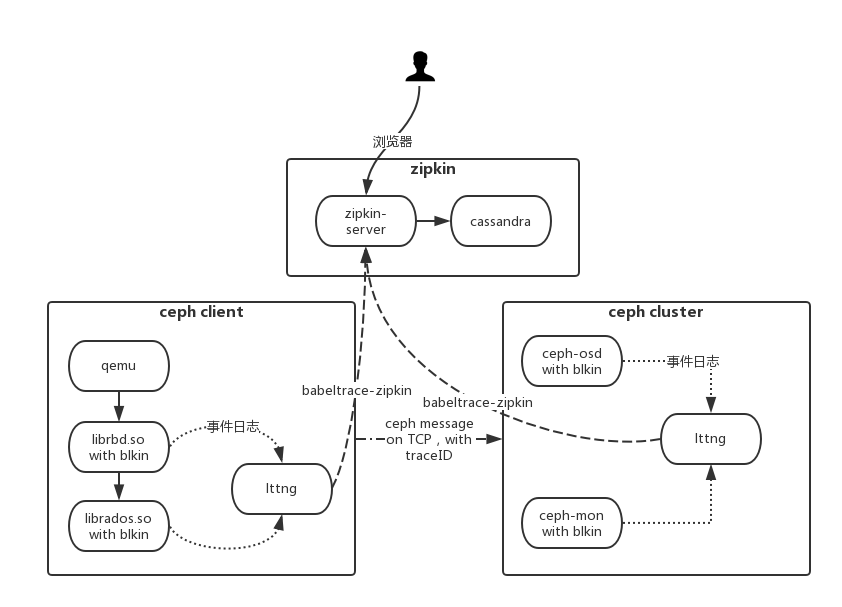
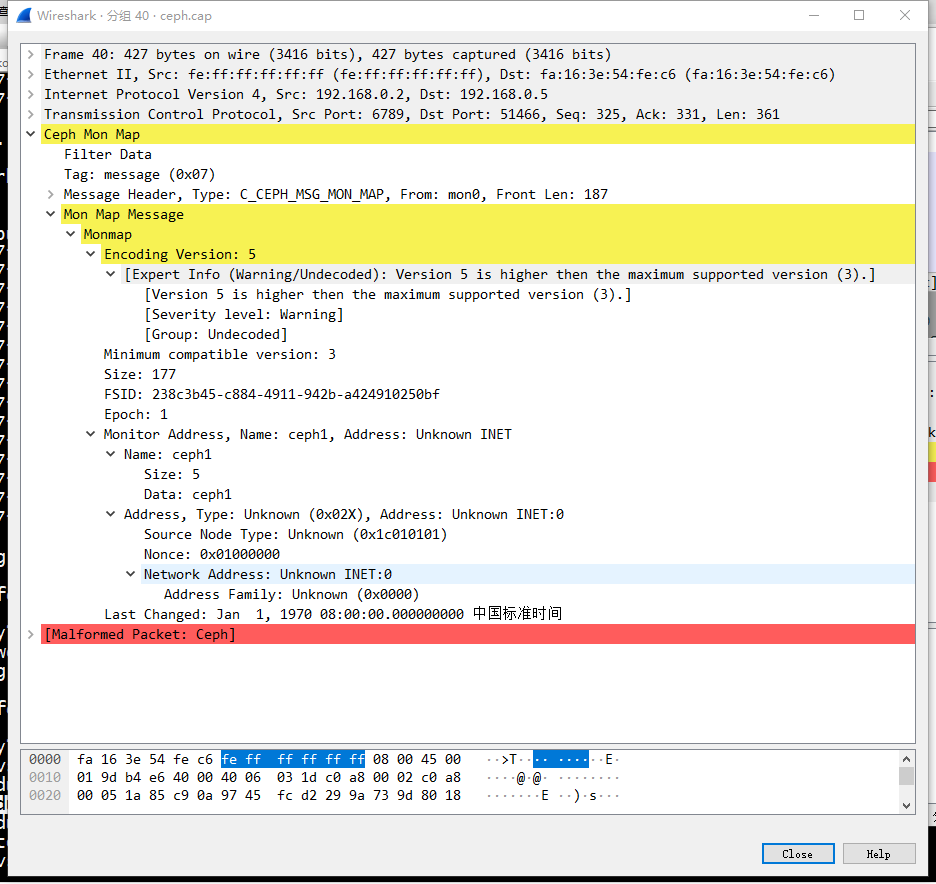
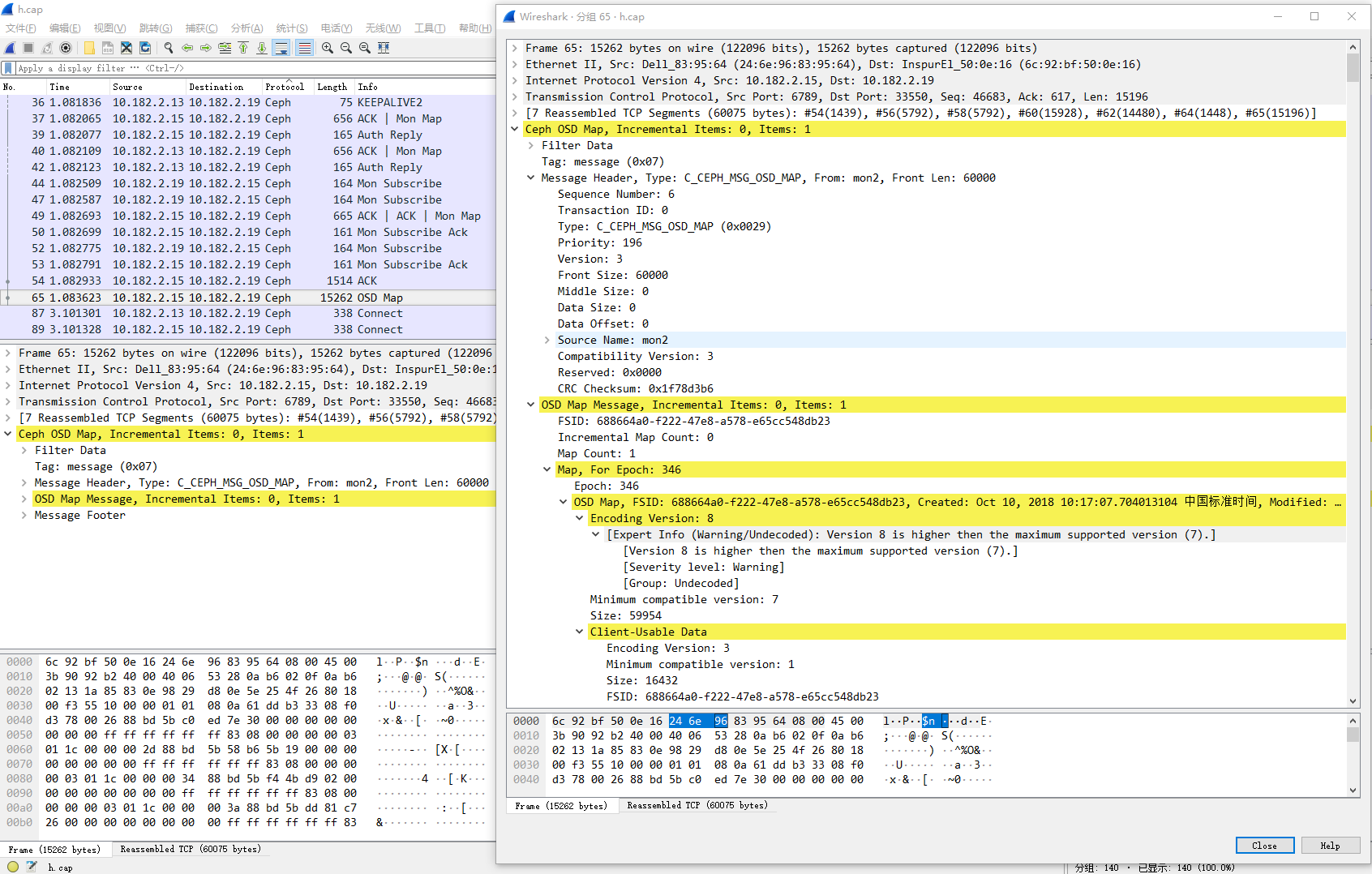
概念介绍
Image
对应于LVM的Logical Volume,是能被attach/detach到VM的载体。在RBD中,Image的数据有多个Object组成。
Snapshot
Image的某一个特定时刻的状态,只能读不能写但是可以将Image回滚到某一个Snapshot状态。Snapshot必定属于某一个Image。
Clone
为Image的某一个Snapshot的状态复制变成一个Image。如ImageA有一个Snapshot-1,clone是根据ImageA的Snapshot-1克隆得到ImageB。ImageB此时的状态与Snapshot-1完全一致,区别在于ImageB此时可写,并且拥有Image的相应能力。
元数据
striping
- order:22,The size of objects we stripe over is a power of two, specifically 2^[order] bytes. The default is 22, or 4 MB.
- stripe_unit:4M,Each [stripe_unit] contiguous bytes are stored adjacently in the same object, before we move on to the next object.
- stripe_count:1,After we write [stripe_unit] bytes to [stripe_count] objects, we loop back to the initial object and write another stripe, until the object reaches its maximum size (as specified by [order]. At that point, we move on to the next [stripe_count] objects.
root@ceph1 ~ $ rados -p rbd ls
- rbd_header.1bdfd6b8b4567:保存image元数据(rbd info的信息)
- rbd_directory:保存所有image的id和名称列表
- rbd_info:“overwrite validated”,EC pool使用?
