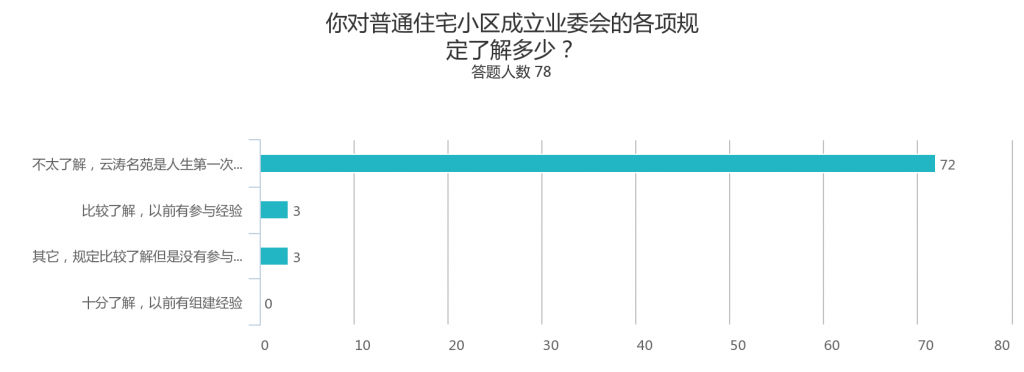
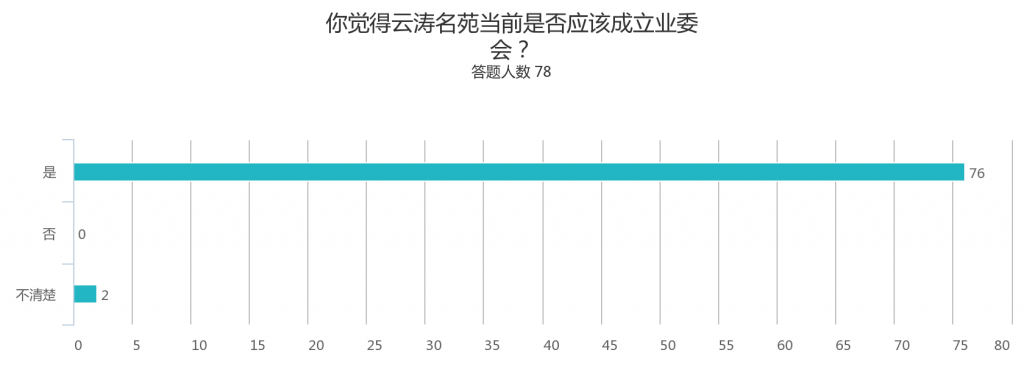
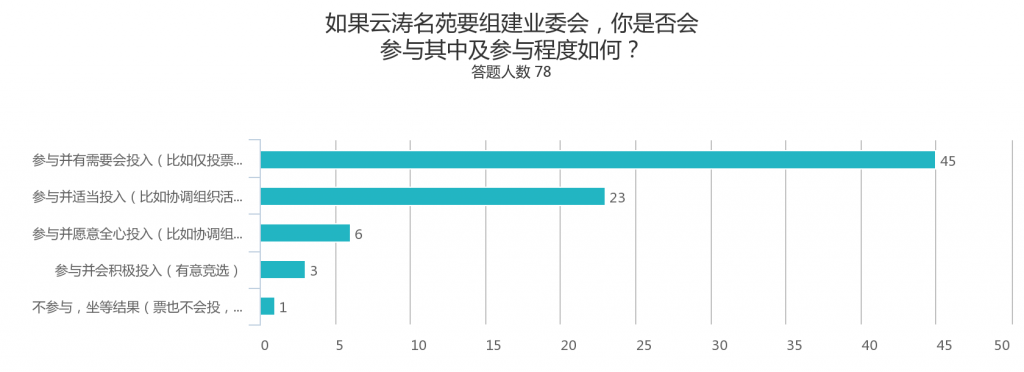
以下为蜂巢正式上线以来,IaaS平台云主机服务相关工作的一些总结
注:根据Jira和个人记忆整理,可能存在遗漏
工作内容列表
- 转移云主机功能支持及优化
- ceilometer计费支持
- 解耦nova-metadata接口
- ceph存储后端支持
- ceilometer+qemu-ga的云主机监控支持
- config drive功能支持
- 租户网络初始化过程优化
- 对应用运维开放部分API
- 无物理资源错误信息详情展示
- 云主机静态IP支持
- nova创建云主机耗时优化
- 云主机操作系统启动耗时优化
- Docker运行环境调研
- 物理机宕机重启云主机自动恢复支持
- 支持超售比例针对单台计算节点设置
- 单台计算节点云主机密度提升
- 错误状态云主机云硬盘数量报警
- keystone token创建及验证耗时优化
- nova/glance/keystone/cinder/umbrella相关服务日志接入ELK
- RabbitMQ服务故障重连问题修复(nova/cinder)
- nova/glance/keystone/cinder/umbrella相关进程支持打印栈信息
- 支持创建不带网卡的云主机
- API性能优化(nova/glance)
- 3.18内核virtio bug修复(修复中)
- glance返回空body问题修复(修复中)
- keystone升级M版本调研
- 支持带网卡转移云主机
- 云主机在线垂直伸缩
- 云主机网络状态检查
工作内容详情
转移云主机功能支持及优化
主要目的是为了加速蜂巢docker运行环境的创建和初始化,提升蜂巢产品形象改进用户体验。改进方法是上层维护云主机资源池(按可用域、规格),当有用户需要创建容器时,直接从资源池中分配云主机并转移给用户,作为docker运行环境(通常耗时0.5~2s),避免了创建云主机流程(通常耗时10~30s)。
针对从资源池转移云主机耗时超过秒级情况,我们又进一步做了优化,取消了转移前后两个租户/用户资源使用量的更新以及发送notification这两步比较耗时的操作(有参数可选是否更新资源使用量),从而进一步加快转移速度(毫秒级)。
ceilometer计费支持
公有云计费功能不可或缺,针对蜂巢提出的对外网网络流量计费需求,我们基于ceilometer从MQ获取了每个租户每个网络端口的流量信息(neutron负责推送流量信息到MQ),并输出相关信息给计费服务。
针对当前计费服务存在的一些问题,如可靠性、可扩展性、易用性、性能等方面的问题,新的计费方案也在设计当中,预计第三季度可以开发完成并上线。
解耦nova-metadata接口
