物理cpu,首先绑定虚拟机cpu到物理cpu,然后再把其他进程(包含其它虚拟机的qemu进程、vhost进程)绑定到其他物理cpu上(taskset -pc命令)。之后再次iperf测试,带宽稳定在1GB多一点,跑满物理网络带宽,问题解决。
然后为了排除cpu复用太高导致的性能问题,关闭了不需要的虚拟机,只保留测试机(wrk客户机和nginx服务机),继续压力测试,wrk压测nginx+静态文件,发现带宽还是上不去,只是略有提升。
查看物理机上qemu进程和vhost进程cpu都不算高,至少没100%,虚拟机的整体cpu也不高,说明cpu性能没到瓶颈,这时就有点迷惑了,继续在虚拟机里top查看单核cpu利用率,发现有一个核的si占用率超高,接近100%,于是继续看虚拟机网卡中断处理绑定范围(cat /proc/interrupts),确认是绑定在单核上,网卡只有一个队列,于是继续尝试打开虚拟机网卡多队列,关掉nova-compute服务,关掉虚拟机,virsh edit 虚拟机xml配置:
|
1 2 3 4 5 |
<interface type='network'> <source network='default'/> <model type='virtio'/> <driver name='vhost' queues='N'/> ### 加这行开启虚拟机网卡多队列,N不要超过虚拟机核数 </interface> |
设置队列数为虚拟机cpu数量的一半(nginx节点设置8个队列),virsh start启动虚拟机,centos7的操作系统虚拟机内部多队列自动生效,不需要执行ethtool命令(ethtool -L <NIC> combined #num_of_queues),低版本的内核需要(应该是小于3.8的)。
继续测试,发现带宽可以跑满了,并且并发量大幅提升,问题解决。
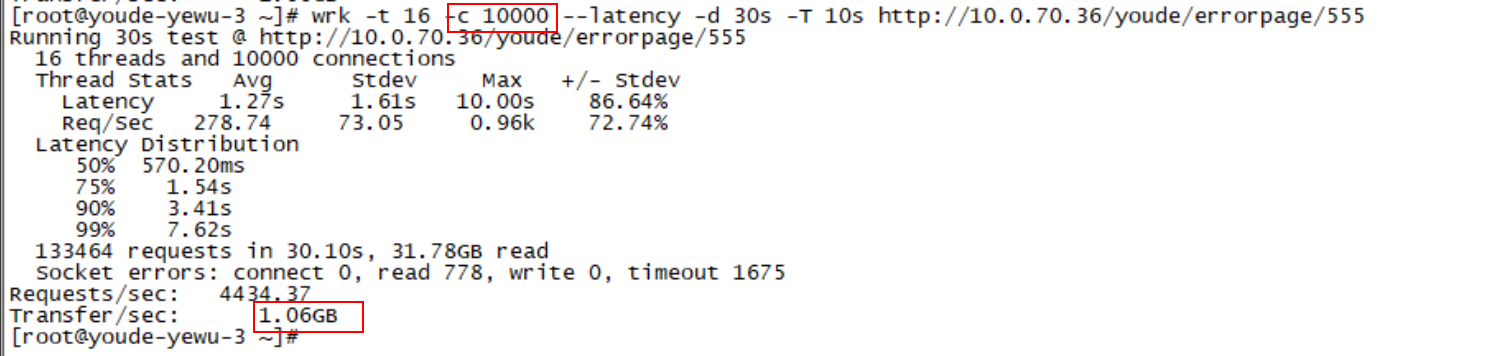
实际并发数量比这个截图里面的更高,仍然能跑满物理带宽。
改进手段
虚拟机网卡多队列是提升虚拟机网络性能的一个有效手段,于是根据libvirt xml中的queues关键字在master版本的nova代码库的nova/virt/libvirt/config.py文件里搜了下(这个文件负责生产libvirt所需的虚拟机xml配置文件),果然搜到了,于是继续在我们使用的Mitaka版本中搜索,也是有的,看来nova已经支持网卡多队列功能。这样后续客户需要高性能虚拟网络的时候,就可以在镜像上设置这个属性,直接默认开启虚拟机网卡多队列功能。
nova是根据镜像的property中的hw_vif_multiqueue_enabled=true|false (default false)字段来实现开启关闭多队列功能的。需要注意的是,镜像增加该属性不会影响使用该镜像已创建的云主机,只有当使用该镜像rebuild已有云主机时候才会生效,或者新建云主机也会生效。其他镜像属性的修改也是类似。原因是创建或者rebuild过程中才会把镜像属性同步保存或更新到nova库的instance_system_metadata表中,其他操作如重启云主机等只会从这个表里面查询用来生成虚拟机xml配置文件,而不会查询glance。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
nova.virt.libvirt.vif.LibvirtGenericVIFDriver#get_base_config: class LibvirtGenericVIFDriver(object): """Generic VIF driver for libvirt networking.""" def _normalize_vif_type(self, vif_type): return vif_type.replace('2.1q', '2q') def get_vif_devname(self, vif): if 'devname' in vif: return vif['devname'] return ("nic" + vif['id'])[:network_model.NIC_NAME_LEN] def get_vif_devname_with_prefix(self, vif, prefix): devname = self.get_vif_devname(vif) return prefix + devname[3:] def get_base_config(self, instance, vif, image_meta, inst_type, virt_type): conf = vconfig.LibvirtConfigGuestInterface() # Default to letting libvirt / the hypervisor choose the model model = None driver = None vhost_queues = None # If the user has specified a 'vif_model' against the # image then honour that model if image_meta: model = osinfo.HardwareProperties(image_meta).network_model # Else if the virt type is KVM/QEMU, use virtio according # to the global config parameter if (model is None and virt_type in ('kvm', 'qemu') and CONF.libvirt.use_virtio_for_bridges): model = network_model.VIF_MODEL_VIRTIO # Workaround libvirt bug, where it mistakenly # enables vhost mode, even for non-KVM guests if (model == network_model.VIF_MODEL_VIRTIO and virt_type == "qemu"): driver = "qemu" if not is_vif_model_valid_for_virt(virt_type, model): raise exception.UnsupportedHardware(model=model, virt=virt_type) if (virt_type == 'kvm' and model == network_model.VIF_MODEL_VIRTIO): vhost_drv, vhost_queues = self._get_virtio_mq_settings(image_meta, inst_type) ### 这里 driver = vhost_drv or driver designer.set_vif_guest_frontend_config( conf, vif['address'], model, driver, vhost_queues) return conf def _get_virtio_mq_settings(self, image_meta, flavor): ### 这个方法 """A methods to set the number of virtio queues, if it has been requested in extra specs. """ driver = None vhost_queues = None if not isinstance(image_meta, objects.ImageMeta): image_meta = objects.ImageMeta.from_dict(image_meta) img_props = image_meta.properties if img_props.get('hw_vif_multiqueue_enabled'): ### 这个镜像属性 driver = 'vhost' vhost_queues = flavor.vcpus ### 默认网卡队列数跟虚拟机vcpu数量一致 return (driver, vhost_queues) |
当前实现是只能开启或者关闭,不能设置队列数量,不过应该已经足够了。
关于队列数量还有个bug,不同版本的计算节点操作系统内核支持的tap设备最大队列数量不一样(2.X的1个,3.X的8个,4.X的256个,但我用的3.10版本内核,没有遇到这个问题,16个队列都正常创建了),导致开启网卡多队列后Linux 3.X版本计算节点不能创建多于8个vcpu的云主机:https://bugs.launchpad.net/nova/+bug/1570631
nova网卡多队列实现的BP在这里,但是具体实现和BP有差异:https://specs.openstack.org/openstack/nova-specs/specs/liberty/implemented/libvirt-virtiomq.html