- rbd_id.vol1:保存image的id
- rbd_data.233546b8b4567.0000000000000025:保存image数据的对象,按需分配,233546b8b4567为image id,0000000000000025为stripe_unit id,从0开始增长
参考:
- http://hustcat.github.io/rbd-image-internal-in-ceph/
- http://tracker.ceph.com/issues/19081
回调
回调类
3个特征:
- 类名称以C_开头
- 实现了finish成员函数
- Context子类
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
struct C_AioComplete : public Context { AioCompletionImpl *c; explicit C_AioComplete(AioCompletionImpl *cc) : c(cc) { c->_get(); } void finish(int r) override { rados_callback_t cb_complete = c->callback_complete; void *cb_complete_arg = c->callback_complete_arg; if (cb_complete) cb_complete(c, cb_complete_arg); rados_callback_t cb_safe = c->callback_safe; void *cb_safe_arg = c->callback_safe_arg; if (cb_safe) cb_safe(c, cb_safe_arg); c->lock.Lock(); c->callback_complete = NULL; c->callback_safe = NULL; c->cond.Signal(); c->put_unlock(); } }; |
还有一种回调适配器类,通过模板类实现通用的回调类,可以把各种类转换成回调类:
|
|
template <typename T, void (T::*MF)(int)> class C_CallbackAdapter : public Context { T *obj; public: C_CallbackAdapter(T *obj) : obj(obj) { } protected: void finish(int r) override { (obj->*MF)(r); } }; |
之后通过回调生成函数create_xxx_callback(create_context_callback、create_async_context_callback)函数创建出回调类,供后续注册使用。
回调适配函数
通过模板函数将任意函数转换为回调函数。
为啥不直接用原始函数作为回调函数注册进去?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
template <typename T> void rados_callback(rados_completion_t c, void *arg) { reinterpret_cast<T*>(arg)->complete(rados_aio_get_return_value(c)); } template <typename T, void(T::*MF)(int)> void rados_callback(rados_completion_t c, void *arg) { T *obj = reinterpret_cast<T*>(arg); int r = rados_aio_get_return_value(c); (obj->*MF)(r); } template <typename T, Context*(T::*MF)(int*), bool destroy> void rados_state_callback(rados_completion_t c, void *arg) { T *obj = reinterpret_cast<T*>(arg); int r = rados_aio_get_return_value(c); Context *on_finish = (obj->*MF)(&r); if (on_finish != nullptr) { on_finish->complete(r); if (destroy) { delete obj; } } } |
回调生成函数
create_context_callback、create_async_context_callback上面已经介绍过,这里主要介绍create_rados_callback:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
template <typename T> librados::AioCompletion *create_rados_callback(T *obj) { return librados::Rados::aio_create_completion( obj, &detail::rados_callback<T>, nullptr); } template <typename T, void(T::*MF)(int)> // MF是真正的回调函数 librados::AioCompletion *create_rados_callback(T *obj) { return librados::Rados::aio_create_completion( obj, &detail::rados_callback<T, MF>, nullptr); } /* 这2个create_rados_callback用来创建间接回调rados_callback/rados_state_callback,MF是真正的回调 */ // 重载函数,要注意区分模板中的第二个参数(也即回调函数)的类型,以便确定调用的是这个还是上面的那个 // 如Context *handle_v2_get_mutable_metadata(int *result)调用这个, // 而void RewatchRequest::handle_unwatch(int r)则调用的是上面那个 template <typename T, Context*(T::*MF)(int*), bool destroy=true> // MF是真正的回调 librados::AioCompletion *create_rados_callback(T *obj) { return librados::Rados::aio_create_completion( obj, &detail::rados_state_callback<T, MF, destroy>, nullptr); } |
这个函数只做了一件事,就是创建一个rados操作需要的AioCompletion回调类(与上面),而回调类里的回调函数,则是用上面提到的回调适配函数转换的,把普通函数转换为回调函数。
回调注册
有如下几种方式:
- 直接注册:通常在最外层,对外接口中使用,一般需要在librbd内部二次封装
- 通过回调生成函数:librbd内部使用较多
- 通过回调适配函数:librbd内部使用较多
回调与Finisher线程的关系
回调类为啥必须继承Context?
这是因为所有的回调都由finisher线程处理(执行体为Finisher::finisher_thread_entry),而该线程会调用回调类的complete成员函数,Context类实现了这个函数,专门用来作为回调公共类。只是为了方便、统一,并不是必须的,你可以可以自己实现回调类的complete成员函数,而不继承Context。
参考下面finisher thread的关联队列finisher_queue、finisher_queue_rval的入队过程,可了解回调入队过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
void *Finisher::finisher_thread_entry() { ...... while (!finisher_stop) { while (!finisher_queue.empty()) { vector<Context*> ls; list<pair<Context*,int> > ls_rval; ls.swap(finisher_queue); ls_rval.swap(finisher_queue_rval); ...... // Now actually process the contexts. for (vector<Context*>::iterator p = ls.begin(); p != ls.end(); ++p) { if (*p) { (*p)->complete(0); // 调用回调类的complete成员函数 } else { // When an item is NULL in the finisher_queue, it means // we should instead process an item from finisher_queue_rval, // which has a parameter for complete() other than zero. // This preserves the order while saving some storage. assert(!ls_rval.empty()); Context *c = ls_rval.front().first; c->complete(ls_rval.front().second); // 调用回调类的complete成员函数 ls_rval.pop_front(); } ...... } |
回调流
在rbd image打开过程中,需要执行很多流程来获取image的各种元数据信息(流程描述参考OpenRequest的注释,主要包括V2_DETECT_HEADER、V2_GET_ID|NAME、V2_GET_IMMUTABLE_METADATA、V2_GET_STRIPE_UNIT_COUNT、V2_GET_CREATE_TIMESTAMP、V2_GET_DATA_POOL等),当然你也可以在一个方法中一次获取全部元数据,但会导致单次操作耗时太长,各元数据的获取函数耦合也比较重,这是我个人的猜测,也可能其他方面的考虑,目前还没有理解。
librbd中用回调流的方式,来依次调用各个元数据请求函数和响应处理函数,入口是rbd_open,第一个执行的元数据请求函数是send_v2_detect_header(发送检查是否为v2版本image header的请求),qemu的具体调用栈如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
Thread 1 "qemu-system-x86" hit Breakpoint 4, librbd::image::OpenRequest<librbd::ImageCtx>::send_v2_detect_header (this=this@entry=0x5555568d1520) at /mnt/ceph/src/librbd/image/OpenRequest.cc:84 84 void OpenRequest<I>::send_v2_detect_header() { (gdb) bt #0 librbd::image::OpenRequest<librbd::ImageCtx>::send_v2_detect_header (this=this@entry=0x5555568d1520) at /mnt/ceph/src/librbd/image/OpenRequest.cc:84 #1 0x00007fffdf0f1895 in librbd::image::OpenRequest<librbd::ImageCtx>::send (this=this@entry=0x5555568d1520) at /mnt/ceph/src/librbd/image/OpenRequest.cc:42 #2 0x00007fffdf058030 in librbd::ImageState<librbd::ImageCtx>::send_open_unlock (this=0x5555568cf750) at /mnt/ceph/src/librbd/ImageState.cc:592 #3 0x00007fffdf05b9b9 in librbd::ImageState<librbd::ImageCtx>::execute_next_action_unlock (this=this@entry=0x5555568cf750) at /mnt/ceph/src/librbd/ImageState.cc:521 #4 0x00007fffdf05ca39 in librbd::ImageState<librbd::ImageCtx>::execute_action_unlock (this=this@entry=0x5555568cf750, action=..., on_finish=on_finish@entry=0x7fffffffd1a0) at /mnt/ceph/src/librbd/ImageState.cc:546 #5 0x00007fffdf05cbdd in librbd::ImageState<librbd::ImageCtx>::open (this=this@entry=0x5555568cf750, skip_open_parent=skip_open_parent@entry=false, on_finish=on_finish@entry=0x7fffffffd1a0) at /mnt/ceph/src/librbd/ImageState.cc:271 #6 0x00007fffdf05ccfd in librbd::ImageState<librbd::ImageCtx>::open (this=0x5555568cf750, skip_open_parent=skip_open_parent@entry=false) at /mnt/ceph/src/librbd/ImageState.cc:250 #7 0x00007fffdf042116 in rbd_open (p=<optimized out>, name=name@entry=0x555556749fd8 "vol1", image=image@entry=0x555556749fd0, snap_name=<optimized out>) at /mnt/ceph/src/librbd/librbd.cc:2508 #8 0x00007fffdf534dd3 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd68) at ./block/rbd.c:565 #9 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd58, options=0x555556757190, file=0x0, bs=0x555556701880) at ./block.c:1104 #10 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556757190, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffdeb8) at ./block.c:1833 #11 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffdeb8) at ./block.c:1588 #12 0x0000555555b0e24c in bdrv_open_inherit (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=0x5555566ff670, options@entry=0x5555566f90b0, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe190) at ./block.c:1794 #13 0x0000555555b0f7b1 in bdrv_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block.c:1924 #14 0x0000555555b4890b in blk_new_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block/block-backend.c:160 #15 0x000055555580c90f in blockdev_init (file=file@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=bs_opts@entry=0x5555566f90b0, errp=errp@entry=0x7fffffffe190) at ./blockdev.c:582 #16 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #17 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #18 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #19 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
template <typename I> // 打开rbd镜像入口, void OpenRequest<I>::send_v2_detect_header() { if (m_image_ctx->id.empty()) { CephContext *cct = m_image_ctx->cct; ldout(cct, 10) << this << " " << __func__ << dendl; librados::ObjectReadOperation op; op.stat(NULL, NULL, NULL); using klass = OpenRequest<I>; librados::AioCompletion *comp = create_rados_callback<klass, &klass::handle_v2_detect_header>(this); // 创建回调类,回调函数是handle_v2_detect_header,收到响应时被调用 m_out_bl.clear(); m_image_ctx->md_ctx.aio_operate(util::id_obj_name(m_image_ctx->name), comp, &op, &m_out_bl); // 发送请求给ceph服务端 comp->release(); } else { send_v2_get_name(); } } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