解耦云主机内部对169.254.169.254相关metadata接口的依赖,目的是减轻neutron-sever的压力,减少nova-metadata服务的部署和维护工作,提升平台安全性和可靠性并在一定程度上降低成本,解决因为metadata接口或不可用超时导致的各种问题(如云主机初始化不正确、infos接口获取云主机信息失败等)。
该接口的替代方案是使用config drive,因为从169.254.169.254获取的相关信息基本都是静态的,与云主机各种生命周期操作无关,config drive是一种更安全高效稳定可靠的云主机信息提供方案。
ceph存储后端支持
基于ceph分布式存储系统的流行,以及其与OpenStack深度整合所带来的各种益处,我们也在逐步切换到ceph存储后端,其中涉及到的相关问题有:
- ceph后端接入cinder
- 原nbs后端相关特性的支持(如QoS设置更新、ssd/sas卷类型支持等)
- 部署方案设计(独立部署、与nbs混合部署、镜像存储后端、快存储后端等)
- 快照功能相关优化(在线快照支持、链式快照深度问题优化等)
- OpenStack整合功能验证及改进(如nos+ceph或nbs+ceph混合部署场景的支持、用户使用场景分析及限制等)
- 蜂巢相关需求开发
- 基于ceph存储后端的功能支持(如计算节点宕机自动恢复、在线迁移)
ceilometer+qemu-ga的云主机监控支持
原有监控方式(包含操作系统状态)是在云主机内部增加监控脚本配合定时任务,通过云主机网络来推送监控信息到云监控,存在如下几个方面的问题:
- 安全性(监控脚本+定时任务方案是针对私有云场景设计的,基本没有考虑安全性问题)
- 可靠性(定时任务受用户进程影响较大、依赖云主机网络)
- 可维护性(更新维护不便、出现问题分析困难)
- 未考虑windows操作系统云主机
为此我们基于ceilometer服务,再其框架基础上,增加了qemu-guest-agent获取云主机内部监控数据的功能,相比ceilometer原生。基于libvirt获取监控数据方案,极大提升了监控数据的准确性。并且很好的解决了原有方案存在的问题。
config drive功能支持
config drive主要是为了给云主机提供稳定的信息源,相比依赖网络的nova metadata api,其开销只是一个64M的文件镜像(qcow2格式其实只有1M以内),基本可以忽略,并且具有只读属性,有效防止用户篡改导致的云主机初始化异常。更重要的是其可靠性有极大提升,主要改进了云主机网络异常、nova metadata服务异常、neutron metadata-agent/namespace-proxy异常等场景下导致的云主机初始化异常问题,如云主机主机名错误、静态IP场景下IP地址配置失败、文件注入失败等。
另外该功能也是云主机静态IP功能的基础,如果云主机继续依赖metadata api获取信息,则会出现循环依赖问题(云主机需要网络通过metadata api获取IP等配置信息,但是IP等网络配置信息又依赖metadata api获取)。
租户网络初始化过程优化
私有云环境每个用户都是有效用户,默认为所有用户初始化私有网、L3 router、VPN服务是一种节约运维成本的有效有段。但公有云却并非如此,很多用户注册完成之后,并不一定会真正的创建资源,或者使用到所有网络服务(如VPN服务很多用户都从来没有使用,而是改用web console或者通过公网IP ssh到容器内部),所以修改公有云用户的网络资源初始化流程就特别有必要。我们主要是拆分了租户网络初始化的各个流程,可以做到单独初始化、按需初始化,极大的减少了资源浪费,降低了单个用户的成本开销。
对应用运维开放部分API
主要是开放了容量计算以及平台资源信息等接口,方便应用运维可以将容量监控实现自动化监控报警。
无物理资源错误信息详情展示
该功能主要用来帮助用户(如nlb、rds、nce,或者yun.163.com的IaaS用户等)自己定位云主机创建错误的原因,我们会在没有可用计算资源、网络资源、网络初始化错误等场景下,返回准确的错误信息,用户根据错误信息即可初步确定错误原因。
当然这只是一种事后的补救措施,更加正确或者完美的做法肯定是不让用户遇到创建错误问题,这就要求我们在资源规划、服务可靠性方面多下功夫。目前公有云已经做的相对完善,但私有云仍然有很多问题,所以该功能在私有云环境的作用比公有云要大很多。
云主机静态IP支持
该功能与转移云主机类似,也是为了加快docker运行环境初始化而设计开发的。我们通过分析云主机从创建到网络连通也即可用的耗时,发现相当多的时间都耗费在等待dhcp分配ip上(正常情况下10~60s,异常情况则会超过2分钟甚至始终无法分配ip导致云主机网络不通),为此我们设计并开发了云主机的静态IP方案,在云主机创建或者后续动态挂卸载网卡的时候,可以为网卡配置正确的IP地址、网关、路由、DNS等信息,从而将网络初始化耗时降低到1s以内。
该功能依赖config drive和qemu-guest-agent,config drive用来支持创建过程的静态IP配置,而动态挂载网卡则需要依赖qemu-guest-agent。另外由于官方的cloud-init依赖网络,会导致云主机的网络无法使用其进行配置,所以我们又另外新增了一个服务,用来模拟cloud-init来实现网络配置,在网络服务之前加载,保证网络服务启动时相关配置已经准备完毕,之后cloud-init就可以正确完成其自身工作。
nova创建云主机耗时优化
有了云主机资源池之后,大部分情况下用户创建容器的场景都不需要执行创建云主机操作,而是从资源池转移一台云主机即可。但是也有一定的情况下,资源池云主机耗尽,需要通过新建云主机来完成docker运行环境的初始化,这种情况下就要求云主机创建耗时尽可能少。
我们分析了nova创建云主机流程,发现了一些概率性耗时较长的操作(比如nova-compute定时任务对创建云主机RPC请求处理的影响、以及不合理的加锁逻辑、不必要的资源更新等),并一一进行优化,从优化前的最长1分钟以上到当前平均10s左右(单台创建到可用99值在15s左右)。
云主机操作系统启动耗时优化