template <typename I> Context *OpenRequest<I>::handle_v2_detect_header(int *result) { CephContext *cct = m_image_ctx->cct; ldout(cct, 10) << __func__ << ": r=" << *result << dendl; if (*result == -ENOENT) { send_v1_detect_header(); } else if (*result < 0) { lderr(cct) << "failed to stat v2 image header: " << cpp_strerror(*result) << dendl; send_close_image(*result); } else { m_image_ctx->old_format = false; send_v2_get_id(); // 直接调用下一个元数据请求函数 } return nullptr; } |
通过直接调用+设置回调再调用形成回调流,最后进入send_v2_apply_metadata,它会注册最后一个回调handle_v2_apply_metadata。
控制流
- 请求:由RadosClient、MgrClient及其成员函数处理,一般是普通dispatch流程,最终都交给AsyncMessenger发送出去
- 响应:AsyncMessenger相关方法
数据流
由Objecter类及其成员函数处理,一般是fast dispatch流程,最终都交给AsyncMessenger发送出去
数据结构及IO数据流转
控制流
Context
所有回调的基类
CephContext
所有操作都需要用到,存储了各种全局信息,每个client一个(librbd算一个client)
ImageCtx
存储image的全局信息,每个image一个
ContextWQ
IO控制流的工作队列类(包含队列和处理方法),op_work_queue对象
librados::IoCtx、IoCtxImpl
与rados交互所需的全局信息,一个对外一个内部使用,一个pool一个
Finisher、Finisher::FinisherThread
回调执行类,专门管理回调队列并在线程中调用各种回调
数据流
AsyncConnection
与ceph服务端连接信息,由AsyncMessenger维护,所有请求都由其发送,AsyncConnection::process
librbdioAioCompletion
用户层发起的异步IO完成后的librbd内部回调,主要用来记录perf counter信息,以及IO请求发起用户传入的外部回调函数
librbd::ThreadPoolSingleton
封装ThreadPool,实现tp_librbd单例线程
ThreadPool
所有线程池的基类
ThreadPool::PointerWQ
IO数据流、控制流工作队列的共同基类
librbdioImageRequestWQ
IO数据流的工作队列类(包含队列和处理方法),io_work_queue对象
librbdioImageRequest
IO请求的基类,image级别,对应用户IO请求
librbdioAbstractImageWriteRequest
IO写请求的抽象类,继承自ImageRequest
librbdioImageWriteRequest
IO写请求类,继承自AbstractImageWriteRequest
Thread
所有线程、线程池的基类,子类通过start函数启动各自的entry函数进入thread执行体完成实际工作。
Objecter
上层单次IO操作对象,对应用户IO请求
Objecter::Op
上层IO操作对象可能包含多个object,需要拆分成多个Op,对应到rados对象
Dispatcher
与服务端交互的分发方法基类,MgrClient、Objecter、RadosClient都继承自Dispatcher类
Striper
IO封装、解封,读写操作过程中从IO到object互相转换
librbdioObjectRequest、librbdioObjectReadRequest、librbdioAbstractObjectWriteRequest、librbdioObjectWriteRequest
用户IO请求拆分后的object级别的IO请求
线程池与队列
tp_librbd(librbd::thread_pool)
tp_thread启动(处理io_work_queue及op_work_queue):ThreadPoolstart–ThreadPoolstart_threads–new WorkThread(this)–Threadcreate–Threadtry_create–pthread_create–Thread::_entry_func–Threadentry_wrapper–ThreadPoolWorkThread::entry–线程启动完毕,worker开始工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
(gdb) bt #0 0x00007fffdf019af0 in ThreadPool::start()@plt () from /usr/local/lib/librbd.so.1 //----- 后续流程见上面注释 #1 0x00007fffdf04b475 in librbd::(anonymous namespace)::ThreadPoolSingleton::ThreadPoolSingleton (cct=0x555556752f30, this=0x5555568cdf50) at /mnt/ceph/src/librbd/ImageCtx.cc:66 #2 CephContext::lookup_or_create_singleton_object<librbd::(anonymous namespace)::ThreadPoolSingleton> (name="librbd::thread_pool", p=<synthetic pointer>: <optimized out>, this=0x555556752f30) at /mnt/ceph/src/common/ceph_context.h:130 #3 librbd::ImageCtx::get_thread_pool_instance (cct=0x555556752f30, thread_pool=thread_pool@entry=0x7fffffffcfc8, op_work_queue=op_work_queue@entry=0x5555568cdc60) at /mnt/ceph/src/librbd/ImageCtx.cc:1159 #4 0x00007fffdf04c0f9 in librbd::ImageCtx::ImageCtx (this=0x5555568cd300, image_name=..., image_id=..., snap=0x0, p=..., ro=<optimized out>) at /mnt/ceph/src/librbd/ImageCtx.cc:213 #5 0x00007fffdf0420d7 in rbd_open (p=<optimized out>, name=name@entry=0x555556749fd8 "vol1", image=image@entry=0x555556749fd0, snap_name=0x0) at /mnt/ceph/src/librbd/librbd.cc:2505 #6 0x00007fffdf534dd3 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd78) at ./block/rbd.c:565 #7 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd68, options=0x555556757190, file=0x0, bs=0x555556701880) at ./block.c:1104 #8 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556757190, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffdec8) at ./block.c:1833 #9 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffdec8) at ./block.c:1588 #10 0x0000555555b0e24c in bdrv_open_inherit (filename=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x5555566ff670, flags=<optimized out>, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe1a0) at ./block.c:1794 #11 0x0000555555b0f7b1 in bdrv_open (filename=<optimized out>, reference=<optimized out>, options=<optimized out>, flags=<optimized out>, errp=<optimized out>) at ./block.c:1924 #12 0x0000555555b4890b in blk_new_open (filename=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=0x0, options=0x5555566f90b0, flags=0, errp=0x7fffffffe1a0) at ./block/block-backend.c:160 #13 0x000055555580c90f in blockdev_init (file=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=0x5555566f90b0, errp=0x7fffffffe1a0) at ./blockdev.c:582 #14 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #15 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #16 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #17 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
关联队列1:io_work_queue
|
|
// io_work_queue,所有rbd io操作的主队列,用来处理异步IO,在ImageCtx构造函数中初始化 // ictx->io_work_queue->aio_write/ictx->io_work_queue->aio_discard/ictx->io_work_queue->aio_read/ictx->io_work_queue->aio_flush/... ImageCtx::ImageCtx() { ..... io_work_queue = new io::ImageRequestWQ<>( this, "librbd::io_work_queue", cct->_conf->get_val<int64_t>("rbd_op_thread_timeout"), thread_pool); // ImageRequestWQ继承自ThreadPool::PointerWQ,初始化过程中(构造函数里)会把自己注册到thread_pool.work_queues里,thread_pool里绑定了op_work_queue用来调用IO操作结束后的回调,thread_pool用来处理ImageRequestWQ的所有IO操作,也即ictx->io_work_queue->aio_write最终都是由thread_pool的worker函数来处理的,处理结束后调用对应的回调,thread_pool的worker就是下面tp_thread启动过程。 // ThreadPoolSingleton的op_work_queue是ContextWQ *,每个线程池只有一个,每个rbd镜像只有一个io处理线程池,而ThreadPool的work_queues是vector<WorkQueue_*>,保存了一个rbd卷的op_work_queue和io_work_queue(都是在new的时候register的)。 ...... } |
入队过程:见下面主要代码流程部分,从ImageRequestWQ::aio_write()到入队io_work_queue。
关联队列2:op_work_queue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
// op_work_queue是用来异步调用IO操作的callback,跟Finisher有关(啥关系?) // op_work_queue == ThreadPoolSingleton->op_work_queue == new ContextWQ("librbd::op_work_queue", // cct->_conf->get_val<int64_t>("rbd_op_thread_timeout"), // this) // --> 继承自ThreadPool::PointerWQ<Context> // 在创建之后会通过ThreadPool::PointerWQ<Context>::register_work_queue把自己加入到ThreadPool的work_queues ImageCtx::ImageCtx() { ..... get_thread_pool_instance(cct, &thread_pool, &op_work_queue); ..... } void ImageCtx::get_thread_pool_instance(CephContext *cct, ThreadPool **thread_pool, ContextWQ **op_work_queue) { librbd::ThreadPoolSingleton *thread_pool_singleton; cct->lookup_or_create_singleton_object<ThreadPoolSingleton>( thread_pool_singleton, "librbd::thread_pool"); *thread_pool = thread_pool_singleton; *op_work_queue = thread_pool_singleton->op_work_queue; } template<typename T> void lookup_or_create_singleton_object(T*& p, const std::string &name) { ceph_spin_lock(&_associated_objs_lock); if (!_associated_objs.count(name)) { p = new T(this); // p = new librbd::ThreadPoolSingleton(this); _associated_objs[name] = new TypedSingletonWrapper<T>(p); ...... } explicit ThreadPoolSingleton(CephContext *cct) : ThreadPool(cct, "librbd::thread_pool", "tp_librbd", 1, "rbd_op_threads"), op_work_queue(new ContextWQ("librbd::op_work_queue", cct->_conf->get_val<int64_t>("rbd_op_thread_timeout"), this)) { start(); } ContextWQ(const string &name, time_t ti, ThreadPool *tp) : ThreadPool::PointerWQ<Context>(name, ti, 0, tp), // tp = ThreadPoolSingleton m_lock("ContextWQ::m_lock") { this->register_work_queue(); // 注册op_work_queue到ThreadPool的work_queues } |
入队过程:搜索op_work_queue->queue()即可找到,主要是执行各种rbd image控制操作时会用到。
两个队列的关系及出队过程
由tp_librbd(ThreadPool)的work_queues成员保存,work_queues[0] == op_work_queue,work_queues[1] == io_work_queue。在ThreadPool::worker里会死循环处理这两个队列,交替处理。
io_work_queue出队过程:ThreadPoolworker–ThreadPoolPointerWQ_void_dequeue/_void_process/_void_process_finish–ThreadPoolPointerWQ<librbdioImageRequestlibrbd::ImageCtx >_void_process–librbdio::ImageRequestWQlibrbd::ImageCtx::process
op_work_queue出队过程类似,只是最终调用的是ContextWQ::process。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
Thread 1 "qemu-system-x86" hit Breakpoint 5, librbd::ImageCtx::ImageCtx (this=0x5555568cd3a0, image_name=..., image_id=..., snap=<optimized out>, p=..., ro=<optimized out>) at /mnt/ceph/src/librbd/ImageCtx.cc:219 219 if (cct->_conf->get_val<bool>("rbd_auto_exclusive_lock_until_manual_request")) { (gdb) l 214 io_work_queue = new io::ImageRequestWQ<>( 215 this, "librbd::io_work_queue", 216 cct->_conf->get_val<int64_t>("rbd_op_thread_timeout"), 217 thread_pool); 218 219 if (cct->_conf->get_val<bool>("rbd_auto_exclusive_lock_until_manual_request")) { 220 exclusive_lock_policy = new exclusive_lock::AutomaticPolicy(this); 221 } else { 222 exclusive_lock_policy = new exclusive_lock::StandardPolicy(this); 223 } (gdb) p io_work_queue $38 = (librbd::io::ImageRequestWQ<librbd::ImageCtx> *) 0x5555568cfc90 (gdb) p io_work_queue.work_queues There is no member or method named work_queues. (gdb) p io_work_queue. ImageRequestWQ aio_read front m_on_shutdown process_finish unblock_writes PointerWQ aio_write get_pool_lock m_pool queue write WorkQueue_ aio_writesame handle_acquire_lock m_processing read writes_blocked _clear block_writes handle_blocked_writes m_queued_reads register_work_queue writes_empty _empty compare_and_write handle_refreshed m_queued_writes requeue writesame _void_dequeue discard is_lock_required m_require_lock_on_read require_lock_on_read ~ImageRequestWQ _void_process drain m_image_ctx m_require_lock_on_write set_require_lock ~PointerWQ _void_process_finish empty m_in_flight_ios m_shutdown shut_down ~WorkQueue_ _vptr.WorkQueue_ fail_in_flight_io m_in_flight_writes m_write_blocker_contexts signal aio_compare_and_write finish_in_flight_io m_io_blockers m_write_blockers start_in_flight_io aio_discard finish_in_flight_write m_items name suicide_interval aio_flush finish_queued_io m_lock process timeout_interval (gdb) p io_work_queue.m_pool $39 = (ThreadPool *) 0x5555568cdff0 (gdb) p io_work_queue.m_pool.work_queues $40 = std::vector of length 2, capacity 2 = {0x5555568ce290, 0x5555568cfc90} (gdb) p io_work_queue.m_pool.next_work_queue $41 = 1 (gdb) p op_work_queue.m_pool.next_work_queue $42 = 1 (gdb) p op_work_queue.m_pool $43 = (ThreadPool *) 0x5555568cdff0 (gdb) p io_work_queue.m_pool.work_queues[0] $44 = (ThreadPool::WorkQueue_ *) 0x5555568ce290 (gdb) p io_work_queue $45 = (librbd::io::ImageRequestWQ<librbd::ImageCtx> *) 0x5555568cfc90 (gdb) p op_work_queue $46 = (ContextWQ *) 0x5555568ce290 (gdb) p io_work_queue.m_pool.work_queues[1] $47 = (ThreadPool::WorkQueue_ *) 0x5555568cfc90 (gdb) p op_work_queue.m_pool.work_queues[1] $48 = (ThreadPool::WorkQueue_ *) 0x5555568cfc90 (gdb) p op_work_queue.m_pool.work_queues[0] $49 = (ThreadPool::WorkQueue_ *) 0x5555568ce290 |
finisher thread
执行体
Finisher::finisher_thread_entry
thread1:fn-radosclient
- 启动及用途:libradosRadosClientconnect里启动的finisher thread,为rados client服务,用来执行相关回调
thread2:fn_anonymous
- 启动及用途:MonClient::init里启动的finisher thread,为monitor client服务,用来执行相关回调
- 与fn-radosclient的区别:anonymous不会通过perfcounter记录队列长度(queue_len),处理延时(complete_latency),而fn-radosclient会记录
thread3:taskfin_librbd
- 启动及用途:主要用来给ImageWatcher对象执行各种任务(基于SafeTimer定时的或者基于finisher_queue的),ImageWatcher主要是在镜像属性变动的发送通知给关注方。
- 入队过程与其他两个类似,看queue方法调用位置即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// 启动过程,handle_v2_apply_metadata是在打开rbd image时注册的回调,它又初始化了ImageWatcher对象 Thread 16 "fn-radosclient" hit Breakpoint 18, librbd::ImageWatcher<librbd::ImageCtx>::ImageWatcher (this=0x7fffb405ae50, image_ctx=...) at /mnt/ceph/src/librbd/ImageWatcher.cc:67 67 m_task_finisher(new TaskFinisher<Task>(*m_image_ctx.cct)), (gdb) bt #0 librbd::ImageWatcher<librbd::ImageCtx>::ImageWatcher (this=0x7fffb405ae50, image_ctx=...) at /mnt/ceph/src/librbd/ImageWatcher.cc:67 #1 0x00007fffdf0485bc in librbd::ImageCtx::register_watch (this=0x5555568c9b80, on_finish=0x7fffb40020f0) at /mnt/ceph/src/librbd/ImageCtx.cc:875 #2 0x00007fffdf0ef10d in librbd::image::OpenRequest<librbd::ImageCtx>::send_register_watch (this=this@entry=0x5555568cdd90) at /mnt/ceph/src/librbd/image/OpenRequest.cc:490 #3 0x00007fffdf0f6697 in librbd::image::OpenRequest<librbd::ImageCtx>::handle_v2_apply_metadata (this=this@entry=0x5555568cdd90, result=result@entry=0x7fffc17f97f4) at /mnt/ceph/src/librbd/image/OpenRequest.cc:471 #4 0x00007fffdf0f6b6f in librbd::util::detail::rados_state_callback<librbd::image::OpenRequest<librbd::ImageCtx>, &librbd::image::OpenRequest<librbd::ImageCtx>::handle_v2_apply_metadata, true> (c=<optimized out>, arg=0x5555568cdd90) at /mnt/ceph/src/librbd/Utils.h:39 #5 0x00007fffded2abcd in librados::C_AioComplete::finish (this=0x7fffc4000aa0, r=<optimized out>) at /mnt/ceph/src/librados/AioCompletionImpl.h:169 #6 0x00007fffded0b109 in Context::complete (this=0x7fffc4000aa0, r=<optimized out>) at /mnt/ceph/src/include/Context.h:70 #7 0x00007fffd61f6ce0 in Finisher::finisher_thread_entry (this=0x5555567e2100) at /mnt/ceph/src/common/Finisher.cc:72 #8 0x00007ffff2a7d494 in start_thread (arg=0x7fffc17fa700) at pthread_create.c:333 #9 0x00007ffff27bfacf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 |
|
|
TaskFinisher(CephContext &cct) : m_cct(cct) { TaskFinisherSingleton *singleton; cct.lookup_or_create_singleton_object<TaskFinisherSingleton>( singleton, "librbd::TaskFinisher::m_safe_timer"); m_lock = &singleton->m_lock; m_safe_timer = singleton->m_safe_timer; m_finisher = singleton->m_finisher; } explicit TaskFinisherSingleton(CephContext *cct) : m_lock("librbd::TaskFinisher::m_lock") { m_safe_timer = new SafeTimer(cct, m_lock, false); m_safe_timer->init(); // 启动一个SafeTimer线程 m_finisher = new Finisher(cct, "librbd::TaskFinisher::m_finisher", "taskfin_librbd"); m_finisher->start(); // 启动线程taskfin_librbd } |
关联队列:Finisher::finisher_queue、finisher_queue_rval
二者区别见注释:
|
|
/// Queue for contexts for which complete(0) will be called. /// NULLs in this queue indicate that an item from finisher_queue_rval /// should be completed in that place instead. vector<Context*> finisher_queue; /// Queue for contexts for which the complete function will be called /// with a parameter other than 0. list<pair<Context*,int> > finisher_queue_rval; |
- 入队过程:所有调用Finisher::queue函数的地方(一般都是finisher.queue,如c->io->client->finisher.queue),
- 出队过程:线程执行体Finisher::finisher_thread_entry里面出队
入队过程示例(fn-radosclient线程):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
Thread 8 "msgr-worker-2" hit Breakpoint 17, Objecter::handle_osd_op_reply (this=this@entry=0x5555568bda60, m=m@entry=0x7fffc8390ba0) at /mnt/ceph/src/osdc/Objecter.cc:3558 (gdb) bt #0 librados::IoCtxImpl::C_aio_Complete::finish (this=0x7fffb00027b0, r=0) at /mnt/ceph/src/librados/IoCtxImpl.cc:2030 #1 0x00007fffded0b109 in Context::complete (this=0x7fffb00027b0, r=<optimized out>) at /mnt/ceph/src/include/Context.h:70 #2 0x00007fffded6dcae in Objecter::handle_osd_op_reply (this=this@entry=0x5555568bda60, m=m@entry=0x7fffc8390ba0) at /mnt/ceph/src/osdc/Objecter.cc:3558 #3 0x00007fffded7887b in Objecter::ms_dispatch (this=0x5555568bda60, m=0x7fffc8390ba0) at /mnt/ceph/src/osdc/Objecter.cc:970 #4 0x00007fffded7dbca in Objecter::ms_fast_dispatch (this=<optimized out>, m=0x7fffc8390ba0) at /mnt/ceph/src/osdc/Objecter.h:2099 #5 0x00007fffd627296e in Messenger::ms_fast_dispatch (m=0x7fffc8390ba0, this=0x555556830c90) at /mnt/ceph/src/msg/Messenger.h:639 #6 DispatchQueue::fast_dispatch (this=0x555556830e10, m=m@entry=0x7fffc8390ba0) at /mnt/ceph/src/msg/DispatchQueue.cc:71 #7 0x00007fffd638c533 in AsyncConnection::process (this=0x7fffb8007cd0) at /mnt/ceph/src/msg/async/AsyncConnection.cc:792 #8 0x00007fffd639d208 in EventCenter::process_events (this=this@entry=0x55555688bc80, timeout_microseconds=<optimized out>, timeout_microseconds@entry=30000000, working_dur=working_dur@entry=0x7fffd1c1a868) at /mnt/ceph/src/msg/async/Event.cc:409 #9 0x00007fffd63a1e98 in NetworkStack::<lambda()>::operator()(void) const (__closure=0x5555568b8ee8) at /mnt/ceph/src/msg/async/Stack.cc:51 #10 0x00007fffd5a82e6f in ?? () from /usr/lib/x86_64-linux-gnu/libstdc++.so.6 #11 0x00007ffff2a7d494 in start_thread (arg=0x7fffd1c1b700) at pthread_create.c:333 #12 0x00007ffff27bfacf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 2015 void librados::IoCtxImpl::C_aio_Complete::finish(int r) 2016 { (gdb) 2028 if (c->callback_complete || (gdb) 2030 c->io->client->finisher.queue(new C_AioComplete(c)); (gdb) p c->io $10 = (librados::IoCtxImpl *) 0x5555568ca660 (gdb) p c $11 = (librados::AioCompletionImpl *) 0x7fffb0011750 (gdb) p c->io->client $12 = (librados::RadosClient *) 0x5555567e1520 (gdb) p c->callback_complete $14 = (rados_callback_t) 0x7fffdf12a1a0 <librbd::util::detail::rados_callback<librbd::io::AbstractObjectWriteRequest<librbd::ImageCtx>, &librbd::io::AbstractObjectWriteRequest<librbd::ImageCtx>::handle_write_object>(void*, void*)> |
handle_write_object是write_object函数注册的回调,属于tp_librbd线程,也即处理io的线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