创建云主机直到可用包含两大部分,上面提到的nova创建云主机算是第一步,云主机自身操作系统启动是第二部分,我们对这方面的优化除了上面提到的静态IP方案改动,还尝试了各种方案,有些由于效果不佳、性价比较低而最终没有采用(比如qboot代替smbios、重新编译内核去掉initrd等),当前主要采用的优化手段包括优化cloud-init耗时,异步生成ssh host key等。优化后云主机操作系统启动耗时大概在5s左右,正常情况下最长不超过10s,99值应该在6~7s。
Docker运行环境调研
这部分工作也是为了加快docker运行环境的初始化,主要调研了hyper.sh和clear container,以及上面提到的qboot替代smbios方案。但通过分析,发现无法满足我们对安全隔离的要求、或者这些方案无法与OpenStack很好的结合。
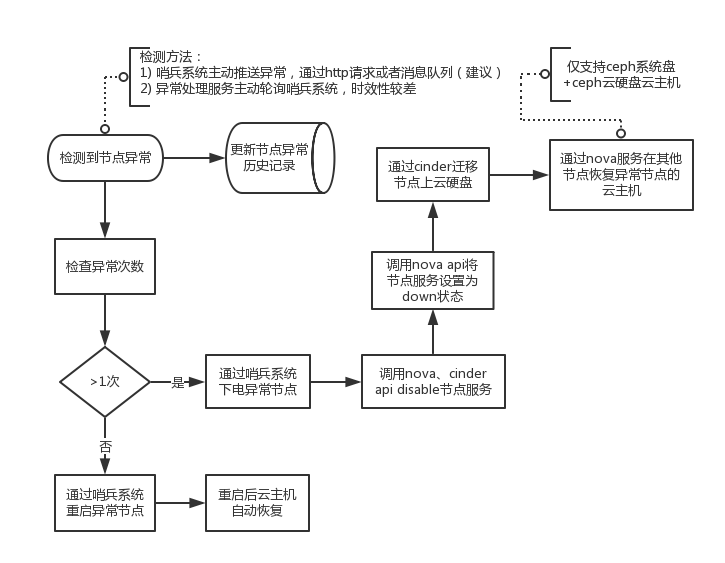
物理机宕机重启云主机自动恢复支持
之前私有云环境的计算节点宕机后,需要做较多的手工运维工作,才能将节点上的云主机恢复可用状态(尤其是网络连通性),私有云主要支撑公司内部产品,这些产品通常具有很好的集群容错性,单节点甚至部分节点宕机对集群影响基本可以忽略不计,所以恢复时间稍长对产品可用率影响不大,但换到公有云环境,则面临更加严格的SLA要求,否则对产品形象和盈利都有很大不利,所以我们分析了影响宕机自动恢复的各个问题点,并针对性的做了改进和多次的线下宕机恢复测试,目前已经可以做到节点宕机重启后无需人工介入节点上所有云主机即可全部恢复可用(通常耗时15分钟左右),主要改进有等待云硬盘挂载完毕、等待ovs规则刷新完毕、并主动刷新虚拟网卡状态,以保证云主机尽快可用。
支持超售比例针对单台计算节点设置&单台计算节点云主机密度提升
这两个工作其实是一个目的,都是为了降低成本。第一个功能使用nova原生的AggregateCoreFilter即可支持,第二个则需要配合更多的测试验证工作,以保证用户体验。
错误状态云主机云硬盘数量报警
这个功能是为了监控线上错误情况,正常情况下应该没有错误,或者仅有个别上层服务用户(如rds、ncr等)参数使用错误导致创建云主机或者云硬盘失败或者物理资源不足导致普通用户创建失败(完全不应该发生),之前出现过一种情况是线上某个服务出现故障,导致物理资源被错误状态云主机占用很多,没有及时清理,影响了剩余物理资源的统计结果,所以我们加上了这个报警,就可以每天(可配置)监控错误情况。该功能由umbrella服务基于ELK报警实现。
keystone token创建及验证耗时优化
测试环境曾经出现过某个用户修改密码导致token、用户创建超时等问题,原因主要是修改密码要清理用户已有的token,如果用户当前使用的token数量太多,而token表又没有加索引,就会锁表很长时间,影响其他用户的操作。加了索引之后,很大程度上缓解了此类问题,但是仍然有概率性的耗时过长问题(创建token偶尔8~10s),我们又去掉了token表中catalog字段的无用内容,并会在后续将keystone数据库使用的硬盘从sas改为ssd,应该会有进一步的性能提升。同时我们也会测试M版本keystone的性能,看下有没有改善。
nova/glance/keystone/cinder/umbrella相关服务日志接入ELK
接入ELK可以方便的进行日志统计分析、问题定位、错误报警等,对服务运行状态监控、性能优化、bug修复等方面有极大的帮助。
RabbitMQ服务故障重连问题修复
当前我们使用的Havana版本OpenStack组件存在该问题,nova、cinder、neutron等服务在使用集群模式的MQ场景下,第一个MQ节点异常之后,不会尝试重连第二个节点,新版本已经修复,但backport回H版本比较困难,我们对其进行了修改,使用了python amqp库来加快移植速度。
nova/glance/keystone/cinder/umbrella相关进程支持打印栈信息
参考neutron之前的实现,执行kill -USR1 $pid可以打印进程的调用栈信息,方便获取调试信息。
支持创建不带网卡的云主机&支持带网卡转移云主机
第一个功能目的是为了减少创建资源池云主机后,从资源池中转移给用户时无法携带网卡,需要先卸载掉所有网卡而优化的,这个功能可以使NCE在创建资源池云主机时不带虚拟网卡,从而省去转移前的卸载网卡操作流程。
第二个功能是为了进一步加快转移速度,我们计划与网络组合作开发携带虚拟网卡转移云主机功能(私有网除外),从而减少资源池云主机转移完毕后,还需要挂载多个虚拟网卡到云主机这一耗时较长的步骤(3张网卡通常需要10s甚至更长时间),私有网卡可以延迟挂载,对用户创建容器过程中的docker运行环境初始化流程影响不大。该功能上线后,预计可以将docker运行环境初始化过程减少到3s以内(上面已经提到云主机转移在1s以内,其他耗时视neutron转移端口接口耗时而定),也即减少了大概10s左右。
云主机在线垂直伸缩
计划通过balloon技术来实现内存的在线动态调整,方便容器的扩容和支持单个云主机运行多个docker实例(属于同一租户)。主要难点是计算节点资源管理和更新问题,以及无法满足内存扩容情况的处理,还有就是内存balloon失败之后的异常处理问题。
云主机网络状态检查
网络组之前已经在云主机内部加入了自动分析网络状态的定时任务,可以每5分钟分析一次网络配置和连通性,保存检查结果到特定路径,我们打算利用ceilometer+qga+ELK实现云主机网络状态的监控和报警,ceilometer+qga当前已经支持云主机操作系统状态的检查,再加上网络状态检查可以更好的确认云主机运行状态,获取云主机内部网络状态信息后会打印到日志,由ELK收集并处理,方便后续添加相关报警。
Keystone升级M版本
计划先从改动最小的keystone组件入手,调研升级步骤和新版本性能、功能改进情况,其他组件视情况决定是否继续升级。
其他工作
- yun.163.com控制台前端优化(用户+管理员)
- 信息安全相关需求开发
- 节点扩容
- 常规更新
- LXC网络性能问题分析
- 管理员权限安全问题改进方案
- 镜像制作及更新
后续工作
- 大规模集群支持
- 性能优化
- 可靠性增强
- 可用率提升
- 自运维改进
- 降成本
- 用户体验
- 流程优化