template <typename I> void AbstractObjectWriteRequest<I>::write_object() { I *image_ctx = this->m_ictx; ldout(image_ctx->cct, 20) << dendl; librados::ObjectWriteOperation write; if (m_copyup_enabled) { ldout(image_ctx->cct, 20) << "guarding write" << dendl; write.assert_exists(); } add_write_hint(&write); add_write_ops(&write); assert(write.size() != 0); librados::AioCompletion *rados_completion = librbd::util::create_rados_callback< //radosclient写回调 AbstractObjectWriteRequest<I>, &AbstractObjectWriteRequest<I>::handle_write_object>(this); int r = image_ctx->data_ctx.aio_operate( // librados::IoCtx::aio_operate this->m_oid, rados_completion, &write, m_snap_seq, m_snaps, (this->m_trace.valid() ? this->m_trace.get_info() : nullptr)); assert(r == 0); rados_completion->release(); } |
rados_completion回调最终传递给了ObjecterOponfinish(经过一次封装:C_aio_Complete(c)),实现了从tp_librbd线程转到msgr-worker-*线程,再到fn-radosclient线程(也即Finisher线程)的流转,这也是(几乎)所有回调都由Finisher线程调用的缘由。
msgr-worker-*
- 暂未深入分析
- 启动及用途:异步消息收发线程,主要与ms_dispatch、ms_local线程交互
- 关联的队列:用于处理各种事件
- 执行体:NetworkStackadd_thread里面return的lambda函数,由PosixNetworkStackspawn_worker启动
- 数量:由配置项cct->_conf->ms_async_op_threads决定,默认值3,代码里写死上限值24个,配置项超出这个会被强制改为24,看代码逻辑应该不能在线修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
// 启动 Thread 1 "qemu-system-x86" hit Breakpoint 5, NetworkStack::add_thread (this=this@entry=0x555556831dc0, i=i@entry=0) at /mnt/ceph/src/msg/async/Stack.cc:37 37 Worker *w = workers[i]; (gdb) bt #0 NetworkStack::add_thread (this=this@entry=0x555556831dc0, i=i@entry=0) at /mnt/ceph/src/msg/async/Stack.cc:37 #1 0x00007fffd63a2dd5 in NetworkStack::start (this=0x555556831dc0) at /mnt/ceph/src/msg/async/Stack.cc:135 #2 0x00007fffd6396704 in AsyncMessenger::AsyncMessenger (this=0x555556830bf0, cct=0x5555567522b0, name=..., type=..., mname=..., _nonce=11119027854570673215) at /mnt/ceph/src/msg/async/AsyncMessenger.cc:265 #3 0x00007fffd634409f in Messenger::create (cct=cct@entry=0x5555567522b0, type="async+posix", name=..., lname="", nonce=<optimized out>, cflags=0) at /mnt/ceph/src/msg/Messenger.cc:43 #4 0x00007fffd634476a in Messenger::create_client_messenger (cct=0x5555567522b0, lname="") at /mnt/ceph/src/msg/Messenger.cc:23 #5 0x00007fffded35ff5 in librados::RadosClient::connect (this=this@entry=0x5555567e1480) at /mnt/ceph/src/librados/RadosClient.cc:257 #6 0x00007fffdece268f in rados_connect (cluster=0x5555567e1480) at /mnt/ceph/src/librados/librados.cc:2851 #7 0x00007fffdf534d96 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd68) at ./block/rbd.c:553 #8 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd58, options=0x555556747120, file=0x0, bs=0x555556701880) at ./block.c:1104 #9 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556747120, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffdeb8) at ./block.c:1833 #10 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffdeb8) at ./block.c:1588 #11 0x0000555555b0e24c in bdrv_open_inherit (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=0x5555566ff670, options@entry=0x5555566f90b0, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe190) at ./block.c:1794 #12 0x0000555555b0f7b1 in bdrv_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block.c:1924 #13 0x0000555555b4890b in blk_new_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block/block-backend.c:160 #14 0x000055555580c90f in blockdev_init (file=file@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=bs_opts@entry=0x5555566f90b0, errp=errp@entry=0x7fffffffe190) at ./blockdev.c:582 #15 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #16 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #17 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #18 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
admin_socket
- 用途:用来创建ceph-client.admin.2840389.94310395876384.asok,socket文件位置由ceph.conf配置文件中的[client]admin_socket = /var/run/ceph/qemu/$cluster-$type.$id.$pid.$cctid.asok决定。创建完之后作为UNIX domain socket的server端接收客户端请求,并给出响应,客户端可以用ceph –admin-daemon ceph-client.admin.2840389.94310395876384.asok命令发送请求,支持配置修改、perf dump等命令,具体命令列表可以用help子命令查看。
- 初始化及启动:在CephContext构造函数中初始化,在CephContext::start_service_thread中启动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// 初始化 #0 CephContext::CephContext (this=0x555556752f30, module_type_=8, code_env=CODE_ENVIRONMENT_LIBRARY, init_flags_=0) at /mnt/ceph/src/common/ceph_context.cc:558 #1 0x00007fffd64525f1 in common_preinit (iparams=..., code_env=code_env@entry=CODE_ENVIRONMENT_LIBRARY, flags=flags@entry=0) at /mnt/ceph/src/common/common_init.cc:34 #2 0x00007fffded093f0 in rados_create_cct (clustername=clustername@entry=0x7fffded9effd "", iparams=iparams@entry=0x7fffffffd2b0) at /mnt/ceph/src/librados/librados.cc:2769 #3 0x00007fffded0996e in rados_create (pcluster=pcluster@entry=0x555556749fc0, id=0x0) at /mnt/ceph/src/librados/librados.cc:2785 #4 0x00007fffdf534d0e in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd48) at ./block/rbd.c:507 #5 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd38, options=0x555556757190, file=0x0, bs=0x555556701880) at ./block.c:1104 #6 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556757190, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffde98) at ./block.c:1833 #7 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffde98) at ./block.c:1588 #8 0x0000555555b0e24c in bdrv_open_inherit (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=0x5555566ff670, options@entry=0x5555566f90b0, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe170) at ./block.c:1794 #9 0x0000555555b0f7b1 in bdrv_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe170) at ./block.c:1924 #10 0x0000555555b4890b in blk_new_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe170) at ./block/block-backend.c:160 #11 0x000055555580c90f in blockdev_init (file=file@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=bs_opts@entry=0x5555566f90b0, errp=errp@entry=0x7fffffffe170) at ./blockdev.c:582 #12 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #13 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #14 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #15 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// 启动 Thread 1 "qemu-system-x86" hit Breakpoint 2, 0x00007fffd6182600 in CephContext::start_service_thread()@plt () from /usr/local/lib/ceph/libceph-common.so.0 (gdb) bt #0 0x00007fffd6182600 in CephContext::start_service_thread()@plt () from /usr/local/lib/ceph/libceph-common.so.0 #1 0x00007fffd645b3cc in common_init_finish (cct=0x5555567522b0) at /mnt/ceph/src/common/common_init.cc:95 #2 0x00007fffded35fa0 in librados::RadosClient::connect (this=this@entry=0x5555567e1480) at /mnt/ceph/src/librados/RadosClient.cc:240 #3 0x00007fffdece268f in rados_connect (cluster=0x5555567e1480) at /mnt/ceph/src/librados/librados.cc:2851 #4 0x00007fffdf534d96 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd68) at ./block/rbd.c:553 #5 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd58, options=0x555556747120, file=0x0, bs=0x555556701880) at ./block.c:1104 #6 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556747120, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffdeb8) at ./block.c:1833 #7 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffdeb8) at ./block.c:1588 #8 0x0000555555b0e24c in bdrv_open_inherit (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=0x5555566ff670, options@entry=0x5555566f90b0, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe190) at ./block.c:1794 #9 0x0000555555b0f7b1 in bdrv_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block.c:1924 #10 0x0000555555b4890b in blk_new_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block/block-backend.c:160 #11 0x000055555580c90f in blockdev_init (file=file@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=bs_opts@entry=0x5555566f90b0, errp=errp@entry=0x7fffffffe190) at ./blockdev.c:582 #12 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #13 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #14 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #15 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
ms_dispatch、ms_local
ms_dispatch
- 用途:暂未深入分析,接收ms_local线程转发的普通dispatch消息,然后转发给Messager注册的普通dispatcher处理(dispatcher有MgrClient、Objecter、RadosClient,他们都继承自Dispatcher类)
- 关联队列:优先级队列PrioritizedQueue<QueueItem, uint64_t> mqueue
- 入队:通过DispatchQueue::enqueue入队
- 出队:线程执行体DispatchQueue::entry
ms_local
- 用途:初步理解是接收librbd client端请求,转发给ms_dispatch线程处理(普通dispatch,入队mqueue),或者fast dispatch(直接通过Messenger的fast dispatcher发送,messenger目前为AsyncMessenger,dispatcher有MgrClient、Objecter、RadosClient,他们都继承自Dispatcher类)
- 关联队列:list<pair<Message *, int> > local_messages
- 入队:通过DispatchQueue::local_delivery入队
- 出队:线程执行体DispatchQueue::run_local_delivery
启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
// DispatchQueue::start会启动两个线程: // dispatch_thread.create("ms_dispatch"); // local_delivery_thread.create("ms_local"); Thread 1 "qemu-system-x86" hit Breakpoint 2, DispatchQueue::start (this=this@entry=0x555556830d10) at /mnt/ceph/src/msg/DispatchQueue.cc:229 229 { (gdb) bt #0 DispatchQueue::start (this=this@entry=0x555556830d10) at /mnt/ceph/src/msg/DispatchQueue.cc:229 #1 0x00007fffd639242e in AsyncMessenger::ready (this=0x555556830b90) at /mnt/ceph/src/msg/async/AsyncMessenger.cc:306 #2 0x00007fffded373a6 in Messenger::add_dispatcher_head (d=<optimized out>, this=0x555556830b90) at /mnt/ceph/src/msg/Messenger.h:397 #3 librados::RadosClient::connect (this=this@entry=0x5555567e1420) at /mnt/ceph/src/librados/RadosClient.cc:282 #4 0x00007fffdece268f in rados_connect (cluster=0x5555567e1420) at /mnt/ceph/src/librados/librados.cc:2851 #5 0x00007fffdf534d96 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd68) at ./block/rbd.c:553 #6 0x0000555555b0e658 in bdrv_open_common (errp=0x7fffffffdd58, options=0x555556747120, file=0x0, bs=0x555556701880) at ./block.c:1104 #7 bdrv_open_inherit (filename=<optimized out>, filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=<optimized out>, options=0x555556747120, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, errp=0x7fffffffdeb8) at ./block.c:1833 #8 0x0000555555b0f68f in bdrv_open_child (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", options=options@entry=0x5555566ff670, bdref_key=bdref_key@entry=0x555555c24c69 "file", parent=parent@entry=0x5555566fb2c0, child_role=child_role@entry=0x555556152c80 <child_file>, allow_none=allow_none@entry=true, errp=0x7fffffffdeb8) at ./block.c:1588 #9 0x0000555555b0e24c in bdrv_open_inherit (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=0x5555566ff670, options@entry=0x5555566f90b0, flags=<optimized out>, flags@entry=0, parent=parent@entry=0x0, child_role=child_role@entry=0x0, errp=0x7fffffffe190) at ./block.c:1794 #10 0x0000555555b0f7b1 in bdrv_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block.c:1924 #11 0x0000555555b4890b in blk_new_open (filename=filename@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", reference=reference@entry=0x0, options=options@entry=0x5555566f90b0, flags=flags@entry=0, errp=errp@entry=0x7fffffffe190) at ./block/block-backend.c:160 #12 0x000055555580c90f in blockdev_init (file=file@entry=0x5555566f0e00 "rbd:rbd/vol1:auth_supported=none:mon_host=192.168.0.2\\:6789", bs_opts=bs_opts@entry=0x5555566f90b0, errp=errp@entry=0x7fffffffe190) at ./blockdev.c:582 #13 0x0000555555936f88 in drive_new (all_opts=0x5555566883a0, block_default_type=<optimized out>) at ./blockdev.c:1080 #14 0x00005555559473d1 in drive_init_func (opaque=<optimized out>, opts=<optimized out>, errp=<optimized out>) at ./vl.c:1191 #15 0x0000555555bbcf7a in qemu_opts_foreach (list=<optimized out>, func=0x5555559473c0 <drive_init_func>, opaque=0x5555566a6b30, errp=0x0) at ./util/qemu-option.c:1116 #16 0x000055555580ffdf in main (argc=<optimized out>, argv=<optimized out>, envp=<optimized out>) at ./vl.c:4481 |
safe_timer
- 用途:管理及触发定时任务事件,librbd中主要用来跟monitor保持心跳(MonClient::schedule_tick),以及ImageWatcher的定时事件。
- 初始化及启动:qemu中一共启动了3个线程,其中一处是在libradosRadosClientRadosClient构造函数中初始化,在libradosRadosClientconnect中调用SafeTimerinit启动。通过SafeTimer类进行管理和对外提供接口,SafeTimer类包含一个SafeTimerThread类型的成员thread,SafeTimerThread继承Thread类,safe_timer线程通过SafeTimerinit函数使用thread成员进行创建及启动,线程执行的实体函数是SafeTimertimer_thread(SafeTimerThreadentry里面调用),用来轮询检查是否有新的定时任务事件需要触发。另一处是在ImageWatcher对象初始化时启动,第三处未分析,在构造函数处加断点调试即可知晓。
- 与cephtimer_detailtimer的关系:二者都有定时器功能,但cephtimer_detailtimer更轻量(参考该类的注释),IO卡顿预警功能使用的是cephtimer_detailtimer。
|
|
// 建立连接的时候触发心跳tick流程,一次tick结束后会在回调函数里设置下次tick事件,无限循环 #0 SafeTimer::add_event_after (this=0x5555567e16a8, seconds=10, callback=0x5555568c4b90) at /mnt/ceph/src/common/Timer.cc:118 #1 0x00007fffd6244100 in MonClient::init (this=this@entry=0x5555567e14c8) at /mnt/ceph/src/mon/MonClient.cc:404 #2 0x00007fffded36cfa in librados::RadosClient::connect (this=this@entry=0x5555567e1480) at /mnt/ceph/src/librados/RadosClient.cc:292 #3 0x00007fffdece268f in rados_connect (cluster=0x5555567e1480) at /mnt/ceph/src/librados/librados.cc:2851 #4 0x00007fffdf534d96 in qemu_rbd_open (bs=0x555556701880, options=<optimized out>, flags=24578, errp=0x7fffffffdd68) at ./block/rbd.c:553 |
关联的队列:SafeTimer::schedule
- 入队过程:SafeTimeradd_event_after、SafeTimeradd_event_at
- 出队过程:SafeTimercancel_event、SafeTimercancel_all_events,以及SafeTimer::timer_thread中正常的事件触发。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
void MonClient::schedule_tick() { struct C_Tick : public Context { MonClient *monc; explicit C_Tick(MonClient *m) : monc(m) {} void finish(int r) override { // 事件回调 monc->tick(); } }; if (_hunting()) { timer.add_event_after(cct->_conf->mon_client_hunt_interval * reopen_interval_multiplier, new C_Tick(this)); } else // 参数1表示事件触发延时,参数2是事件回调类,继承自Context,事件触发时SafeTimer::timer_thread会调用C_Tick的complete函数,也即Context->complete,它又调用了finish函数,也即实际的事件回调。 timer.add_event_after(cct->_conf->mon_client_ping_interval, new C_Tick(this)); } |
service
- 用途:CephContextServiceThread::entry是线程执行体,有3个工作,1是检查是否需要重新打开log文件,2是检查心跳,3是更新perfcounter中的记录值,但如果是默认配置情况下,这个线程2、3两个任务是不做的。
- 初始化及启动:过程与admin_socket的启动过程相同,都在CephContext::start_service_thread中完成
log
- 初始化及启动:在CephContext构造函数中初始化和启动。
- 用途:负责文件日志打印和内存日志的存储和dump(通过admin socket)。
主要代码流程分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
// qemu 到 ImageRequestWQ<I>::aio_write(): Thread 37 "CPU 0/TCG" hit Breakpoint 3, librbd::io::ImageRequestWQ<librbd::ImageCtx>::aio_write(librbd::io::AioCompletion*, unsigned long, unsigned long, ceph::buffer::list&&, int, bool) (this=0x55cbc3898890, c=0x7facc57b9b70, off=off@entry=26629120, len=len@entry=1024, bl=bl@entry=<unknown type in /usr/local/lib/librbd.so.1, CU 0x1dbf9f7, DIE 0x1e87755>, op_flags=op_flags@entry=0, native_async=true) at /mnt/ceph/src/librbd/io/ImageRequestWQ.cc:239 239 void ImageRequestWQ<I>::aio_write(AioCompletion *c, uint64_t off, uint64_t len, (gdb) bt #0 librbd::io::ImageRequestWQ<librbd::ImageCtx>::aio_write(librbd::io::AioCompletion*, unsigned long, unsigned long, ceph::buffer::list&&, int, bool) ( this=0x55cbc3898890, c=0x7facc57b9b70, off=off@entry=26629120, len=len@entry=1024, bl=bl@entry=<unknown type in /usr/local/lib/librbd.so.1, CU 0x1dbf9f7, DIE 0x1e87755>, op_flags=op_flags@entry=0, native_async=true) at /mnt/ceph/src/librbd/io/ImageRequestWQ.cc:239 #1 0x00007fad47414310 in rbd_aio_write (image=<optimized out>, off=off@entry=26629120, len=len@entry=1024, buf=buf@entry=0x7facc57ba000 "\300;9\230", c=<optimized out>) at /mnt/ceph/src/librbd/librbd.cc:3536 #2 0x00007fad4791633a in rbd_start_aio (bs=<optimized out>, off=26629120, qiov=<optimized out>, size=1024, cb=<optimized out>, opaque=<optimized out>, cmd=RBD_AIO_WRITE) at ./block/rbd.c:697 #3 0x00007fad47916426 in qemu_rbd_aio_writev (bs=<optimized out>, sector_num=<optimized out>, qiov=<optimized out>, nb_sectors=<optimized out>, cb=<optimized out>, opaque=<optimized out>) at ./block/rbd.c:746 #4 0x000055cbc23b7c3c in bdrv_driver_pwritev (bs=bs@entry=0x55cbc36c9890, offset=offset@entry=26629120, bytes=bytes@entry=1024, qiov=qiov@entry=0x7facc57b8970, flags=flags@entry=0) at ./block/io.c:901 #5 0x000055cbc23b8ed0 in bdrv_aligned_pwritev (bs=bs@entry=0x55cbc36c9890, req=req@entry=0x7facc93d5bc0, offset=offset@entry=26629120, bytes=bytes@entry=1024, align=align@entry=512, qiov=qiov@entry=0x7facc57b8970, flags=0) at ./block/io.c:1360 #6 0x000055cbc23b9ba7 in bdrv_co_pwritev (child=<optimized out>, offset=<optimized out>, offset@entry=26629120, bytes=bytes@entry=1024, qiov=qiov@entry=0x7facc57b8970, flags=flags@entry=0) at ./block/io.c:1610 #7 0x000055cbc237b469 in raw_co_pwritev (bs=0x55cbc36c35e0, offset=26629120, bytes=1024, qiov=<optimized out>, flags=<optimized out>) at ./block/raw_bsd.c:243 #8 0x000055cbc23b7b21 in bdrv_driver_pwritev (bs=bs@entry=0x55cbc36c35e0, offset=offset@entry=26629120, bytes=bytes@entry=1024, qiov=qiov@entry=0x7facc57b8970, flags=flags@entry=0) at ./block/io.c:875 #9 0x000055cbc23b8ed0 in bdrv_aligned_pwritev (bs=bs@entry=0x55cbc36c35e0, req=req@entry=0x7facc93d5e90, offset=offset@entry=26629120, bytes=bytes@entry=1024, align=align@entry=1, qiov=qiov@entry=0x7facc57b8970, flags=0) at ./block/io.c:1360 #10 0x000055cbc23b9ba7 in bdrv_co_pwritev (child=<optimized out>, offset=<optimized out>, offset@entry=26629120, bytes=bytes@entry=1024, qiov=qiov@entry=0x7facc57b8970, flags=0) at ./block/io.c:1610 #11 0x000055cbc23ab90d in blk_co_pwritev (blk=0x55cbc36bd690, offset=26629120, bytes=1024, qiov=0x7facc57b8970, flags=<optimized out>) at ./block/block-backend.c:848 #12 0x000055cbc23aba2b in blk_aio_write_entry (opaque=0x7facc58a9b70) at ./block/block-backend.c:1036 #13 0x000055cbc242452a in coroutine_trampoline (i0=<optimized out>, i1=<optimized out>) at ./util/coroutine-ucontext.c:79 #14 0x00007fad5b0a2000 in ?? () from /lib/x86_64-linux-gnu/libc.so.6 #15 0x00007facf9ff98c0 in ?? () #16 0x0000000000000000 in ?? () |
|
|
// 从ImageRequestWQ<I>::aio_write()到入队io_work_queue ImageRequestWQ<I>::aio_write--ImageRequestWQ<I>::queue--ThreadPool::PointerWQ<ImageRequest<I> >::queue(req) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// io_work_queue出队(ThreadPool::worker)到 Objecter::_send_op: Thread 17 "tp_librbd" hit Breakpoint 1, Objecter::_send_op (this=this@entry=0x55cbc3888600, op=op@entry=0x7fad18004410, m=m@entry=0x7fad180089a0) at /mnt/ceph/src/osdc/Objecter.cc:3208 3208 { (gdb) bt #0 Objecter::_send_op (this=this@entry=0x55cbc3888600, op=op@entry=0x7fad18004410, m=m@entry=0x7fad180089a0) at /mnt/ceph/src/osdc/Objecter.cc:3208 #1 0x00007fad47143160 in Objecter::_op_submit (this=this@entry=0x55cbc3888600, op=op@entry=0x7fad18004410, sul=..., ptid=ptid@entry=0x7fad18008168) at /mnt/ceph/src/osdc/Objecter.cc:2486 #2 0x00007fad47148760 in Objecter::_op_submit_with_budget (this=this@entry=0x55cbc3888600, op=op@entry=0x7fad18004410, sul=..., ptid=ptid@entry=0x7fad18008168, ctx_budget=ctx_budget@entry=0x0) at /mnt/ceph/src/osdc/Objecter.cc:2307 #3 0x00007fad471489de in Objecter::op_submit (this=0x55cbc3888600, op=0x7fad18004410, ptid=0x7fad18008168, ctx_budget=0x0) at /mnt/ceph/src/osdc/Objecter.cc:2274 #4 0x00007fad470fda93 in librados::IoCtxImpl::aio_operate (this=0x55cbc3895440, oid=..., o=0x7fad18004390, c=0x7fad180080a0, snap_context=..., flags=flags@entry=0, trace_info=0x0) at /mnt/ceph/src/librados/IoCtxImpl.cc:826 #5 0x00007fad470e1eb0 in librados::IoCtx::aio_operate (this=this@entry=0x55cbc3894980, oid="rbd_data.fad56b8b4567.", '0' <repeats 15 times>, "a", c=c@entry=0x7fad18001d60, o=o@entry=0x7fad297f8b80, snap_seq=0, snaps=std::vector of length 0, capacity 0, trace_info=0x0) at /mnt/ceph/src/librados/librados.cc:1544 #6 0x00007fad4750730b in librbd::io::AbstractObjectWriteRequest<librbd::ImageCtx>::write_object (this=this@entry=0x7fad180083b0) at /mnt/ceph/src/librbd/io/ObjectRequest.cc:528 // radosclient回调在这里创建,并传递给Objecter::handle_osd_op_reply里的onfinish->complete #7 0x00007fad4750af66 in librbd::io::AbstractObjectWriteRequest<librbd::ImageCtx>::pre_write_object_map_update (this=this@entry=0x7fad180083b0) at /mnt/ceph/src/librbd/io/ObjectRequest.cc:496 #8 0x00007fad4750b837 in librbd::io::AbstractObjectWriteRequest<librbd::ImageCtx>::send (this=0x7fad180083b0) at /mnt/ceph/src/librbd/io/ObjectRequest.cc:459 #9 0x00007fad474f7571 in librbd::io::AbstractImageWriteRequest<librbd::ImageCtx>::send_object_requests (this=0x7facc41c0950, object_extents=std::vector of length 1, capacity 1 = {...}, snapc=..., object_requests=0x0) at /mnt/ceph/src/librbd/io/ImageRequest.cc:450 #10 0x00007fad474fcf55 in librbd::io::AbstractImageWriteRequest<librbd::ImageCtx>::send_request (this=0x7facc41c0950) at /mnt/ceph/src/librbd/io/ImageRequest.cc:408 #11 0x00007fad474f8f91 in librbd::io::ImageRequest<librbd::ImageCtx>::send (this=this@entry=0x7facc41c0950) at /mnt/ceph/src/librbd/io/ImageRequest.cc:219 #12 0x00007fad474ff9b5 in librbd::io::ImageRequestWQ<librbd::ImageCtx>::process (this=0x55cbc3898890, req=0x7facc41c0950) at /mnt/ceph/src/librbd/io/ImageRequestWQ.cc:610 #13 0x00007fad3e5d9a68 in ThreadPool::worker (this=0x55cbc3895640, wt=<optimized out>) at /mnt/ceph/src/common/WorkQueue.cc:120 #14 0x00007fad3e5dac10 in ThreadPool::WorkThread::entry (this=<optimized out>) at /mnt/ceph/src/common/WorkQueue.h:448 #15 0x00007fad5b404494 in start_thread (arg=0x7fad297fa700) at pthread_create.c:333 #16 0x00007fad5b146acf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 |
块设备IO到rados对象映射过程(Striper)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
void Striper::file_to_extents( CephContext *cct, const char *object_format, const file_layout_t *layout, uint64_t offset, uint64_t len, uint64_t trunc_size, map<object_t,vector<ObjectExtent> >& object_extents, uint64_t buffer_offset) { ldout(cct, 10) << "file_to_extents " << offset << "~" << len << " format " << object_format << dendl; assert(len > 0); /* * we want only one extent per object! this means that each extent * we read may map into different bits of the final read * buffer.. hence ObjectExtent.buffer_extents */ // layout = {stripe_unit = 4194304, stripe_count = 1, object_size = 4194304, pool_id = 5, pool_ns = ""} __u32 object_size = layout->object_size; __u32 su = layout->stripe_unit; __u32 stripe_count = layout->stripe_count; assert(object_size >= su); if (stripe_count == 1) { ldout(cct, 20) << " sc is one, reset su to os" << dendl; su = object_size; } uint64_t stripes_per_object = object_size / su; // 1 ldout(cct, 20) << " su " << su << " sc " << stripe_count << " os " << object_size << " stripes_per_object " << stripes_per_object << dendl; uint64_t cur = offset; // 26596352 uint64_t left = len; // 8192 while (left > 0) { // layout into objects uint64_t blockno = cur / su; // which block // 6 // which horizontal stripe (Y) uint64_t stripeno = blockno / stripe_count; // stripe_count = 1 // which object in the object set (X) uint64_t stripepos = blockno % stripe_count; // 6 % 1 = 0, always == 0 // which object set uint64_t objectsetno = stripeno / stripes_per_object; // 6 // object id uint64_t objectno = objectsetno * stripe_count + stripepos; // 6 * 1 + 0 = 6 /* rbd image: [obj1(4M) | obj2(4M) | obj3(4M) | ...] = [rbd_data.fad56b8b4567.0000000000000000 | ... | rbd_data.fad56b8b4567.0000000000000006 | ...] */ // find oid, extent // object_format = "rbd_data.fad56b8b4567.%016llx" char buf[strlen(object_format) + 32]; snprintf(buf, sizeof(buf), object_format, (long long unsigned)objectno); object_t oid = buf; // oid = "rbd_data.fad56b8b4567.0000000000000006" // map range into object uint64_t block_start = (stripeno % stripes_per_object) * su; // 0 uint64_t block_off = cur % su; // 26596352 % 4194304 = 1430528 uint64_t max = su - block_off; // 4194304 - 1430528 = 2763776 uint64_t x_offset = block_start + block_off; // 0 + 1430528 uint64_t x_len; if (left > max) // 8192 > 2763776 x_len = max; else x_len = left; // 8192 ldout(cct, 20) << " off " << cur << " blockno " << blockno << " stripeno " << stripeno << " stripepos " << stripepos << " objectsetno " << objectsetno << " objectno " << objectno << " block_start " << block_start << " block_off " << block_off << " " << x_offset << "~" << x_len << dendl; ObjectExtent *ex = 0; vector<ObjectExtent>& exv = object_extents[oid]; if (exv.empty() || exv.back().offset + exv.back().length != x_offset) { exv.resize(exv.size() + 1); ex = &exv.back(); ex->oid = oid; ex->objectno = objectno; ex->oloc = OSDMap::file_to_object_locator(*layout); // 封装对象pool信息 ex->offset = x_offset; ex->length = x_len; ex->truncate_size = object_truncate_size(cct, layout, objectno, trunc_size); // trunc_size = 0 ldout(cct, 20) << " added new " << *ex << dendl; } else { // add to extent ex = &exv.back(); ldout(cct, 20) << " adding in to " << *ex << dendl; ex->length += x_len; } ex->buffer_extents.push_back(make_pair(cur - offset + buffer_offset, // buffer_offset = 0 x_len)); ldout(cct, 15) << "file_to_extents " << *ex << " in " << ex->oloc << dendl; // ldout(cct, 0) << "map: ino " << ino << " oid " << ex.oid << " osd " // << ex.osd << " offset " << ex.offset << " len " << ex.len // << " ... left " << left << dendl; left -= x_len; cur += x_len; } // object_extents = std::map with 1 elements = // {[{name = "rbd_data.fad56b8b4567.", '0' <repeats 15 times>, "6"}] = std::vector of length 1, capacity 1 = {{oid = { // name = "rbd_data.fad56b8b4567.", '0' <repeats 15 times>, "6"}, objectno = 6, offset = 1430528, length = 8192, truncate_size = 0, oloc = {pool = 5, key = "", // nspace = "", hash = -1}, buffer_extents = std::vector of length 1, capacity 1 = {{first = 0, second = 8192}}}}} } |
object到osd的crush计算过程
|
|
Objecter::_op_submit --> Objecter::_calc_target(&op->target, nullptr) --> osdmap->object_locator_to_pg(t->target_oid, t->target_oloc, pgid); \ \ --> _send_op(op, m) |
遗留问题
- 整体IO流程图
- IO到object到op的拆分过程,以及op执行完毕后如何判断用户层单次IO全部执行完毕
- object到osd的crush计算过程
- IO请求发送过程及响应处理过程
perf counter机制
每个image一个perf counter,初始化过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Thread 16 "fn-radosclient" hit Breakpoint 3, librbd::ImageCtx::perf_start (this=this@entry=0x5555568cd300, name="librbd-fad56b8b4567-rbd-vol1") at /mnt/ceph/src/librbd/ImageCtx.cc:365 365 void ImageCtx::perf_start(string name) { (gdb) bt #0 librbd::ImageCtx::perf_start (this=this@entry=0x5555568cd300, name="librbd-fad56b8b4567-rbd-vol1") at /mnt/ceph/src/librbd/ImageCtx.cc:365 #1 0x00007fffdf047f14 in librbd::ImageCtx::init (this=0x5555568cd300) at /mnt/ceph/src/librbd/ImageCtx.cc:276 #2 0x00007fffdf0ee07f in librbd::image::OpenRequest<librbd::ImageCtx>::send_register_watch (this=this@entry=0x5555568c8c00) at /mnt/ceph/src/librbd/image/OpenRequest.cc:477 #3 0x00007fffdf0f57a7 in librbd::image::OpenRequest<librbd::ImageCtx>::handle_v2_apply_metadata (this=this@entry=0x5555568c8c00, result=result@entry=0x7fffc17f97f4) at /mnt/ceph/src/librbd/image/OpenRequest.cc:471 // send_v2_apply_metadata里通过create_rados_callback创建间接回调rados_state_callback(handle_v2_apply_metadata作为模板参数传递给rados_state_callback),rados_state_callback里会调用实际的回调handle_v2_apply_metadata // handle_v2_apply_metadata是send_v2_apply_metadata的回调,而send_v2_apply_metadata被handle_v2_get_data_pool直接调用,handle_v2_get_data_pool又是send_v2_get_data_pool的回调(注册方法跟上面一样),逐级调用+回调(handle_xxx直接调用send_zzz,handle_xxx是它上面的函数send_xxx的回调) // send_v2_detect_header是最开始的入口,打开rbd镜像时从rbd_open调过来 #4 0x00007fffdf0f5c7f in librbd::util::detail::rados_state_callback<librbd::image::OpenRequest<librbd::ImageCtx>, &librbd::image::OpenRequest<librbd::ImageCtx>::handle_v2_apply_metadata, true> (c=<optimized out>, arg=0x5555568c8c00) at /mnt/ceph/src/librbd/Utils.h:39 #5 0x00007fffded2a8dd in librados::C_AioComplete::finish (this=0x7fffc8001470, r=<optimized out>) at /mnt/ceph/src/librados/AioCompletionImpl.h:169 #6 0x00007fffded0ae59 in Context::complete (this=0x7fffc8001470, r=<optimized out>) at /mnt/ceph/src/include/Context.h:70 #7 0x00007fffd61ecb80 in Finisher::finisher_thread_entry (this=0x5555567e59d0) at /mnt/ceph/src/common/Finisher.cc:72 #8 0x00007ffff2a7d494 in start_thread (arg=0x7fffc17fa700) at pthread_create.c:333 #9 0x00007ffff27bfacf in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:97 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
void ImageCtx::perf_start(string name) { auto perf_prio = PerfCountersBuilder::PRIO_DEBUGONLY; if (child == nullptr) { // ensure top-level IO stats are exported for librbd daemons perf_prio = PerfCountersBuilder::PRIO_USEFUL; } // 创建PerfCounters PerfCountersBuilder plb(cct, name, l_librbd_first, l_librbd_last); // 添加实际的counter,支持多种类型,如计数器,时间记录器,平均计数器 plb.add_u64_counter(l_librbd_rd, "rd", "Reads", "r", perf_prio); plb.add_time_avg(l_librbd_rd_latency, "rd_latency", "Latency of reads", "rl", perf_prio); plb.add_time(l_librbd_opened_time, "opened_time", "Opened time", "ots", perf_prio); // 创建实际的perfcounter,并添加到image context的perfcounter集合中 perfcounter = plb.create_perf_counters(); cct->get_perfcounters_collection()->add(perfcounter); // 记录时间 perfcounter->tset(l_librbd_opened_time, ceph_clock_now()); } |
使用过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* added by wangpan */ // tsetp: time set pair, record slowest io start time and elapsed // 自定义了一个counter类型的记录函数,沿用了社区的记录数据结构,但改变了数据结构保存的内容 void PerfCounters::tsetp(int idx, utime_t start, utime_t elapsed) { if (!m_cct->_conf->perf) return; assert(idx > m_lower_bound); assert(idx < m_upper_bound); Mutex::Locker lck(m_lock); // we should modify two params synchronously perf_counter_data_any_d& data(m_data[idx - m_lower_bound - 1]); if (!(data.type & PERFCOUNTER_TIME)) return; if (data.type & PERFCOUNTER_LONGRUNAVG) { if (data.u64 < elapsed.to_nsec()) { data.u64 = elapsed.to_nsec(); // use u64(sum in dump) as io elapsed data.avgcount = start.to_msec(); // use avgcount as io start timestamp data.avgcount2.store(data.avgcount); // useless but for read_avg func run as usual } } } /* added end */ |
|
|
template <typename I> void ImageWriteRequest<I>::update_stats(size_t length) { I &image_ctx = this->m_image_ctx; image_ctx.perfcounter->inc(l_librbd_wr); // 累积计数 image_ctx.perfcounter->inc(l_librbd_wr_bytes, length); // 累积计数 } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
void AioCompletion::complete() { assert(lock.is_locked()); assert(ictx != nullptr); CephContext *cct = ictx->cct; tracepoint(librbd, aio_complete_enter, this, rval); utime_t elapsed; elapsed = ceph_clock_now() - start_time; switch (aio_type) { case AIO_TYPE_GENERIC: case AIO_TYPE_OPEN: case AIO_TYPE_CLOSE: break; case AIO_TYPE_READ: ictx->perfcounter->tinc(l_librbd_rd_latency, elapsed); break; case AIO_TYPE_WRITE: ictx->perfcounter->tinc(l_librbd_wr_latency, elapsed); break; case AIO_TYPE_DISCARD: ictx->perfcounter->tinc(l_librbd_discard_latency, elapsed); break; case AIO_TYPE_FLUSH: ictx->perfcounter->tinc(l_librbd_aio_flush_latency, elapsed); break; case AIO_TYPE_WRITESAME: ictx->perfcounter->tinc(l_librbd_ws_latency, elapsed); break; case AIO_TYPE_COMPARE_AND_WRITE: ictx->perfcounter->tinc(l_librbd_cmp_latency, elapsed); break; default: lderr(cct) << "completed invalid aio_type: " << aio_type << dendl; break; } /* added by wangpan */ switch (aio_type) { case AIO_TYPE_NONE: case AIO_TYPE_GENERIC: case AIO_TYPE_OPEN: case AIO_TYPE_CLOSE: break; // ignore above io type case AIO_TYPE_READ: case AIO_TYPE_WRITE: case AIO_TYPE_DISCARD: case AIO_TYPE_FLUSH: case AIO_TYPE_WRITESAME: case AIO_TYPE_COMPARE_AND_WRITE: { // record all slow io in count, and store the slowest one auto threshold = cct->_conf->get_val<double>("rbd_slow_io_threshold"); if (threshold > 0) { utime_t thr; thr.set_from_double(threshold); if (elapsed >= thr) { ldout(cct, 20) << "elapsed(ms): " << elapsed.to_msec() << dendl; ictx->perfcounter->inc(l_librbd_all_slow_io_count); ictx->perfcounter->tsetp(l_librbd_slowest_io, start_time, elapsed); } } } break; } /* added end */ ...... state = AIO_STATE_CALLBACK; if (complete_cb) { // qemu/block/rbd.c:rbd_finish_aiocb lock.Unlock(); complete_cb(rbd_comp, complete_arg); lock.Lock(); } ...... } |
cephtimer_detailtimer机制
类似SafeTimer,一个线程专门检查定时任务是否需要触发,可以取消定时任务,取消时如果发现任务已经触发了就忽略,没触发就取消任务。
线程未命名,仍然叫qemu-system-x86,在Objecter对象构造的时候启动:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
class Objecter: { private: ceph::timer<ceph::mono_clock> timer; } class timer { public: timer() { lock_guard l(lock); suspended = false; thread = std::thread(&timer::timer_thread, this); // 启动线程 } ...... void timer_thread() { ...... // 执行体,定时检查是否有任务需要触发 } } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
void Objecter::_op_submit_with_budget(Op *op, shunique_lock& sul, ceph_tid_t *ptid, int *ctx_budget) { ...... /* added by wangpan */ auto timeout_warning = cct->_conf->get_val<double>("rados_osd_op_timeout_warning"); if (timeout_warning > 0) { ceph::timespan tw = ceph::make_timespan(timeout_warning); op->onslowop_warning = timer.add_event(tw, [this, op, timeout_warning]() { ldout(cct, 0) << "[slow op] warning(>" << timeout_warning << "s), object name: " << op->target.base_oid.name << ", pool: " << op->target.base_oloc.pool << dendl; } ); ldout(cct, 20) << "added slow op warning timer event: " << op->onslowop_warning << ", threshold: "<< timeout_warning << dendl; } auto timeout_critical = cct->_conf->get_val<double>("rados_osd_op_timeout_critical"); if (timeout_critical > 0) { ceph::timespan tc = ceph::make_timespan(timeout_critical); op->onslowop_critical = timer.add_event(tc, [this, op, timeout_critical]() { ldout(cct, 0) << "[slow op] critical(>" << timeout_critical << "s), object name: " << op->target.base_oid.name << ", pool: " << op->target.base_oloc.pool << dendl; } ); ldout(cct, 20) << "added slow op critical timer event: " << op->onslowop_critical << ", threshold: "<< timeout_critical << dendl; } /* added end */ ...... } void Objecter::_finish_op(Op *op, int r) { ldout(cct, 15) << "finish_op " << op->tid << dendl; // op->session->lock is locked unique or op->session is null if (!op->ctx_budgeted && op->budgeted) put_op_budget(op); /* added by wangpan */ if (op->onslowop_warning) { timer.cancel_event(op->onslowop_warning); ldout(cct, 20) << "cancel slow op warning timer event: " << op->onslowop_warning << dendl; } if (op->onslowop_critical) { timer.cancel_event(op->onslowop_critical); ldout(cct, 20) << "cancel slow op critical timer event: " << op->onslowop_critical << dendl; } /* added end */ ...... } |
参考:Ceph动态更新参数机制浅析 http://t.cn/EPQE1tt